Documentation Index
Fetch the complete documentation index at: https://docs.flowx.ai/llms.txt
Use this file to discover all available pages before exploring further.
Available starting with FlowX.AI 5.6.0
Download Attached Files is available starting with FlowX.AI 5.7.0.
Overview
The Web Page Extractor node is a workflow node that collects readable content from web page URLs. It supports static URL lists and dynamic URL generation, configurable crawling depth with link following, and adjustable scrape speed presets.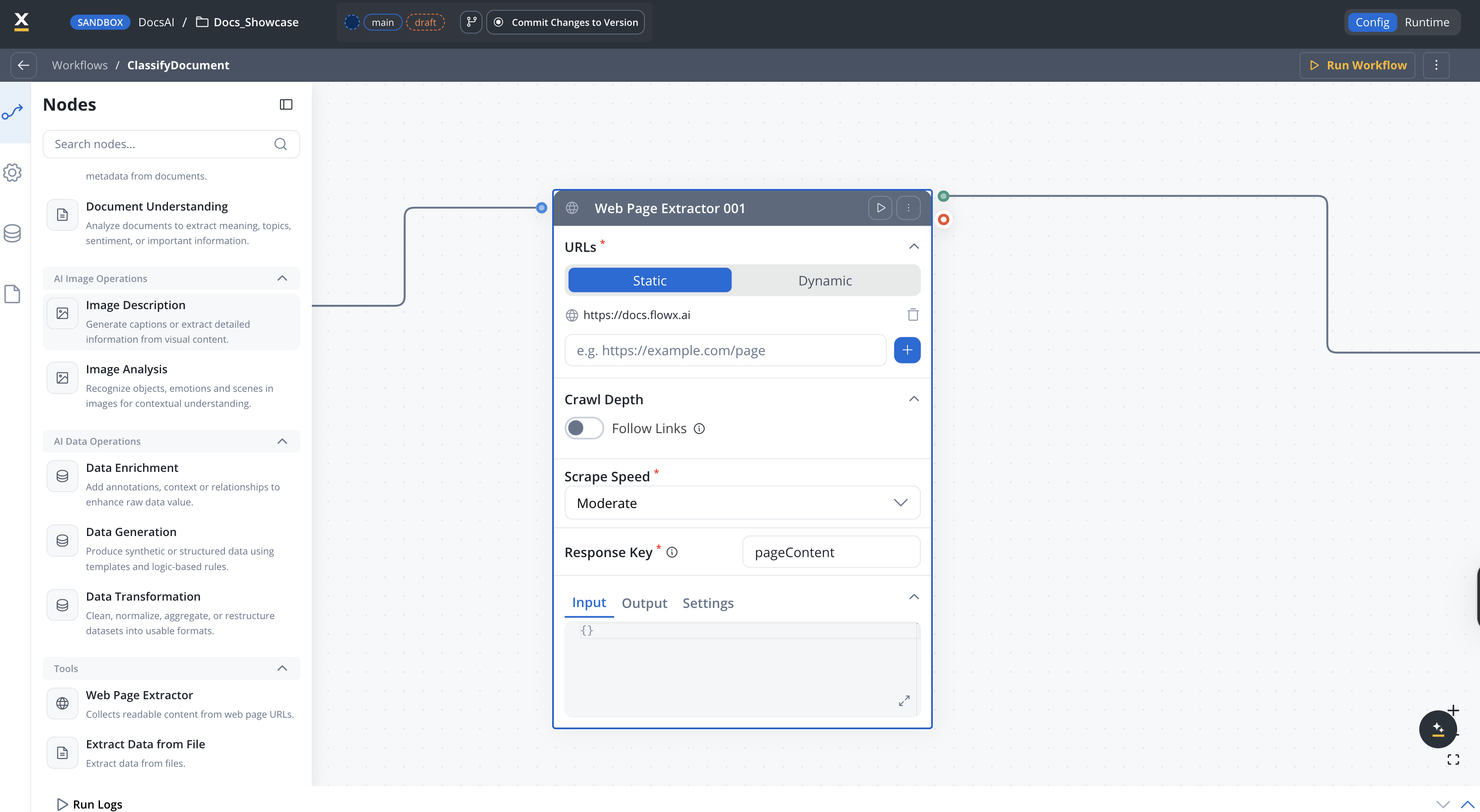
Static or dynamic URLs
Provide a fixed list of URLs or generate them dynamically from workflow data
Link following
Optionally follow links on pages up to a configurable depth
PDF processing
Extract content from PDF files linked on the page
Scrape speed control
Choose from speed presets or define custom rate limits and concurrency
File downloads
Download attached files (.docx, .xlsx, .pdf) found during crawling and store them automatically
Configuration
URL source
How URLs are provided to the node.
Default:
| Mode | Description |
|---|---|
| Static | Provide a fixed list of up to 20 URLs |
| Dynamic | Generate URLs from a workflow data key using ${expression} syntax |
StaticList of URLs to extract content from. Only available when URL Mode is
Static.Maximum: 20 URLsURLs must use http:// or https:// protocol. Supports ${variable} placeholders for dynamic values.A workflow data key or expression that resolves to a URL at runtime. Only available when URL Mode is
Dynamic.Example: ${inputData.targetUrl}Crawl depth
When turned on, the extractor follows links found on the page up to the configured depth.Default: OFF
How many levels of links to follow from the starting page. Only applies when Follow Links is turned on.Range: 0–10Default:
0When turned on, extracts content from PDF files linked on the page.Default: OFF
Download attached files
Available starting with FlowX.AI 5.7.0
When turned on, files discovered during crawling are downloaded and stored automatically. Supported file types include
.docx, .xlsx, and .pdf.Default: OFFWhere downloaded files are stored. Only available when Download Attached Files is turned on.
| Option | Description |
|---|---|
| Document Plugin | Store files through the FlowX Document Plugin. Requires Folder Name and Document Type to be configured. |
| S3 Protocol | Store files directly using S3-compatible storage. |
Identifier used to associate the file with its business owner. Only available when Download Attached Files is turned on and Document Destination is
Document Plugin.Metadata describing the business value of the file. Only available when Download Attached Files is turned on and Document Destination is
Document Plugin.Scrape speed
Controls how aggressively the node requests pages from the target server.
Default:
| Preset | Description |
|---|---|
| Slow | Conservative rate limiting — best for fragile or rate-limited servers |
| Moderate | Balanced speed and reliability |
| Fast | Aggressive crawling — assumes the target server can handle high traffic |
| Custom | Define your own rate limit and concurrency |
ModerateMaximum requests per second. Only available when Scrape Speed Preset is
Custom.Default: 2Number of concurrent requests. Only available when Scrape Speed Preset is
Custom.Default: 3Response key
The key where extracted content is stored in the workflow data.Example:
extractedContentTimeout and retry
Request timeout in milliseconds. If the extraction exceeds this duration, the node fails.
Optional retry strategy for failed requests.
| Field | Description | Default |
|---|---|---|
| Retry Type | Fixed or Exponential backoff | — |
| Max Attempts | Maximum retry attempts | 2 |
| Backoff Period | Delay between retries (ms) | 1000 |
| Max Backoff Period | Maximum delay for exponential backoff (ms) | 120000 |
| Backoff Multiplier | Multiplier for exponential backoff | 2 |
Best practices
Start with Moderate speed
Use the Moderate preset unless you know the target server’s capacity. Switch to Fast only for internal or robust servers.
Limit crawl depth
Keep Max Depth low (1–3) to avoid excessive page requests. Deep crawls can be slow and may trigger rate limiting.
Use dynamic URLs for runtime flexibility
When the target URL comes from user input or a previous workflow step, use Dynamic mode with
${expression} placeholders.Set timeouts for external sites
Always configure a timeout when crawling external websites to avoid blocking the workflow on slow or unresponsive servers.
Related resources
Extract Data from File
Extract text and data from documents and images
AI node types
Overview of all AI workflow node types
Integration Designer
Build and manage integration workflows