Documentation Index
Fetch the complete documentation index at: https://docs.flowx.ai/llms.txt
Use this file to discover all available pages before exploring further.
Available starting with FlowX.AI 5.6.0The “Extract Text from Document” node has been renamed to Extract Data from File and now supports image inputs, configurable extraction methods, image extraction options, and signature detection.
Overview
The Extract Data from File node extracts text and structured data from documents and images within Agent Builder workflows. It supports multiple extraction strategies so you can balance accuracy, speed, and cost based on your document types.Supported file formats
| Category | Formats |
|---|---|
| Documents | PDF, DOCX, XLSX, XLS, XLSM, PPTX |
| Images | JPG, PNG, TIFF |
Image files are automatically converted to PDF before processing. This conversion is handled by the Document Parser service.
Configuration
To add the node to an Agent Builder workflow: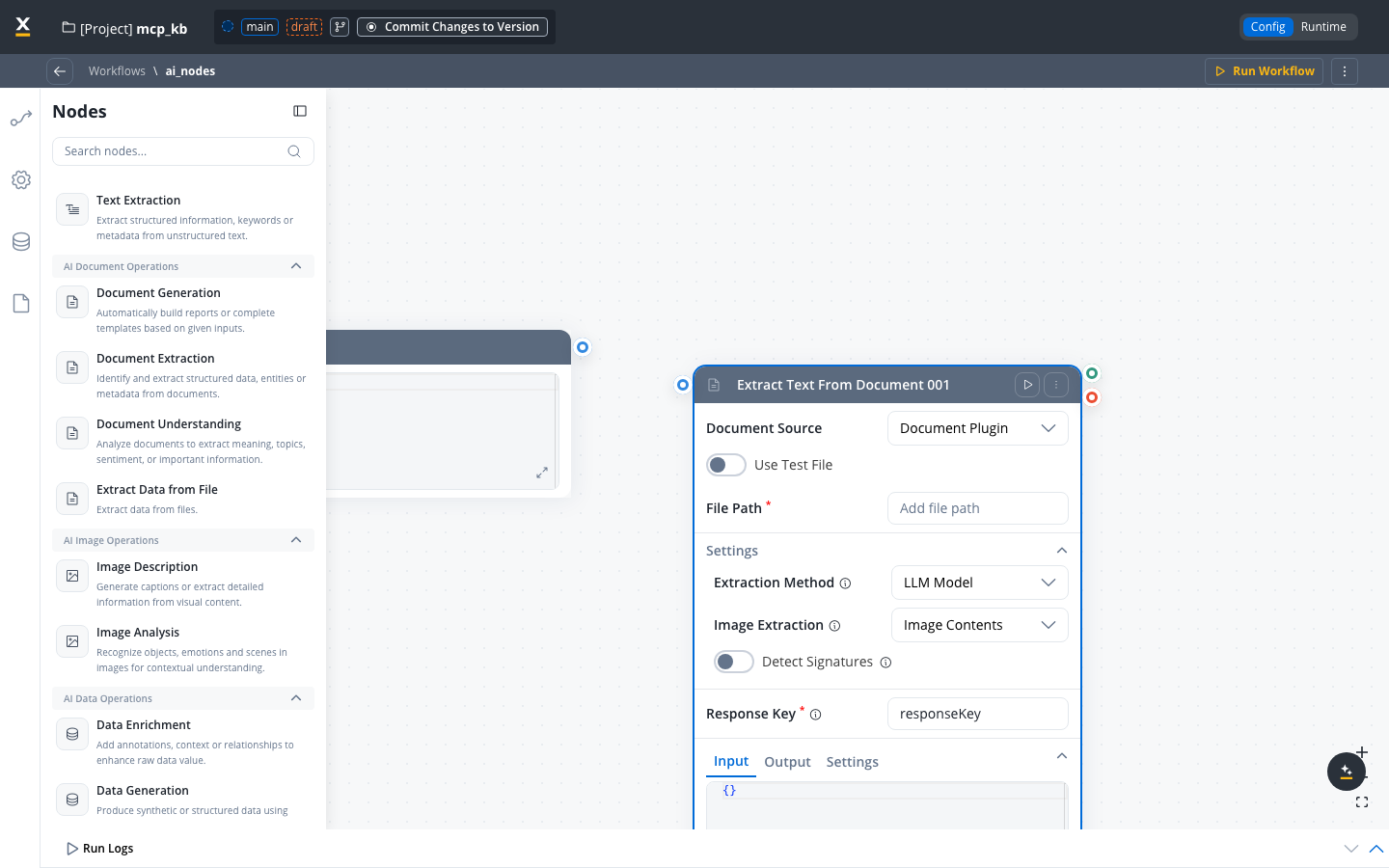
Document source
The source system for the document. Select Document Plugin to use files stored in the FlowX Documents Plugin.Default:
Document PluginUse test file
Toggle ON to use a test file during workflow configuration and testing, without requiring a live file path from process data.Default: OFF
File path
The path to the input file to process. This can reference a file stored in the Documents Plugin.
Response key
The key where the extraction results are stored in the workflow data.Example:
extractedDataExtraction method
Select the method used to extract content from the file. Each method has different accuracy, speed, and cost characteristics.
| Method | Best for | Speed | Cost | Accuracy |
|---|---|---|---|---|
| LLM Model | Complex layouts, handwritten text, mixed content | Slow | High | High |
| OCR Engine | Scanned documents, image-heavy files | Medium | Medium | Medium |
| Text Parsing | Clean digital PDFs with selectable text | Fast | Free | Low–Medium |
- LLM Model
- OCR Engine
- Text Parsing
Uses AI vision models (such as GPT-4o) to analyze document content. This strategy provides the highest accuracy and can handle:
- Complex page layouts with multiple columns
- Handwritten text and annotations
- Mixed content (text, tables, images on the same page)
- Documents with non-standard formatting
Image extraction options
When using LLM Model or OCR Engine, you can configure how images found within the document are handled.Select how images embedded in the document should be processed.
| Option | Description | When to use |
|---|---|---|
| Image Description | Generates a text description of images | When you need to understand what images depict (charts, photos, diagrams) |
| Image Contents | Extracts text and data from images | When images contain text, tables, or data you need to capture |
LLM Model supports both Image Description and Image Contents. OCR Engine supports only Image Contents.
Image extraction options are not available when using the Text Parsing strategy, since Text Parsing only handles selectable text content.
Signature detection
Turn on detection of signatures within the document.Default: OFFWhen enabled, the node identifies areas of the document that contain signatures and includes their locations in the extraction results.
Signature detection is only available when using LLM Model or OCR Engine strategies. It is not available for Text Parsing.
Examples
Processing a scanned invoice
Processing a scanned invoice
Scenario: Extract line items and totals from a scanned paper invoice.Configuration:
- Extraction Method: OCR Engine
- Image Extraction: Image Contents
- Detect Signatures: ON (to capture the approval signature)
Analyzing a contract with charts
Analyzing a contract with charts
Scenario: Extract text and understand visual elements from a contract that includes charts and diagrams.Configuration:
- Extraction Method: LLM Model
- Image Extraction: Image Description
- Detect Signatures: OFF
Extracting text from a clean PDF
Extracting text from a clean PDF
Scenario: Extract text from a digitally generated report PDF.Configuration:
- Extraction Method: Text Parsing
- Image Extraction: N/A (not available for Text Parsing)
- Detect Signatures: N/A (not available for Text Parsing)
Best practices
Start with Text Parsing
For digital PDFs, try Text Parsing first. Only use OCR or LLM if the results are insufficient.
Match strategy to document type
Use OCR for scanned documents, LLM for complex layouts, and Text Parsing for clean digital files.
Consider cost at scale
LLM processing costs increase linearly with page count. For high-volume workloads, use Text Parsing or OCR where possible.
Turn off unused features
Turn off signature detection and image extraction when not needed to reduce processing time and cost.
Related resources
Document Parser setup
Configure the Document Parser service, parsing engines, and deployment sizing
AI node types
Overview of all AI node types available in Agent Builder
Agent Builder overview
Get started with Agent Builder workflows
Use cases
See real-world Agent Builder workflow examples