Infrastructure prerequisites
Before installing the FlowX.AI Engine, verify that the following infrastructure components are installed and configured:- Kafka
- Elasticsearch
- PostgreSQL
- MongoDB
Dependencies
The FlowX Engine requires the following components:- Database: Primary storage for the engine
- Redis Server: Used for caching. See Redis Configuration
- Kafka: Handles messaging and event-driven architecture. See Configuring Kafka
Required external services
- Redis Cluster: Caches process definitions, compiled scripts, and Kafka responses
- Kafka Cluster: Enables communication with external plugins and integrations
Configuration setup
FlowX.AI Engine uses environment variables for configuration. This section covers key configuration areas:- Database configuration
- Script engine configuration
- Authorization & access roles
- Kafka configuration
- File upload size
- Elasticsearch connection
Database configuration
PostgreSQL
MongoDB configuration
Configure connection to the Runtime MongoDB instance:Configuration parameters
There are two types of Config Params that can be read from the environment: variables and secrets. There is one provider for variables and secrets extracted from the environment variables, and two providers for the ones extracted from Kubernetes. By default, the variables and secrets are extracted from environment variables (env provider).
Configuration parameters from environment variables (default)
Theenv provider used for variables and secrets extracts them from environment variables. For security reasons, the env provider uses an allow list regex which defaults to FLOWX_CONFIGPARAM_.*. This means only environment variables that match this naming pattern can be read at runtime into configuration params (either as variables or secrets). Feel free to edit it to match the environment variables that you use in your deployment.
Configuration parameters from Kubernetes Secrets and ConfigMaps
Use the following configuration to read Config Params from Kubernetes Secrets and ConfigMaps:
These providers can be configured as follows:
You can configure multiple secrets and ConfigMaps by incrementing the index number (e.g.,
FLOWX_CONFIGPARAMS_PROVIDERS_K8SSECRETS_SECRETSLIST_1, FLOWX_CONFIGPARAMS_PROVIDERS_K8SCONFIGMAPS_CONFIGMAPSLIST_1). Values are overridden based on the order in which the maps are defined.The default provider is env, but there is a built-in allowlist with the regex pattern FLOWX_CONFIGPARAM_.*. This means only configuration parameters that match this naming pattern can be read at runtime, whether they are environment variables or secret variables.Configuring script engine
FlowX.AI Engine supports multiple scripting languages for business rules and actions.You must also enable these environment variables on the AI Developer agent, if you have it set up.
Python runtime configuration
By default, FlowX.AI 4.7.1 uses Python 2.7 (Jython) as the Python runtime. To enable Python 3 via GraalPy with its 3x performance improvements and JavaScript with GraalJS, you must explicitly set the feature toggle.
GraalVM cache configuration
When using GraalVM (FLOWX_SCRIPTENGINE_USEGRAALVM=true), ensure the engine has proper access to a cache directory within the container. By default, this is configured in the /tmp directory.
For environments with filesystem restrictions or custom configurations, you need to properly configure the GraalVM cache.
Option 1: Using Java options (Preferred)
Add the following Java option to your deployment configuration:Option 2: Using environment variables
Alternatively, set the following environment variable:Authorization & access roles
This section covers OAuth2 configuration settings for securing the Spring application.Resource server settings (OAuth2 configuration)
Starting from version 4.1, use the following configuration instead. This setup is backwards compatible until version 4.5.
Service account settings
Configure the process engine service account:
For more information about the necessary service account, see Process Engine Service Account.
Security configuration
Configuring Kafka
Kafka handles all communication between the FlowX.AI Engine, external plugins, and integrations. It also notifies running process instances when certain events occur.Kafka connection settings
Message routing configuration
When
KAFKA_DEFAULTFXCONTEXT is set and an event is received on Kafka without an fxContext header, the system will automatically apply the default context value to the message.Kafka consumer retry settings
Consumer groups & consumer threads configuration
Both a producer and a consumer must be configured:Configuring a Kafka Producer
Configuring a Kafka Consumer

About consumer groups and threads
A consumer group is a set of consumers that jointly consume messages from one or more Kafka topics. Each consumer group has a unique identifier (group ID) that Kafka uses to manage message distribution. Thread numbers refer to the number of threads a consumer application uses to process messages. Increasing thread count can improve parallelism and efficiency, especially with high message volumes.Consumer group configuration
Consumer thread configuration
All events that start with a configured pattern will be consumed by the Engine. This enables you to create new integrations and connect them to the engine without changing the configuration.
Configuring Kafka topics
Core engine topics
Topics related to the Task Management plugin
OPERATIONS_IN request example
BULK_IN request example
To send additional keys in the response, attach them in the header. For example, you can use a
requestID key.A response should be sent on a 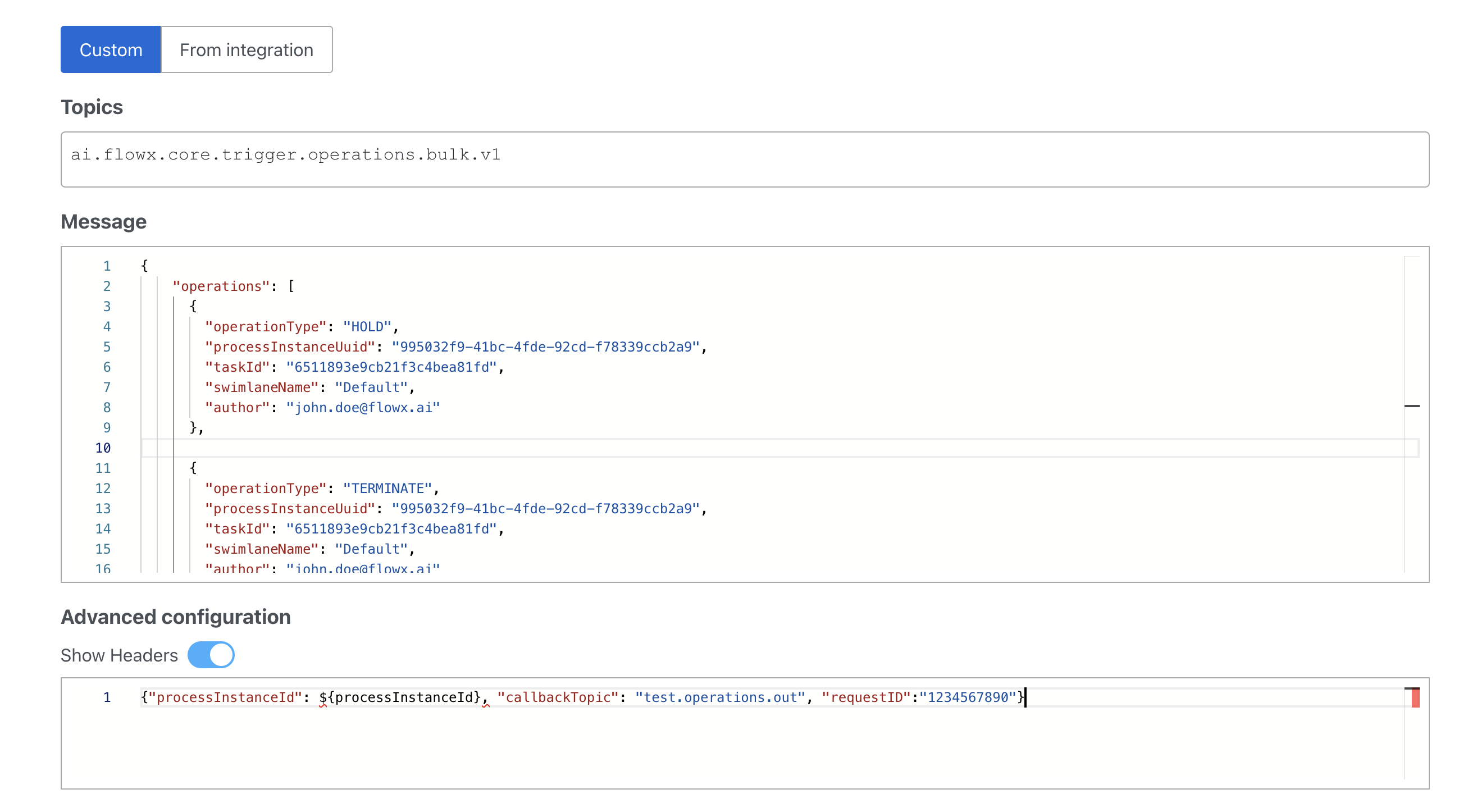
callbackTopic if it is mentioned in the headers:Task manager operations include: assignment, unassignment, hold, unhold, terminate. These are matched with the
...operations.out topic on the engine side. For more information, see the Task Management plugin documentation:📄 Task management pluginTopics related to the scheduler extension
Topics related to Timer Events
Topics related to the Search Data service
Topics related to the Audit service
Topics related to ES indexing
Processes that can be started by sending messages to a Kafka topic
Topics related to Message Events
Topics related to Events-gateway microservice
Topics related to platform components
Inter-service topic coordination
When configuring FlowX services, ensure the following:- The Engine’s
patternmust match the pattern used by services sending messages to the Engine - The
integrationPatternmust match the pattern used by the Integration Designer - Output topics from one service must match the expected input topics of another service
- Services send to topics matching
ai.flowx.dev.engine.receive.*→ Engine listens - Engine sends to topics matching
ai.flowx.dev.integration.receive.*→ Integration Designer listens
Kafka message size configuration
This setting affects:
- Producer message max bytes
- Producer max request size
- Consumer max partition fetch bytes
Kafka authentication
For secure environments, you can enable OAuth authentication with the following configuration:KAFKA_OAUTH_CLIENT_IDKAFKA_OAUTH_CLIENT_SECRETKAFKA_OAUTH_TOKEN_ENDPOINT_URI
Configuring Elasticsearch connection
The Process Engine uses Elasticsearch for process instance indexing and search capabilities. Configure the connection using these environment variables:For indexing setup, check the Configuring Elasticsearch indexing section.
Configuring file upload size
Connecting the Advancing controller
To use the advancing controller, configure the following variables:Configuring advancing controller
Advancing controller setup
Configuring cleanup mechanism
Managing subprocesses expiration
Configuring application management
Starting from version 4.1, use the following configuration instead. This setup is backwards compatible until version 5.0.