Documentation Index
Fetch the complete documentation index at: https://docs.flowx.ai/llms.txt
Use this file to discover all available pages before exploring further.
Available starting with FlowX.AI 5.7.0
Overview
The Speech to Text node is a workflow node that converts between audio and text. It supports two operations: Transcribe converts audio files into text, and Text to Speech converts text into audio files. The node integrates with the FlowX Document Plugin for file storage and works in both standard and conversational workflows.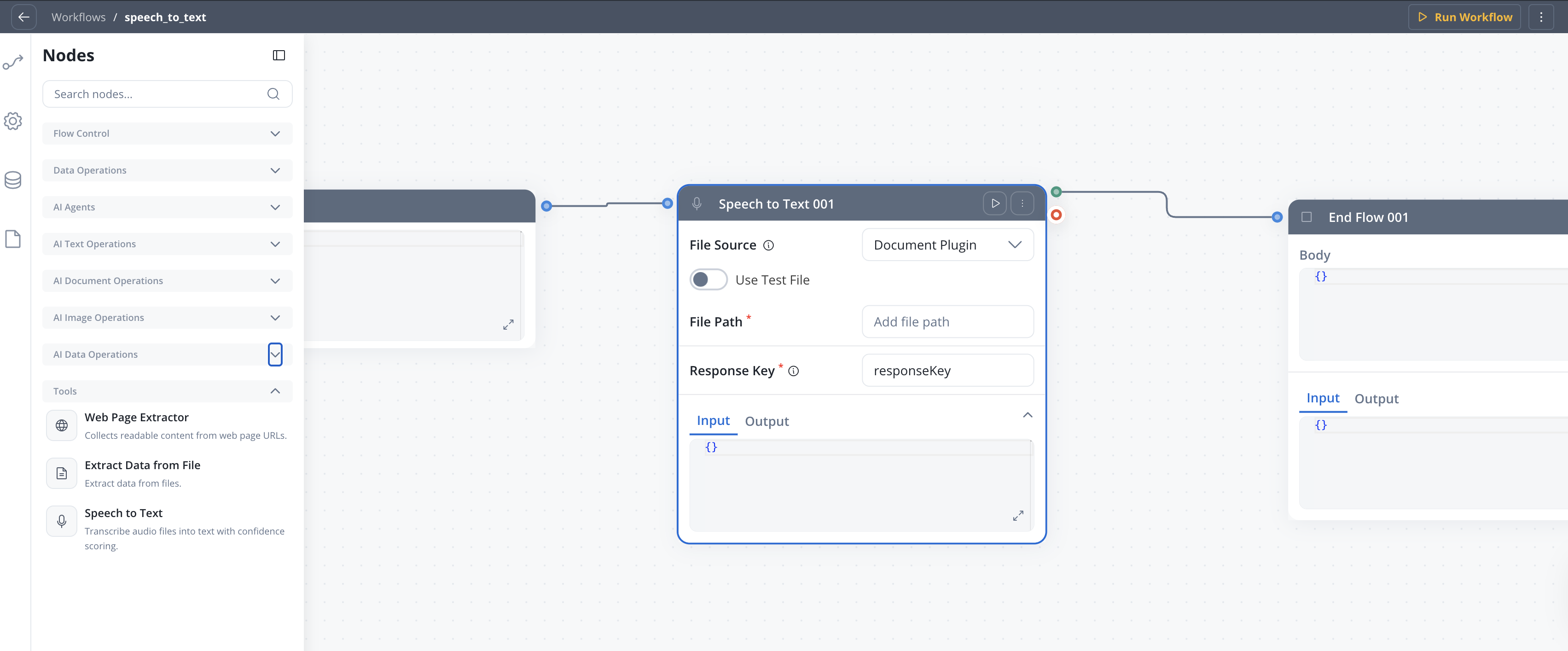
Transcribe audio
Convert audio recordings to text with language detection and confidence scores
Text to speech
Generate audio files from text with configurable voice, speed, and format
Multiple file sources
Read audio from Document Plugin, S3, or directly from chat voice input
Chat integration
Automatically processes voice messages in conversational workflows
Configuration
Operation
The conversion direction.
Default:
| Operation | Description |
|---|---|
| Transcribe | Convert an audio file to text |
| Text to Speech | Convert text to an audio file |
TranscribeTranscribe
Converts audio files into text. The node reads audio from a configured source, sends it to the speech-to-text service, and returns the transcript along with language detection and confidence metadata.File source
Where the audio file is located.
In conversational workflows, the file source is set to Chat Input automatically.
| Source | Description | Availability |
|---|---|---|
| Document Plugin | Read audio from a file stored in the FlowX Document Plugin | Standard workflows |
| S3 Protocol | Read audio from S3-compatible storage | Standard workflows |
| Chat Input | Automatically receive audio from a voice message in the chat UI | Conversational workflows only |
Path to the audio file in Document Plugin or S3 storage. Supports
${expression} placeholders for dynamic values.Only available when File Source is Document Plugin or S3 Protocol.Example: ${inputData.audioFilePath}Supported audio formats
| Format | MIME Type |
|---|---|
| MP3 | audio/mpeg |
| WAV | audio/wav |
| M4A | audio/x-m4a |
| AAC | audio/aac |
| OGG | audio/ogg |
File size limits
| Workflow type | Maximum size |
|---|---|
| Conversational | 5 MB |
| Standard | 10 MB |
Test files
Toggle Use Test File to upload a sample audio file for testing the node without a live file source. Test files support the same audio formats listed above, with a maximum size of 15 MB.Transcribe output
The node writes the transcript and metadata under the configured Response Key. Standard workflows output nested under the response key:| Field | Type | Description |
|---|---|---|
transcript / userMessage | string | The transcribed text |
language | string | Detected language code (e.g., en, fr, de) |
confidence / userMessageConfidence | number | Confidence score (0.0 to 1.0) |
responseTime | number | Processing time in seconds |
audioFileName | string | Original audio file name |
Text to Speech
Converts text into an audio file. The generated audio is uploaded to the Document Plugin, and the node returns the file path and name.TTS configuration
The text to convert to speech. Supports
${expression} placeholders.Example: ${processData.responseMessage}The voice to use for audio generation.Refer to your AI provider’s documentation for available voice options.
The TTS model to use.Refer to your AI provider’s documentation for available models.
The audio output format.Common formats:
mp3, wav, aac, oggPlayback speed multiplier for the generated audio.Range: 0.25 - 4.0Default:
1.0Additional instructions for the TTS model to control tone, style, or emphasis.
TTS output
The generated audio file is uploaded to the Document Plugin. The node writes the file reference under the configured Response Key:| Field | Type | Description |
|---|---|---|
audioFilePath | string | Path to the generated audio file in Document Plugin |
audioFileName | string | Generated file name |
Response key
The key where the node output is stored in the workflow data.Example:
speechResultConversational workflow integration
In conversational workflows, the Speech to Text node works with the Chat component voice input feature:- A user records a voice message in the chat UI
- The audio file is sent to the workflow as a chat input
- The Speech to Text node (with Chat Input file source) transcribes the audio
- The transcript is set as the
userMessage, making it available to downstream nodes (Custom Agent, Intent Classification) as if the user had typed it
When processing chat voice input, the audio file metadata is preserved in the conversation context. This allows conversation history to reference which messages originated from voice input.
Node connections
The Speech to Text node has two output handles:| Handle | Description |
|---|---|
| Success | The operation completed and output is available under the response key |
| Fail | The operation failed (unsupported format, file not found, service error) |
Best practices
Match file source to workflow type
Use Chat Input for conversational workflows and Document Plugin or S3 for standard workflows.
Keep audio files within size limits
Audio files exceeding the size limit (5 MB conversational, 10 MB standard) will fail. Validate file size before reaching the node if the source is user-provided.
Use test files during development
Upload a sample audio file to validate your workflow configuration before connecting to a live source.
Handle failures
Always connect the Fail handle to a fallback path, especially when processing user-uploaded audio that may be in an unsupported format.
Related resources
Chat component
Voice input and conversational UI for chat-based workflows
Conversational workflows
Build multi-turn conversations with AI Triggers and context
AI node types
Overview of all AI workflow node types
Integration Designer
Build and manage integration workflows