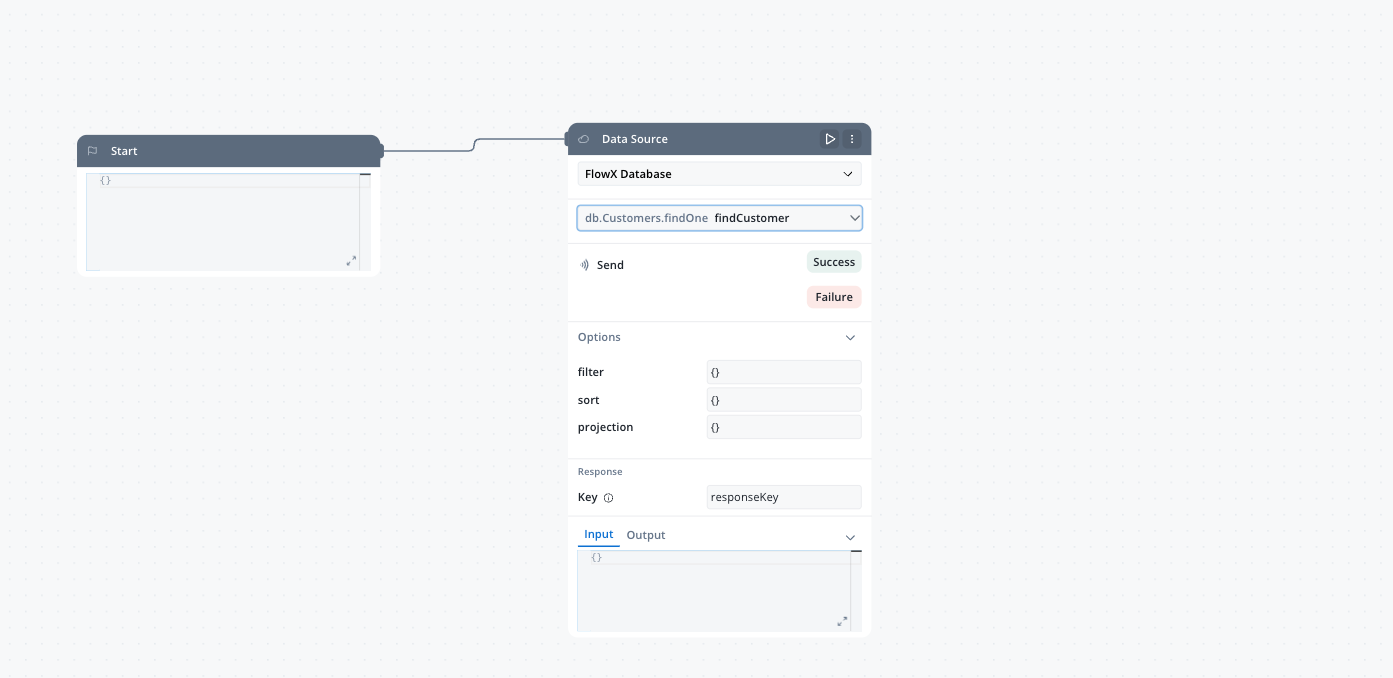
FlowX Database (FlowX DB) is a persistence layer that allows you to store structured data independently of process instances. This enables you to:
Share data between different process instances
Store and retrieve data across multiple processes
Create a persistent data store within the FlowX ecosystem
Access structured data without directly interacting with external systems
FlowX Database is powered by the nosql-db-runner microservice, which provides MongoDB functionality within the FlowX ecosystem. This service supports both native MongoDB and Azure Cosmos DB (MongoDB API), enabling you to choose the database backend that best fits your infrastructure needs while maintaining FlowX’s workflow integration capabilities.For more information about the nosql-db-runner service and CosmosDB considerations, see the NoSQL DB Runner documentation.
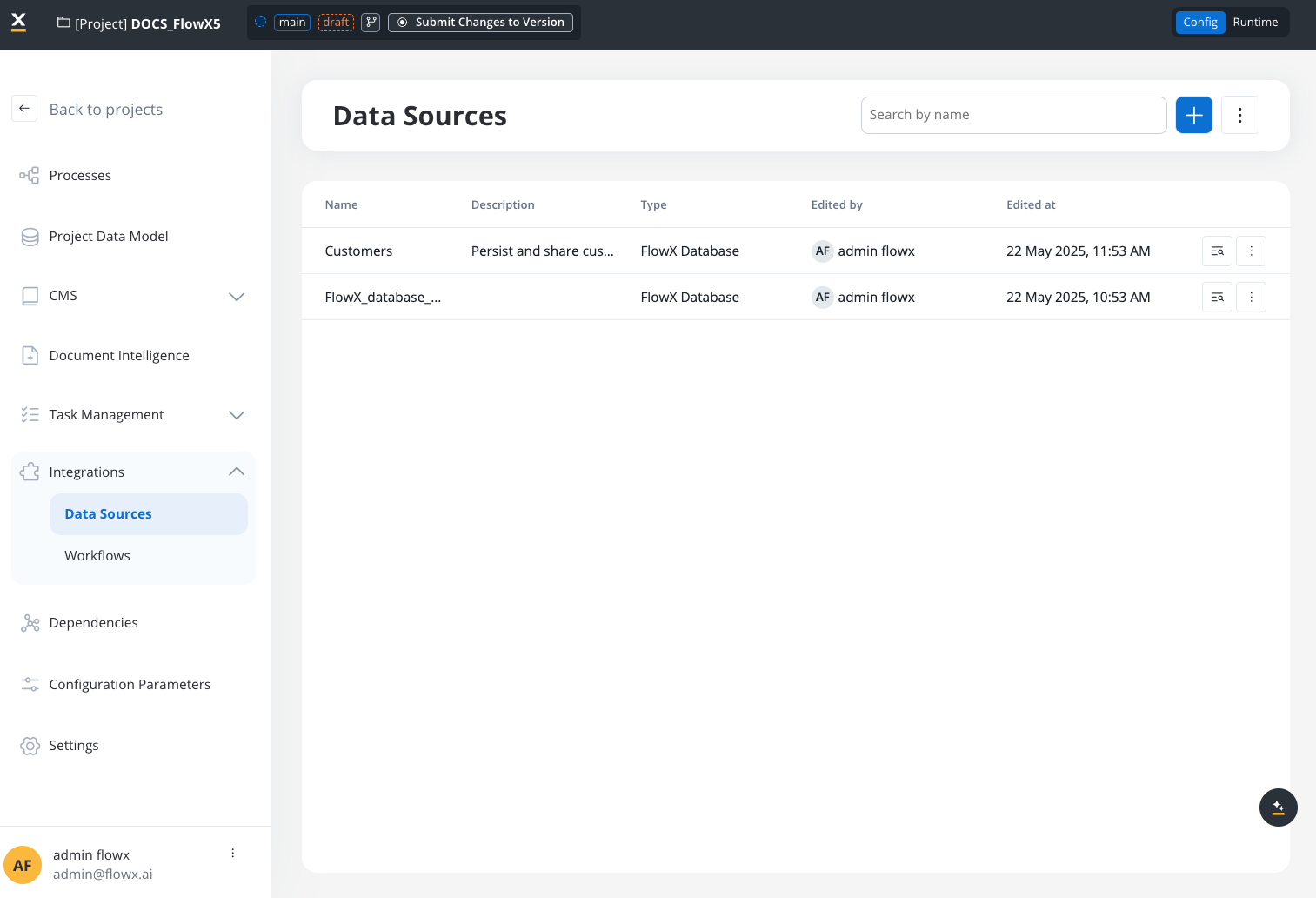
Navigate to the ‘Integrations’ section in the left sidebar of FlowX Designer, then click on ‘Data Sources’.
Accessing Data Sources in the navigation menu
2
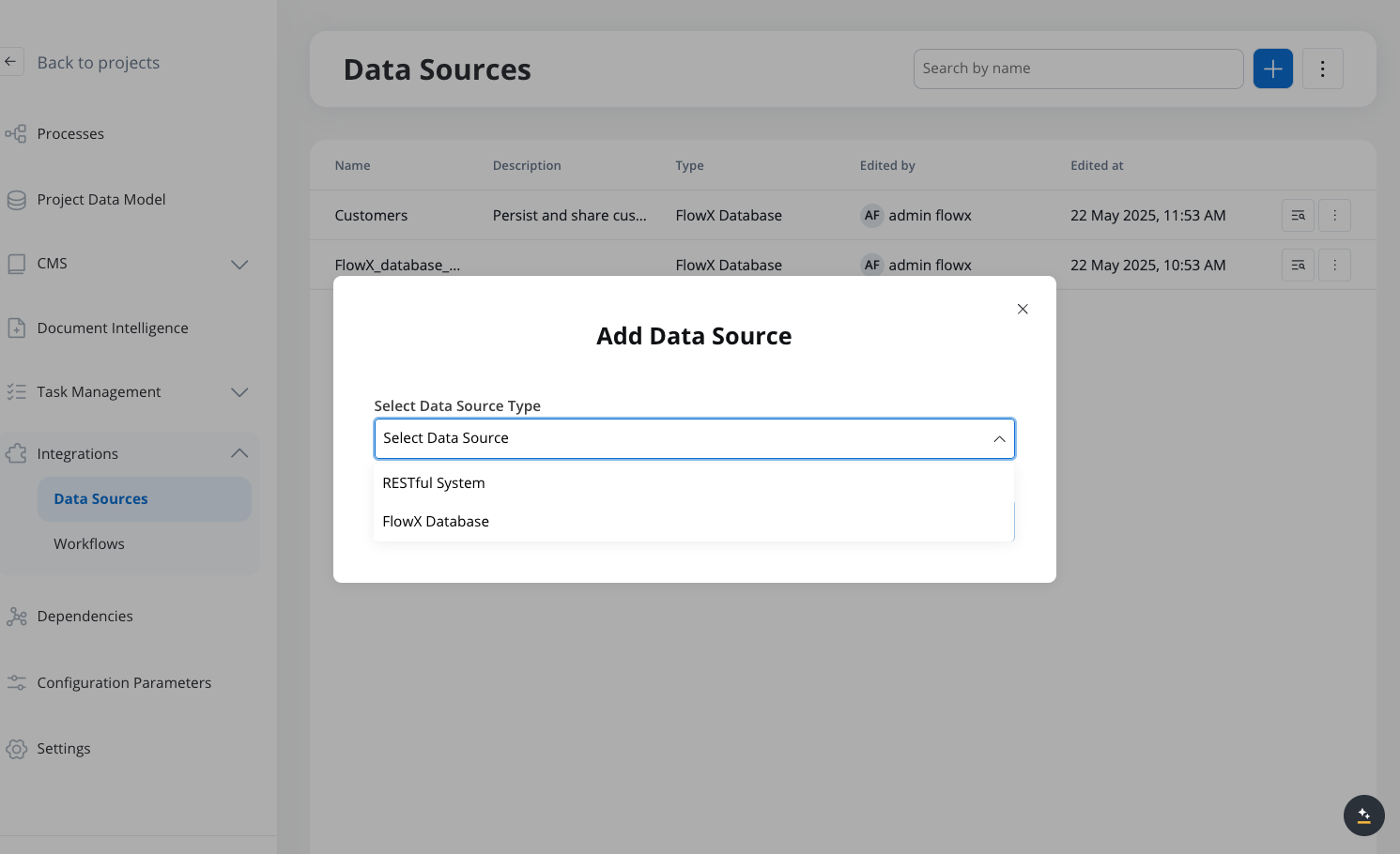
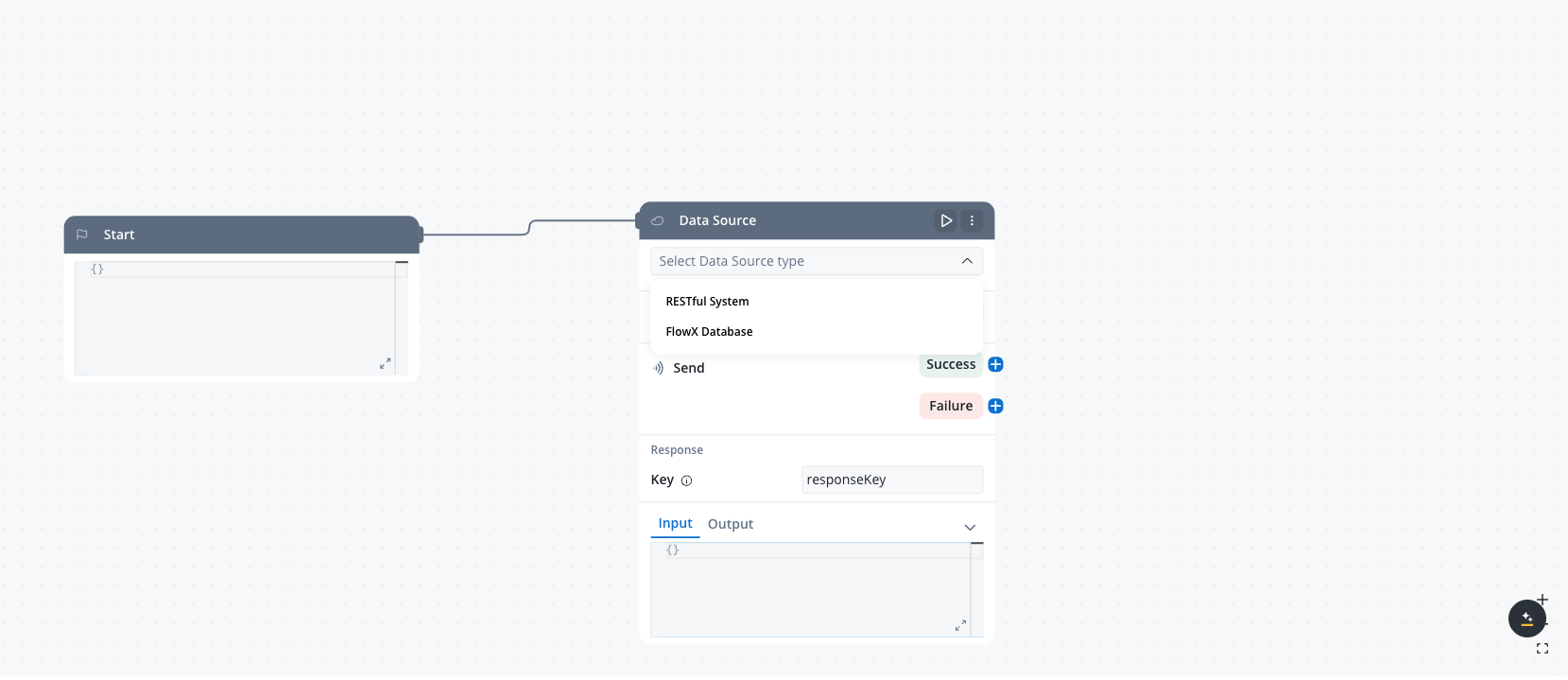
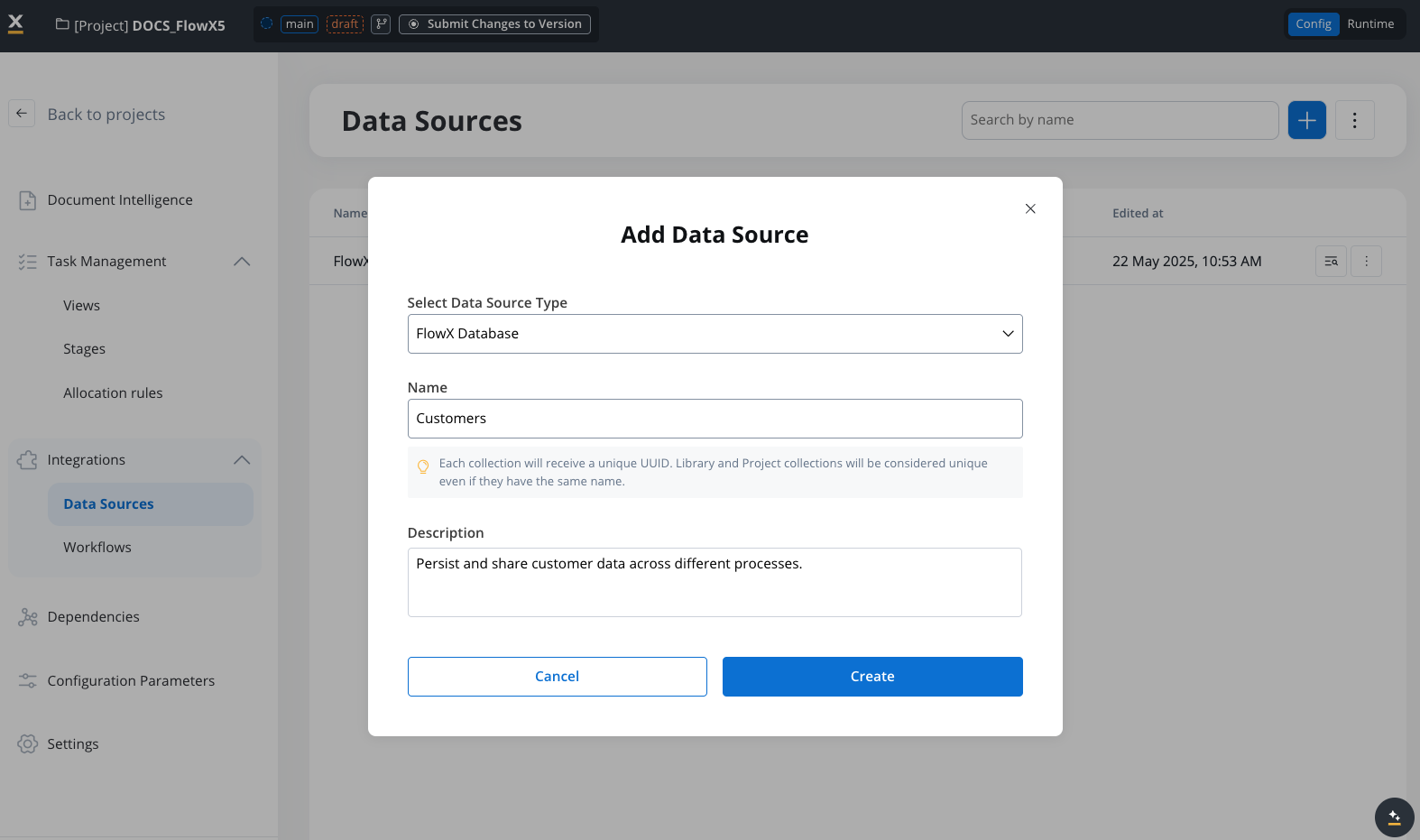
Add a new Data Source
Click the ”+” button to add a new Data Source. In the “Add Data Source” dialog, select “FlowX Database” from the dropdown list.
Adding a new FlowX Database data source
3
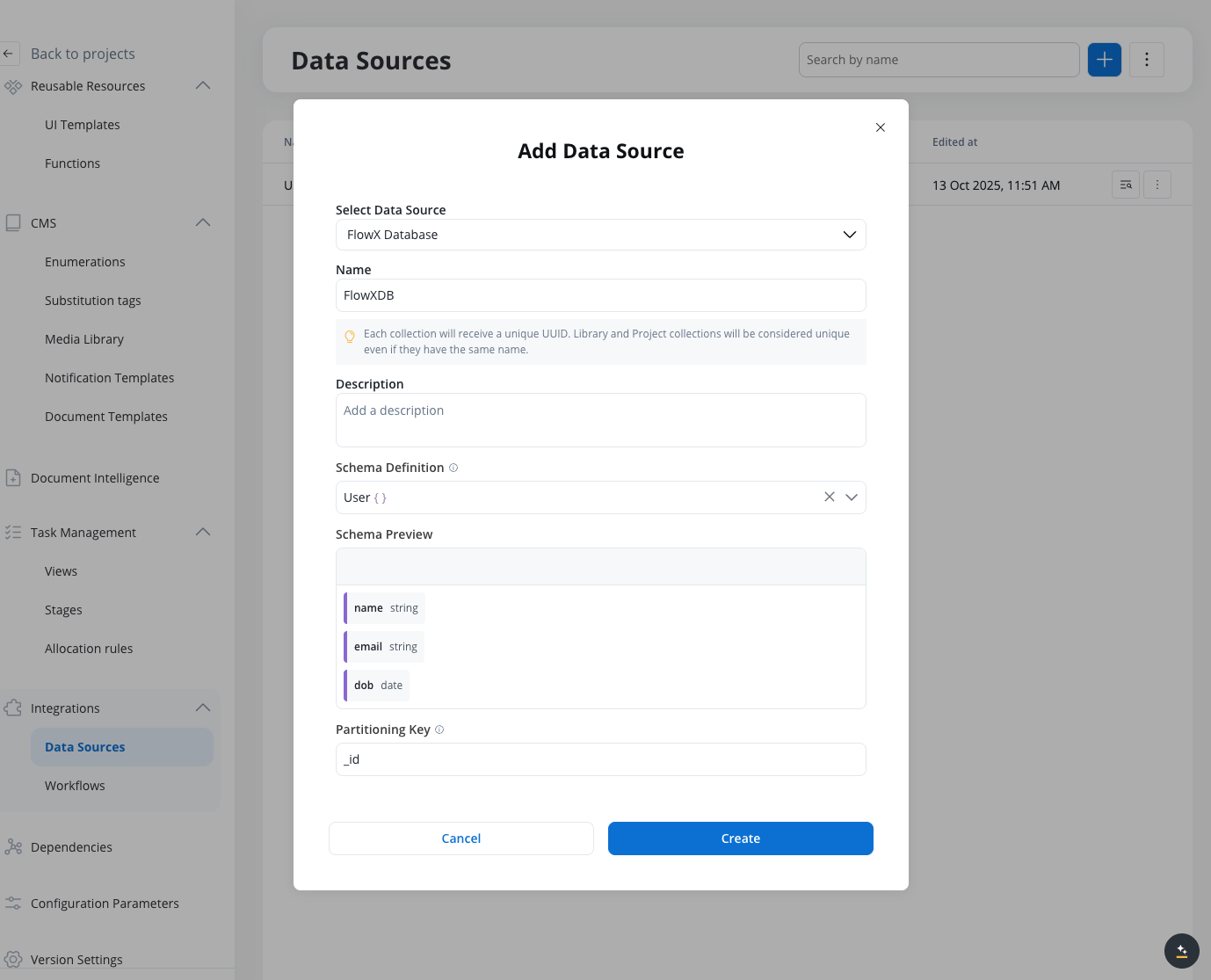
Configure the collection
Provide a name and description for your collection. The name will be used to identify this database collection in your workflows.
Data Model Required: You must have a data model defined before creating a FlowX Database collection. The data model becomes the schema for your database collection and defines the structure of documents that will be stored.
Configuring the collection
Schema Definition: Define the schema for your collection (the selected schema enhances auto-completion but does not enforce validation during insert or update)
Partitioning Key: The attribute used to partition data in your collection. By default, this is set to the id attribute, but you can specify a different field based on your data model.
4
Create the collection
Click “Create” to save the collection in FlowX Database. Your new collection will appear in the Data Sources list with the type “FlowX Database”.
Each FlowX Database data source represents a collection in the underlying MongoDB database. When you create a new data source with the FlowX Database type, you’re essentially creating a new collection where your documents will be stored.
Go to the collection you want to view in the ‘Data Sources’ section.
2
Access Documents tab
Click the ‘Documents’ section within the collection.
3
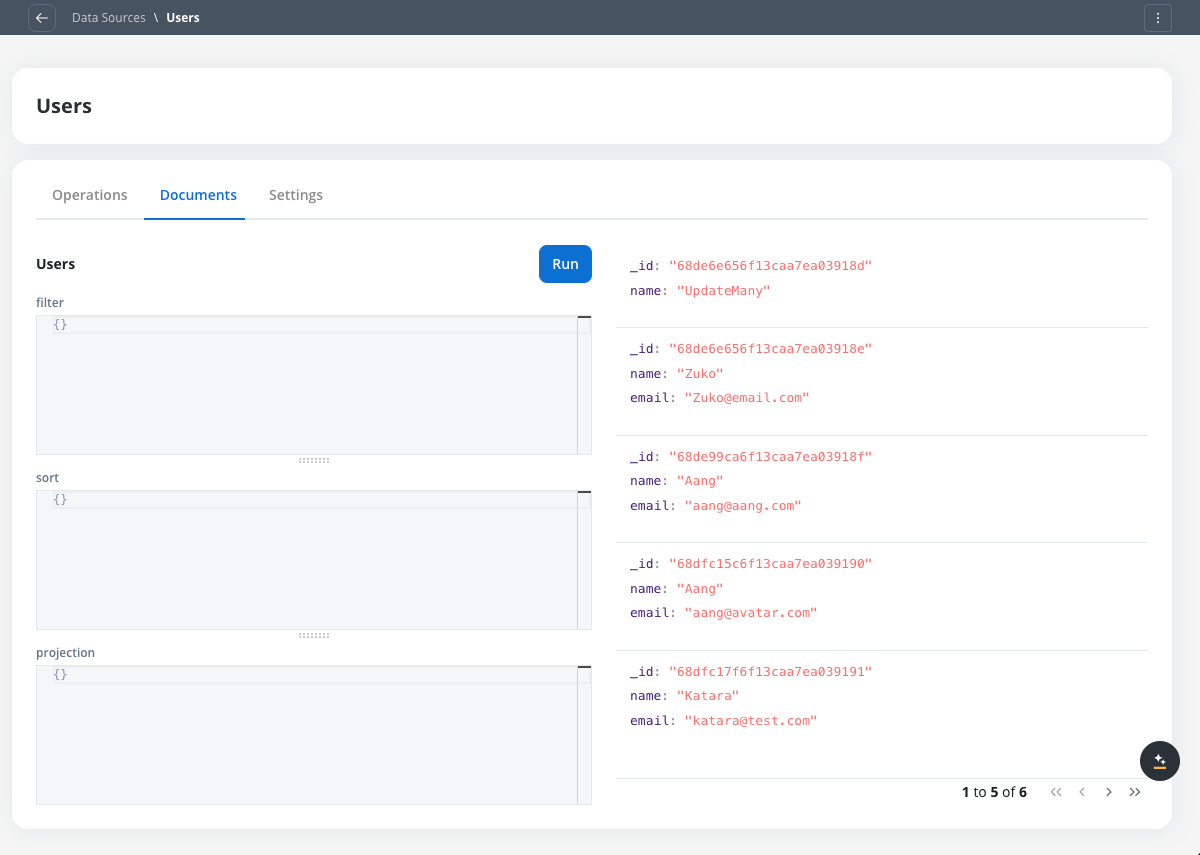
Browse documents
You’ll see a listing of currently saved documents in the collection.
Viewing documents in a FlowX Database collection
4
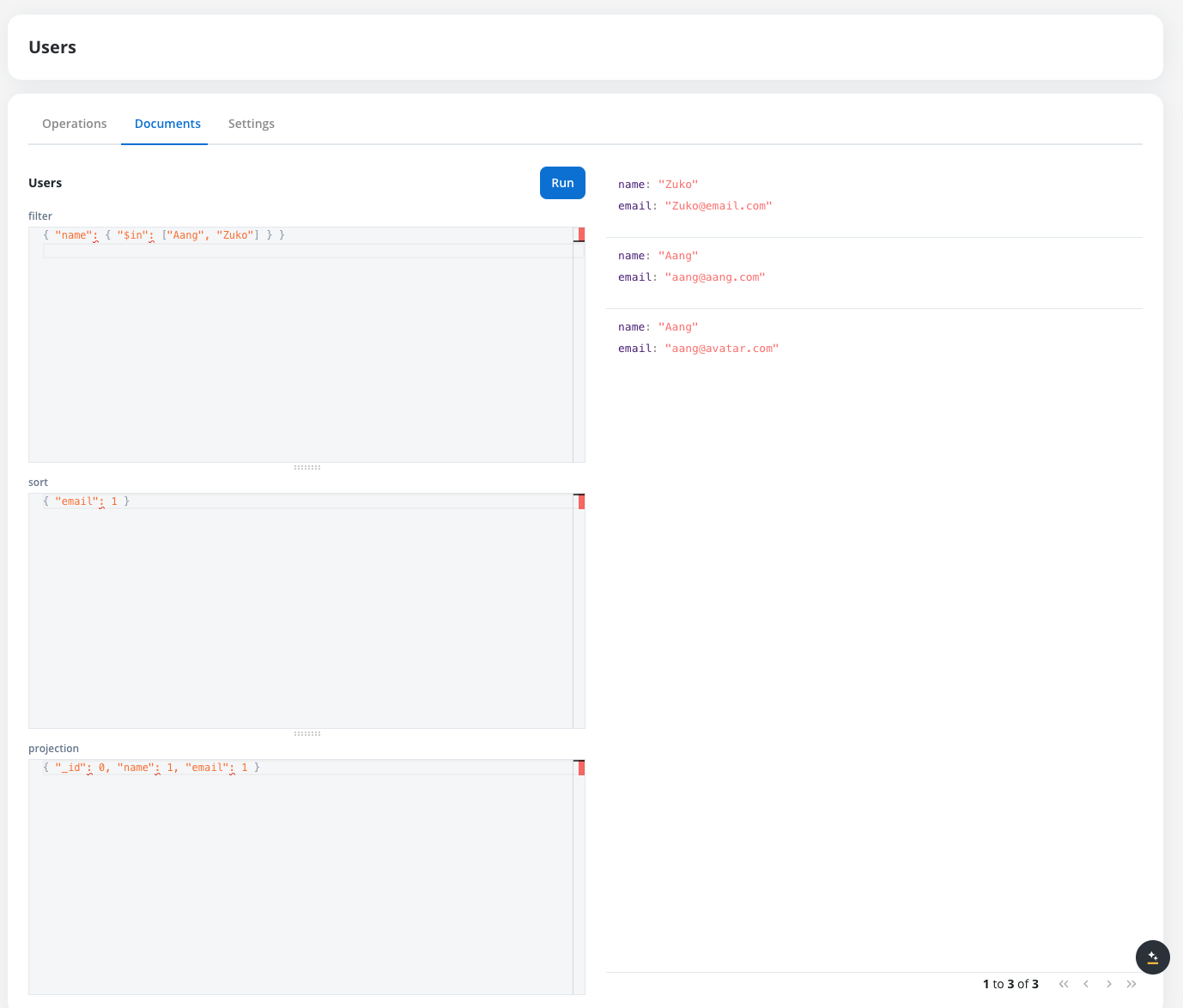
Search and filter
Use the search functionality to find specific documents in the collection. You can add queries to filter documents, sort them, and use projections to choose what content from each entry you want to see.
Searching and filtering documents in a FlowX Database collection
FlowX Database currently relies on MongoDB’s native sorting behavior for query results.
All sorting is performed using MongoDB’s default binary comparison rules.
Each FlowX Database collection has a Settings tab where you can configure performance optimizations:
1
Access Settings tab
Navigate to your collection and click on the ‘Settings’ tab.
2
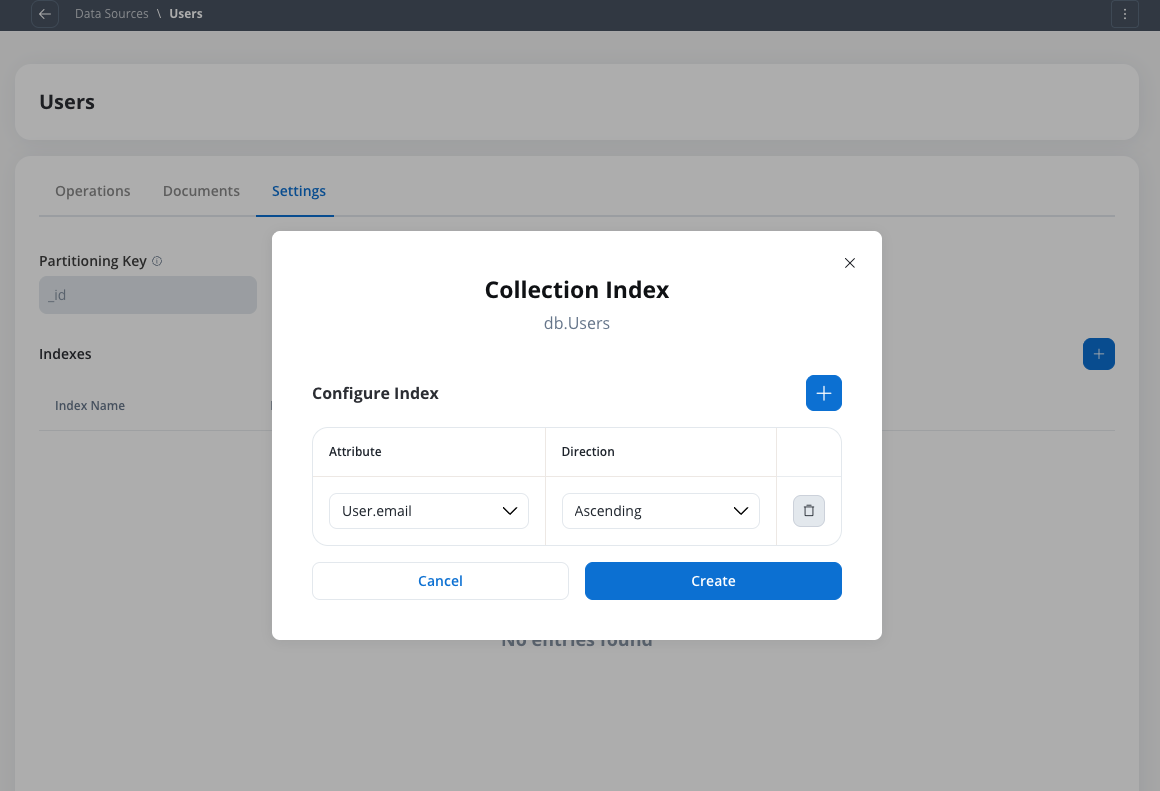
Define indexes
Create indexes for your collection to improve query performance. Indexes are particularly important for large collections as they significantly reduce query execution time.
Create indexes on fields that you frequently use in filter conditions, sort operations, or queries to optimize performance.
Defining indexes for a FlowX Database collection
Defining indexes in the Settings tab saves them as configuration only — they are not applied to the actual MongoDB collection immediately. To apply indexes, you must go to the Runtime view of your project or library, open the Builds section, and select Apply Indexes from the build’s context menu. Only one build per project or library can have indexes applied at a time. Applying indexes on a new build will automatically replace any previously applied indexes that differ.For more details, see Builds.
For large collections with thousands of documents, proper indexing is crucial for maintaining good query performance. Consider indexing frequently queried fields before your collection grows large.
Navigate to your FlowX Database collection in the Data Sources section.
2
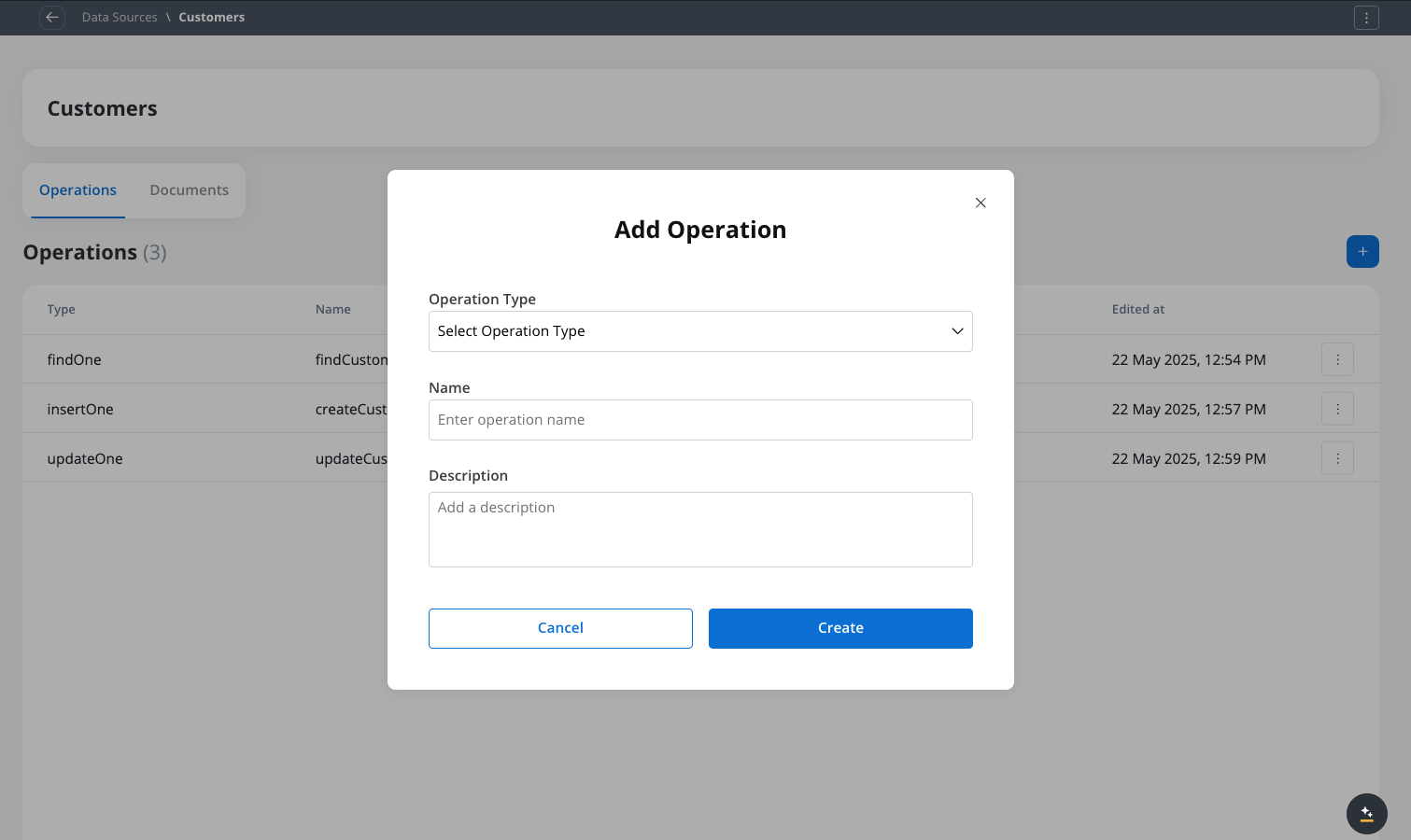
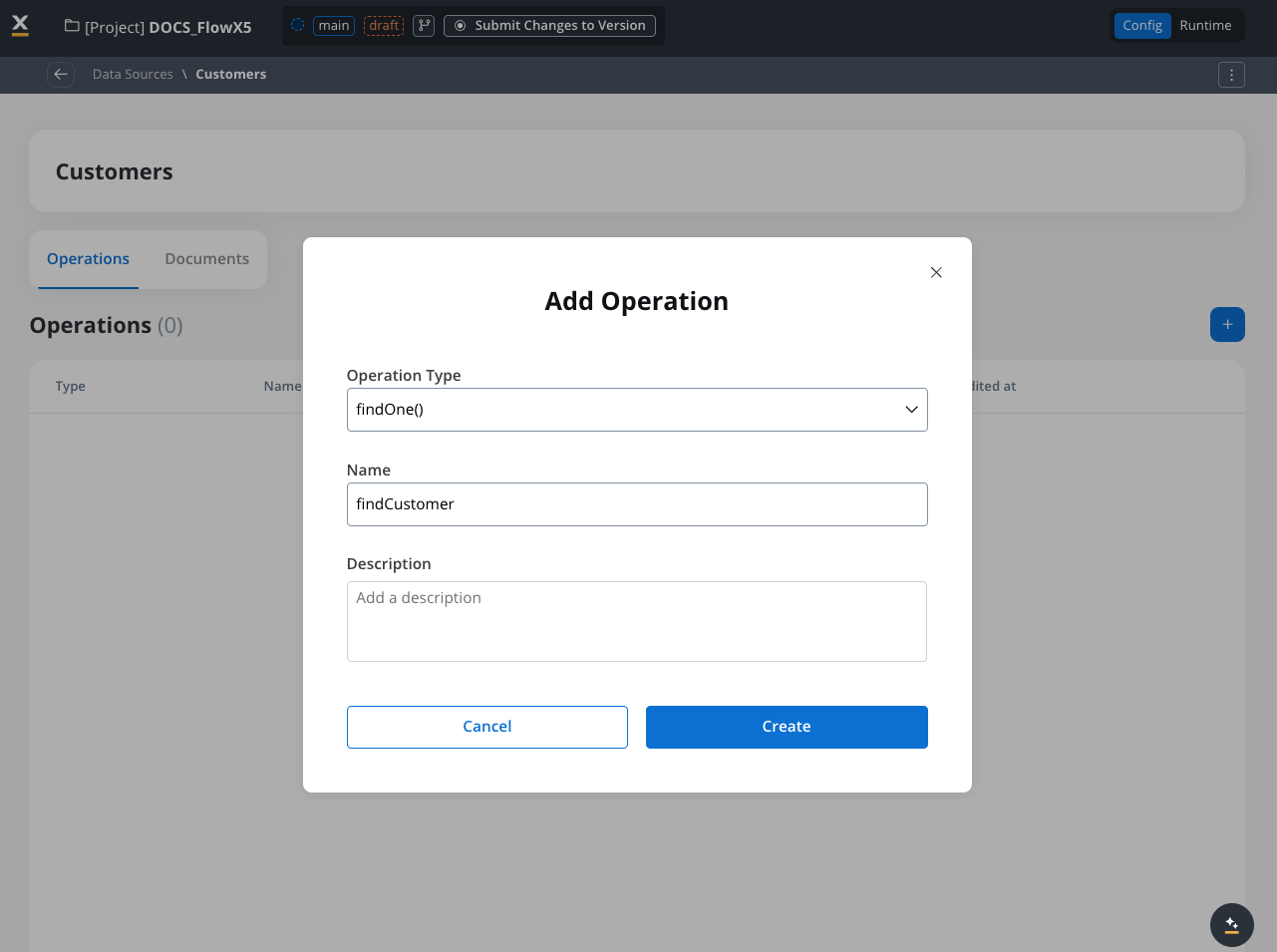
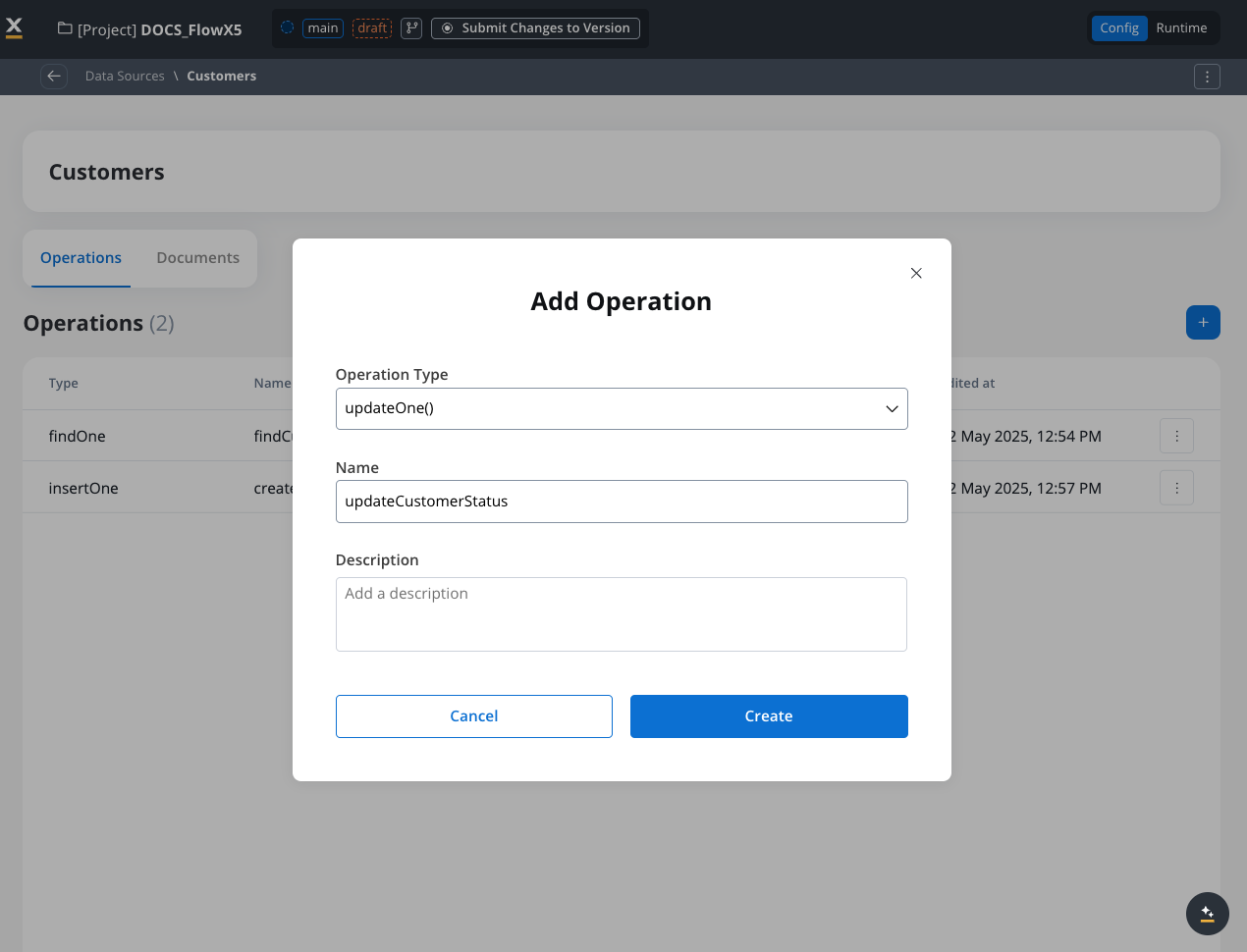
Create new operation
Click the ”+” button to create a new operation.
Creating a new operation for a FlowX Database collection
3
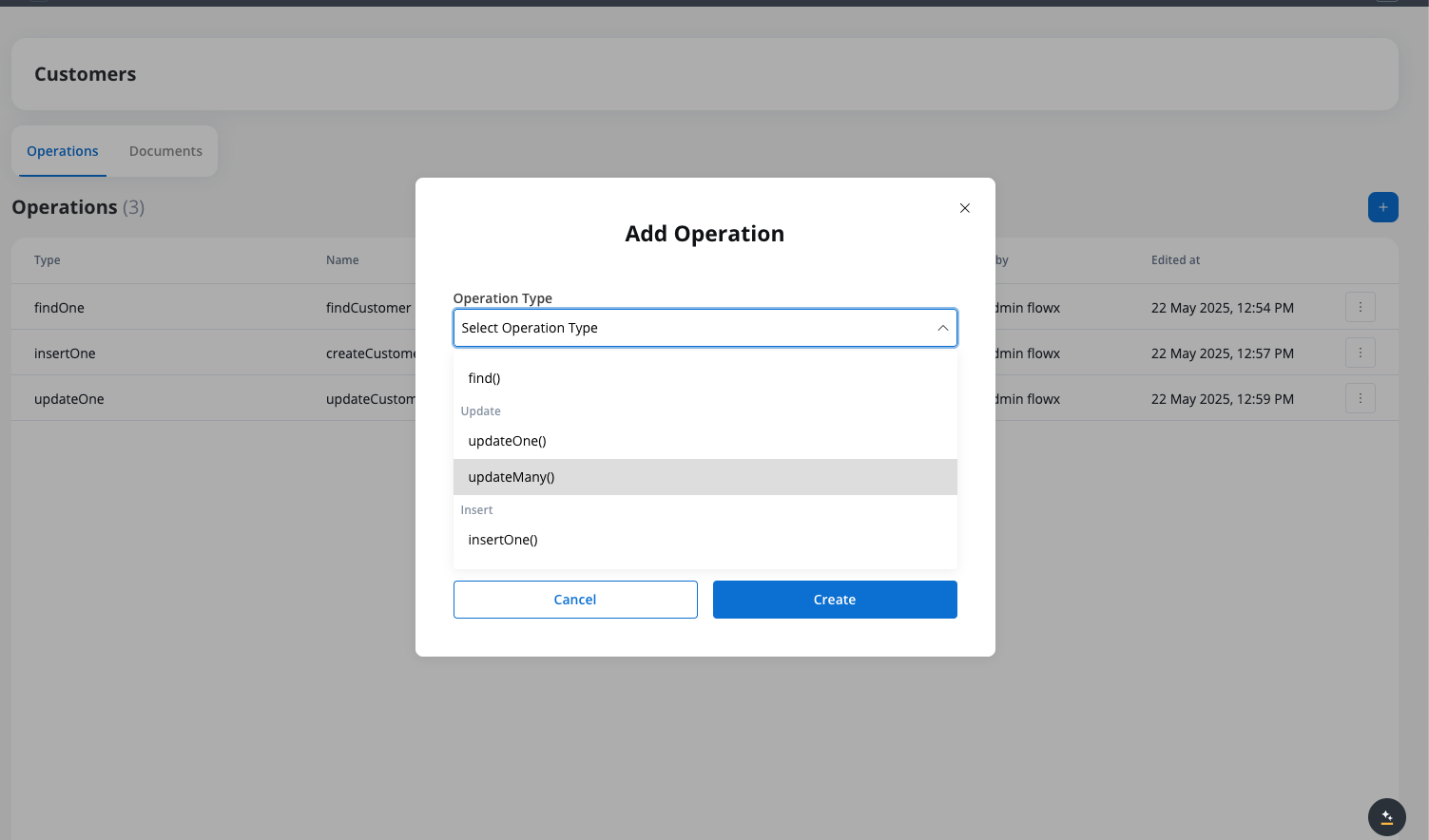
Select operation type
Choose the operation type from the dropdown (find, findOne, insertOne, insertMany, etc.).
Selecting the operation type
4
Name the operation
Give your operation a meaningful name and description that indicates its purpose.
5
Define the operation parameters
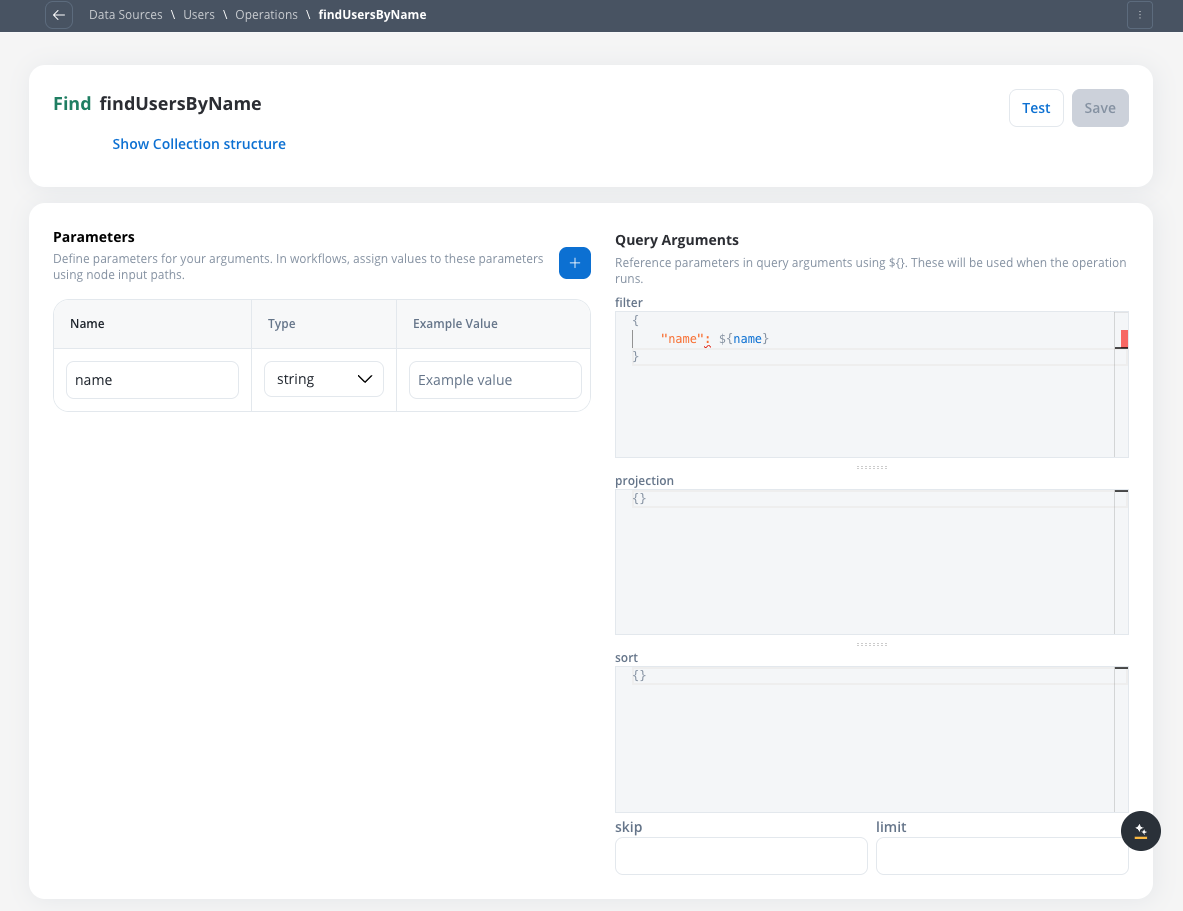
Configure the parameters for your operation based on its type. For example, for a find operation:
Configuring operation parameters
Filter: Define the criteria to match documents
Projection: Select which fields to include in the results
Sort: Specify the sorting order
Skip: For find operations, specify the number of documents to skip
Limit: Set the maximum number of documents to return
Parameter Syntax: When defining operation parameters, remember:
Parameters defined in the operation are referenced using ${parameterName} syntax
Database field names must be in quotes (e.g., "firstName", "customerId")
Parameters don’t need to match your data model exactly - they’re placeholders that get replaced with actual values
Field names in quotes must match exactly what’s stored in the database (same as your data model)
6
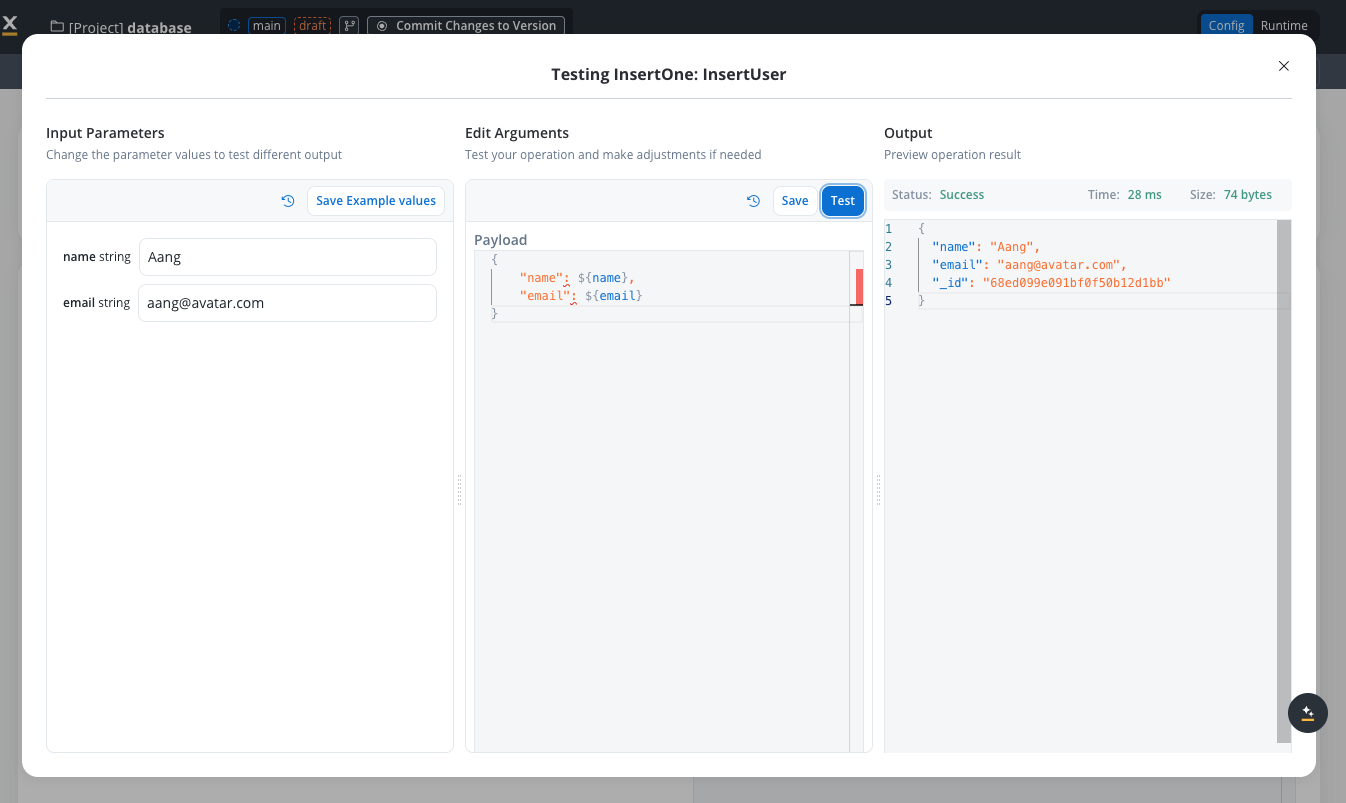
Test the operation
Use the test functionality to verify your operation works correctly.
Testing an operation
Testing Delete Operations: Be extremely careful when testing delete operations (deleteOne and deleteMany) as they will actually remove documents from your collection. Always use test data or ensure you have backups before testing deletion operations in collections with important data.
7
Save the operation
Click “Save” to add the operation to your collection. It will now be available for use in workflows.
1
Select operation
From the list of operations, select the one you want to update.
2
Make changes
Update the operation name, description, or parameters as needed.
3
Test updated operation
Test the updated operation to ensure it works as expected.
4
Save changes
Save your changes to apply them to the operation.
1
Select operation
From the list of operations, select the one you want to delete.
2
Delete operation
Click the delete button and confirm the deletion when prompted.
3
Verify removal
Verify that the operation has been removed from the collection.
Instead of writing raw MongoDB query syntax, you can use the visual query builder to define filters, updates, projections, and sorting through a guided interface that understands your collection’s schema.Each operation type has a tailored builder experience. You can switch between Visual and Script mode at any time using the mode toggle. The two modes work independently — saving in one mode sets that as the active query for the operation.
Switching modes does not sync changes between them. A warning message informs you that saving in the current mode will set it as the final query for the operation.
The core building block of the query builder is the condition row, used in filter sections across all operation types:
Element
Description
Field dropdown
Pick a field from the collection schema. Supports nested paths (e.g., address.city). Shows a data type badge for each field.
Operator dropdown
Type-aware operators that change based on the selected field’s data type (see table below).
Value input
Enter a static value or switch to dynamic mode using ${paramName} syntax. Input type adapts to the field type (text, number, date picker, boolean toggle, enum dropdown).
Remove button
Delete the condition row.
Multiple condition rows can be combined with AND or OR logic using a dropdown selector. AND is the default.
FlowX Database uses MongoDB’s query capabilities through the nosql-db-runner service, providing pure MongoDB functionality. For detailed information about MongoDB query operators, filters, and syntax, refer to the MongoDB Query and Projection Operators documentation.The following MongoDB operations are supported in FlowX Database. Each tab includes practical examples that you can use as a starting point for your own operations.
sort (document, optional): Document specifying the sorting order. See Sort Query Results
skip (integer, optional): Number of documents to skip. See Limit Query Results
limit (integer, optional): Maximum number of documents to return. See Limit Query Results
projection (document, optional): Fields to include or exclude. See Project Fields
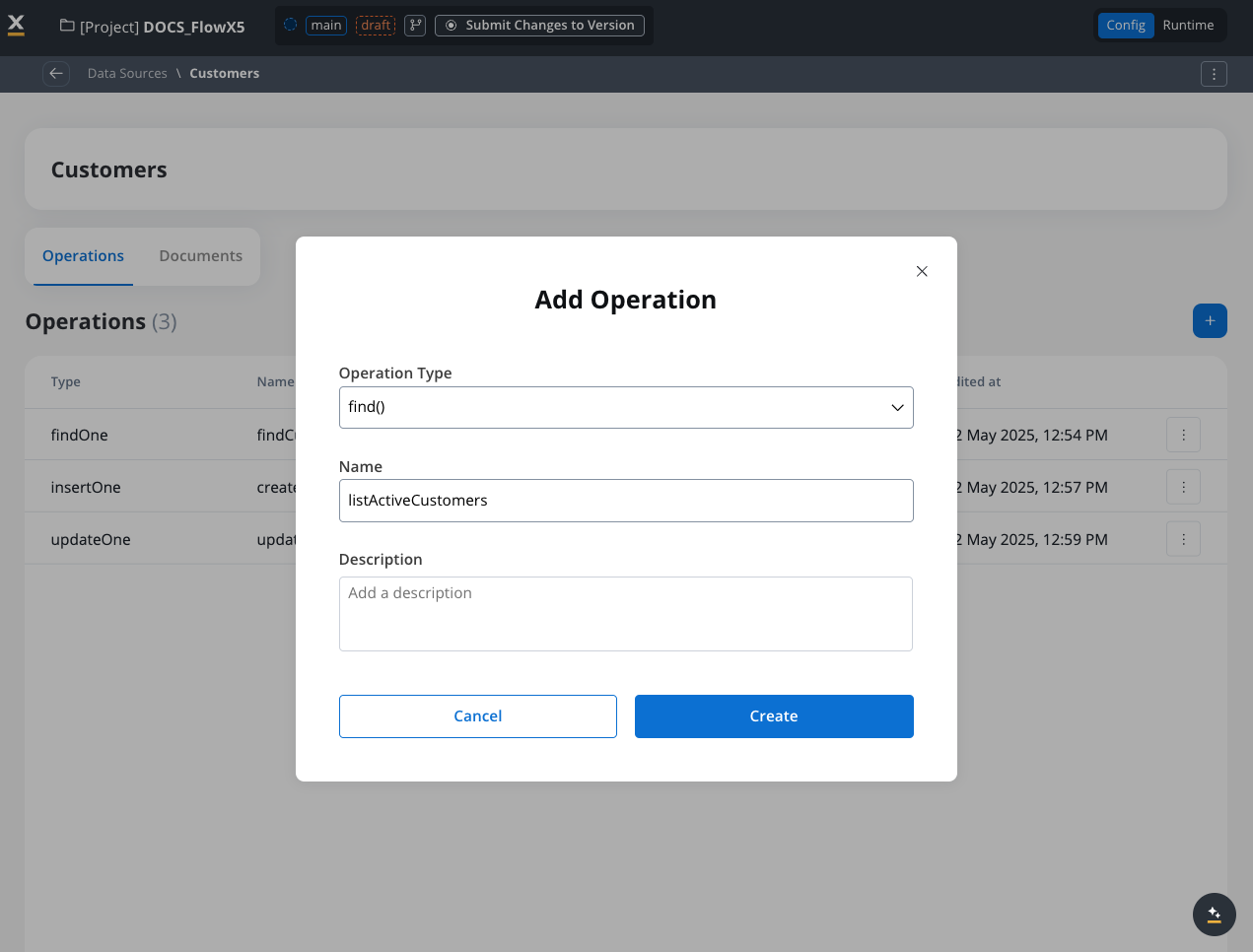
Example: List active customers
This example finds all active customers, sorts them by registration date (newest first), limits to 10 results, and returns only specific fields.Operation name: listActiveCustomers
This operation uses a process variable for the customer ID and returns specific customer fields. Since findOne only returns one document, sort is usually unnecessary unless you need the first document matching certain criteria.
Example: Find latest order
This example finds the most recent order for a customer.Operation name: findLatestOrder
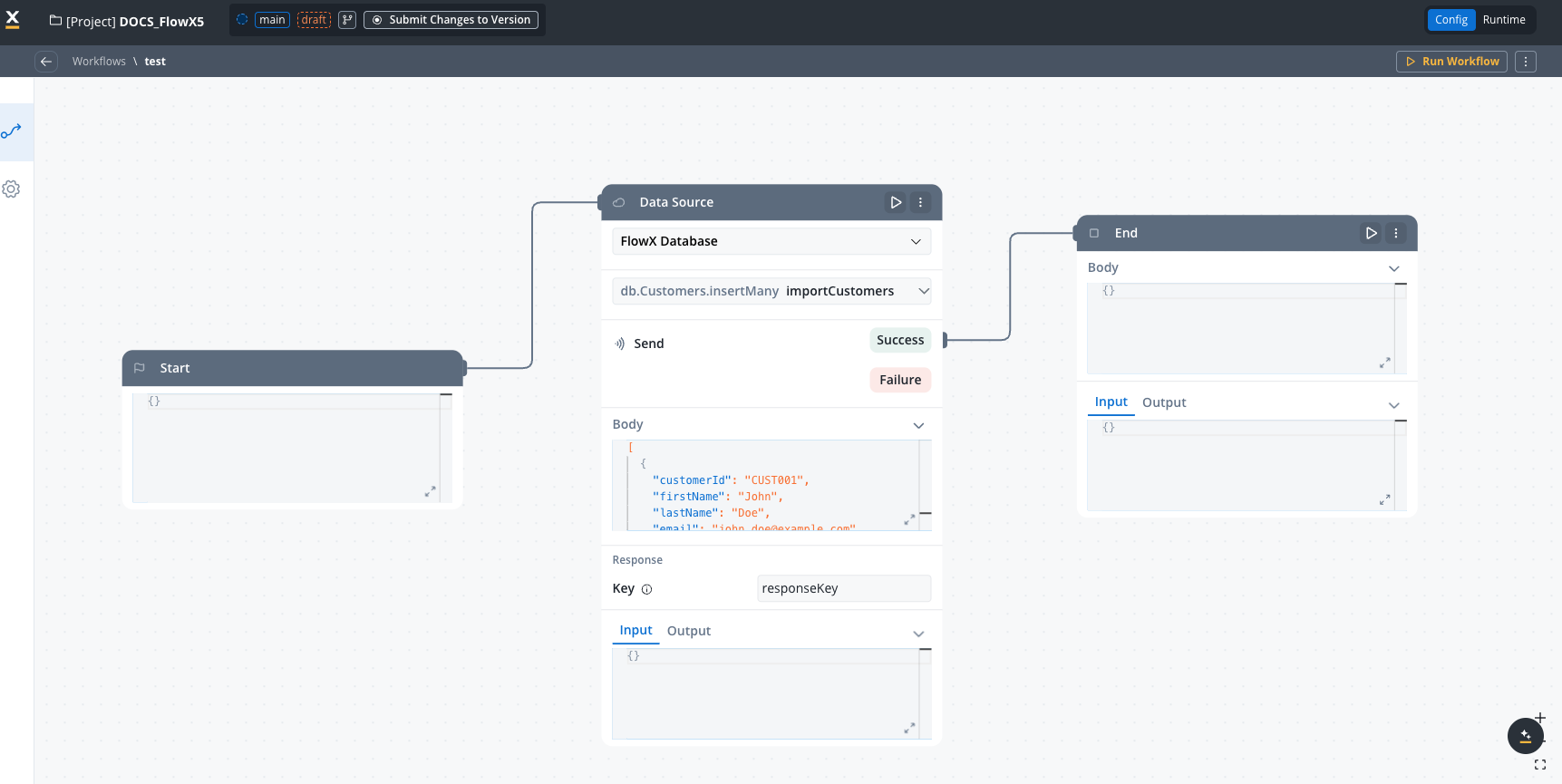
This operation inserts multiple customer records at once. In a real scenario, you would typically reference a process variable containing the array: {processInstance.importedCustomers}
Example: Create order items
This example creates multiple order items for a single order.Operation name: createOrderItems
This operation creates multiple order item records for a single order. In practice, you would use {processInstance.items} directly if your process data model matches the database structure.
filter (document, required): Criteria to match the document to update. See Query Filter Documents
update (document, required): Update operations to apply. See Update Operators
Important Update Behavior: When using update operations without the $set operator, the entire document will be replaced with the new data. This means any fields not included in your update payload will be removed from the document. Always use the $set operator to update specific fields while preserving others.
Example: Update customer status
This example updates a customer’s status and records when the change occurred.Operation name: updateCustomerStatus
This operation updates an order with shipping information, sets the status to “shipped”, and increments a counter tracking the number of status updates.
filter (document, required): Criteria to match documents to update. See Query Filter Documents
update (document, required): Update operations to apply. See Update Operators
Important Update Behavior: When using update operations without the $set operator, the entire document will be replaced with the new data. This means any fields not included in your update payload will be removed from the document.For example, if a document has id, name, and email, and you update only the name field without using $set, the email field will be deleted. Always use the $set operator to update specific fields while preserving others.
Example: Deactivate inactive customers
This example updates the status of multiple customers based on their last activity date.Operation name: deactivateInactiveCustomers
This operation identifies all active customers whose last activity date is older than a threshold date and marks them as inactive.
Key MongoDB Operators: This example uses $lt (less than) for date comparison and $set to update specific fields without affecting other customer data. The $set operator is essential for partial document updates.
Example: Update multiple customers by ID list
This example demonstrates updating multiple specific customers using the $in operator.Operation name: updateCustomersByIdList
This operation updates all customers whose IDs are in the provided list, setting contact information for multiple customers at once.
Standard MongoDB Pattern: The combination of $in for filtering and $set for updating is a standard pattern in MongoDB. Use $in when you need to match against a list of values, and always use $set to avoid replacing the entire document.
Example: Apply discount to products
This example applies a discount to all products in a specific category.Operation name: applySeasonalDiscount
This operation applies a discount to all products in a specific category by multiplying the price by a discount factor (e.g., 0.8 for 20% off) and setting sale-related fields.
MongoDB Operators in Action: This example demonstrates essential MongoDB operators:
$mul multiplies the price by the discount factor
$set updates specific fields without affecting others
In the filter, you could use $in to target multiple categories: "category": {"$in": ["electronics", "clothing"]}
This operation deletes a customer record with the specified ID. Make sure to implement proper validation and confirmation before executing deletion operations.
Example: Remove abandoned cart
This example removes an abandoned shopping cart after confirmation.Operation name: removeAbandonedCart
This operation removes all documents marked as “temporary” that were created before a specific date. Use with caution as this will delete all matching records.
Example: Clear completed tasks
This example removes all completed tasks for a specific user.Operation name: clearCompletedTasks
This operation removes all tasks that are marked as completed, were assigned to a specific user, and were completed before a certain date.
Always use caution with update and delete operations, especially those that affect multiple documents (updateMany, deleteMany). Always include specific filter criteria to avoid unintended changes to your data.
Multiple versions of documents are stored in the collection. Upon retrieval, all data that fits the filter conditions will be retrieved regardless of version.
No automatic migration capabilities are available. Any migration will need to be done manually by the DevOps team.
In the initial release, FlowX Database does not support transactions across multiple collections.
Data validation based on a schema is not yet supported.
FlowX Database provides a persistence layer that enables you to store and share data across different processes and projects. By using MongoDB’s capabilities through the nosql-db-runner service, FlowX Database offers:
Flexible data storage for any structured data
Data sharing between process instances
Integration with workflows
Independence from external systems for basic data persistence
FlowX Database does not replace Data Search. Each serves different purposes in the platform.
FlowX Database
Data Search
Acts as a persistent data store
Optimized for CRUD operations
Stores structured business data
Designed for sharing data across processes
Uses MongoDB as the underlying technology (via nosql-db-runner service)
Provides indexing and search capabilities
Optimized for quick lookups and aggregations
Used for debugging and analytics
Enables searching across process instances
Uses Elasticsearch as the underlying technology
What types of data should I store in FlowX Database?
FlowX Database is designed for operational data with temporary character, including:
Dashboard data: Aggregated information for reporting and visualization. For example, create operations that gather information from multiple processes and pull all the data to calculate sums, averages, or other metrics for executive dashboards
Cached data: Frequently accessed information that changes periodically, such as:
Daily exchange rates for financial calculations
Product catalogs that update weekly
Configuration data that multiple processes need to access
Internal operational comments: Information that needs to be shared between users but shouldn’t reach business systems, such as:
Internal comments in a client’s profile for bank tellers
Notes and annotations that support decision-making across different process instances
Communication logs between team members working on the same case
Shared process data: Information that needs to be accessed across multiple process instances - this solves the key pain point of data sharing between different process instances
Temporary operational data: Working data that supports business processes but isn’t part of your permanent records
Important: FlowX Database should not become your primary book of records or system of record. Use it for operational data that supports your processes, not for critical business data that requires long-term retention and governance.
Can I share FlowX Database collections between different projects?
Yes, you can share collections between projects using the library approach:
Create collections in one project: Set up your FlowX Database collections in a primary project
Include as libraries: Add these collections as libraries in other projects that need access
Maintain consistency: This approach ensures all projects use the same data structures and operations
Future-proof management: Having centralized collection definitions makes updates and maintenance easier across all projects
This pattern is particularly useful for shared reference data, common configurations, or cross-project operational data.
Collection Ownership: Each FlowX Database collection has an owner - either the project where it was created or the library that contains it. By default, only processes and workflows within the same project can access a collection. If you need to access the same collection from multiple projects, create it in a library and then include that library in all projects that need access.
Why doesn't FlowX Database support automatic data migration?
FlowX Database intentionally does not provide automatic migration capabilities for several important reasons:
Data integrity: Many documents need to remain in their original format to maintain historical accuracy and compliance requirements
Process dependencies: Existing processes may depend on specific data structures, and automatic changes could break functionality
Business context: Data migration often requires business logic and context that automated systems cannot provide
Risk management: Manual migration allows for proper testing and validation before changes are applied
When you need to modify data structures, plan for manual migration processes with proper testing and validation procedures handled by your DevOps team.
Can I store different types of documents in the same collection?
No, this is strongly discouraged. Each collection should contain documents with the same structure and purpose.DON’T DO IT - Mixing different document types in one collection can lead to:
Query complexity: Filtering becomes more complex when documents have different schemas
Performance issues: Indexes become less effective with mixed document types
Maintenance problems: Updates and changes become harder to manage
Data consistency: Harder to ensure data quality and validation
Instead, create separate collections for each document type, even if they seem related. This follows MongoDB best practices and keeps your data organized and manageable.
How does FlowX Database solve cross-process data sharing?
FlowX Database solves the key pain point of accessing the same data from multiple process instances:
Cross-instance access: Multiple process instances can read from and write to the same collections simultaneously
Data persistence: Data remains available even after individual processes complete
Shared state: Enables complex workflows where processes need to coordinate through shared data
This capability enables use cases like multi-step approval processes, shared customer data across different business processes, and coordinated workflows that span multiple process instances - addressing a major limitation of traditional process-scoped data storage.
What's the relationship between FlowX Database and the nosql-db-runner service?
FlowX Database is powered by the nosql-db-runner microservice, which provides:
Pure MongoDB functionality: Direct access to MongoDB operations within the FlowX ecosystem
Native integration: Connection between FlowX workflows and MongoDB operations
Scalable architecture: A dedicated service that can be scaled independently based on database operation needs
The nosql-db-runner acts as the bridge between FlowX’s workflow engine and MongoDB, enabling you to use MongoDB’s full capabilities while maintaining FlowX’s process orchestration capabilities.