Did you know?
Unlike Postman, which focuses on API testing, the Integration Designer automates workflows between systems. With drag-and-drop ease, it handles REST API connections, real-time processes, and error management, making integrations scalable and easy to mantain.
Overview
Integration Designer facilitates the integration of the FlowX platform with external systems, applications, and data sources.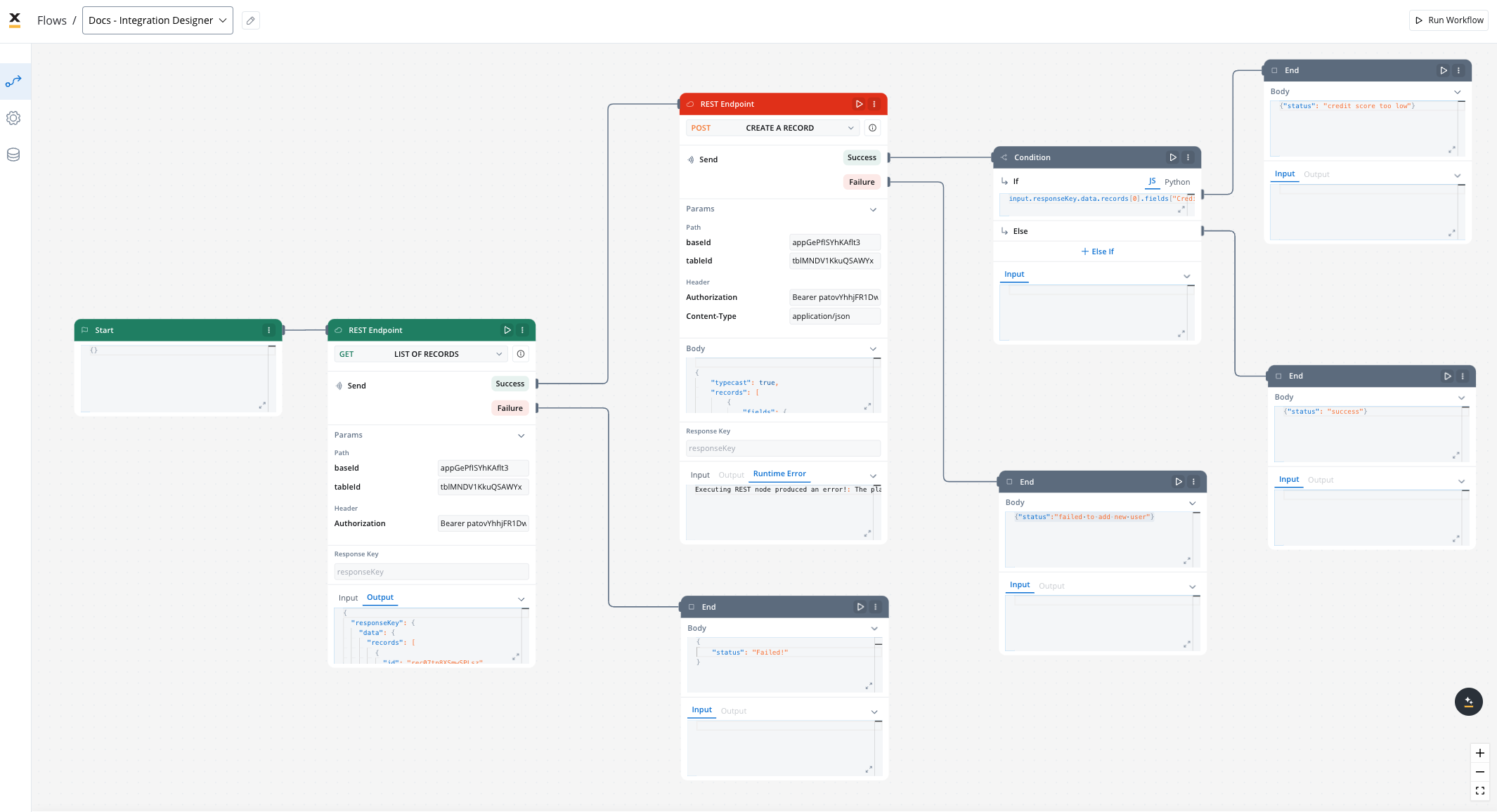
Integration Designer focuses on REST API integrations, with future updates expanding support for other protocols.
Key features
1
Drag-and-Drop Simplicity
You can easily build complex API workflows using a drag-and-drop interface, making it accessible for both technical and non-technical audience.
2
Visual REST API Integration
Specifically tailored for creating and managing REST API calls through a visual interface, streamlining the integration process without the need for extensive coding.
3
Real-Time Testing and Validation
Allows for immediate testing and validation of REST API calls within the design interface.
Managing integration endpoints
Systems
A system is a collection of resources—endpoints, authentication, and variables—used to define and run integration workflows.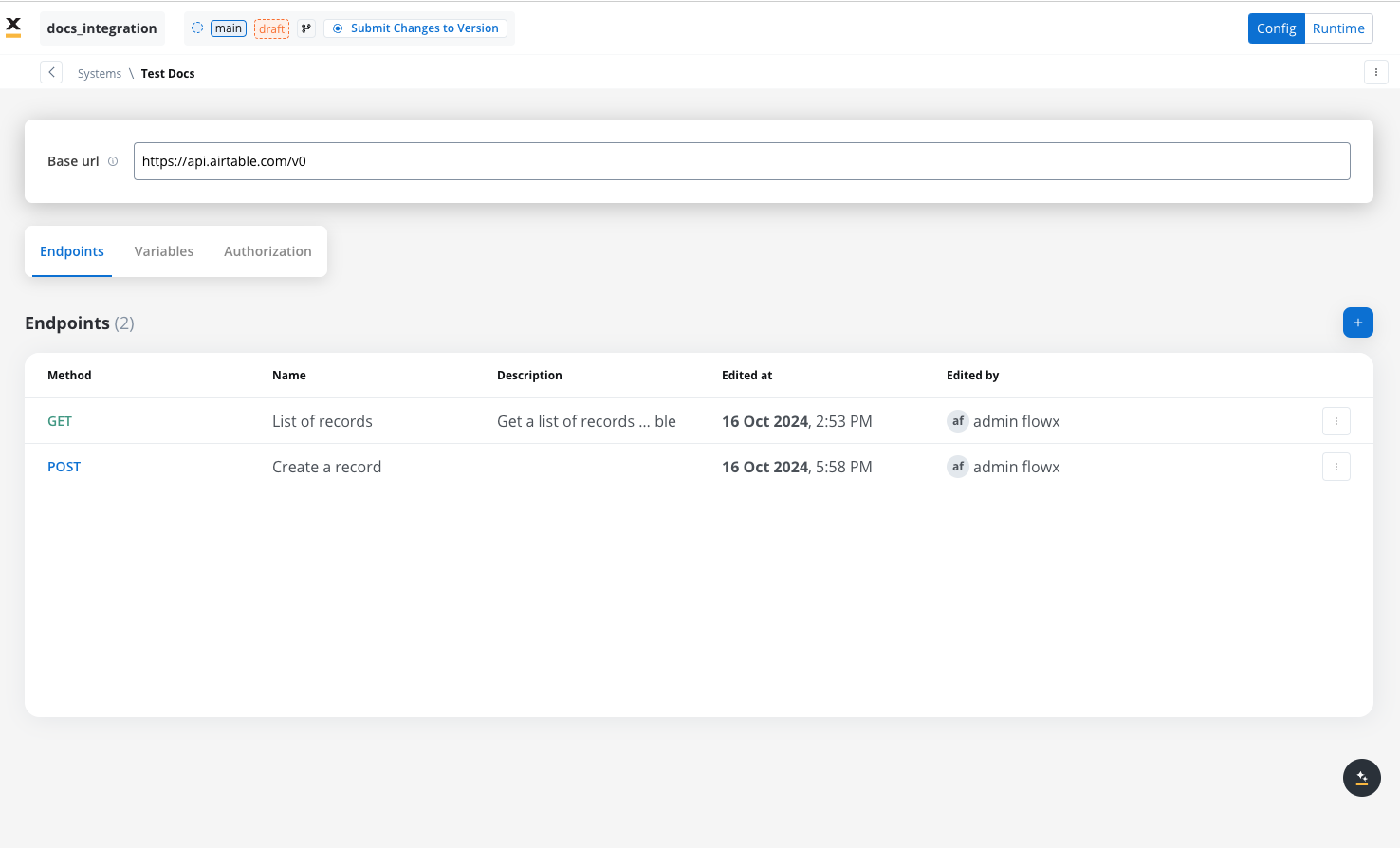
Creating a new system definition
With Systems feature you can create, update, and organize endpoints used in API integrations. These endpoints are integral to building workflows within the Integration Designer, offering flexibility and ease of use for managing connections between systems. Endpoints can be configured, tested, and reused across multiple workflows, streamlining the integration process.
- Add a New System, set the system’s unique code, name, and description:
- Name: The system’s name.
- Code: A unique identifier for the external system.
- Base URL: The base URL is the main address of a website or web application, typically consisting of the protocol (
httporhttps), domain name, and a path. - Description: A description of the system and its purpose.
- Enable enumeration value mapping: If checked, this system will be listed under the mapped enumerations. See enumerations section for more details.
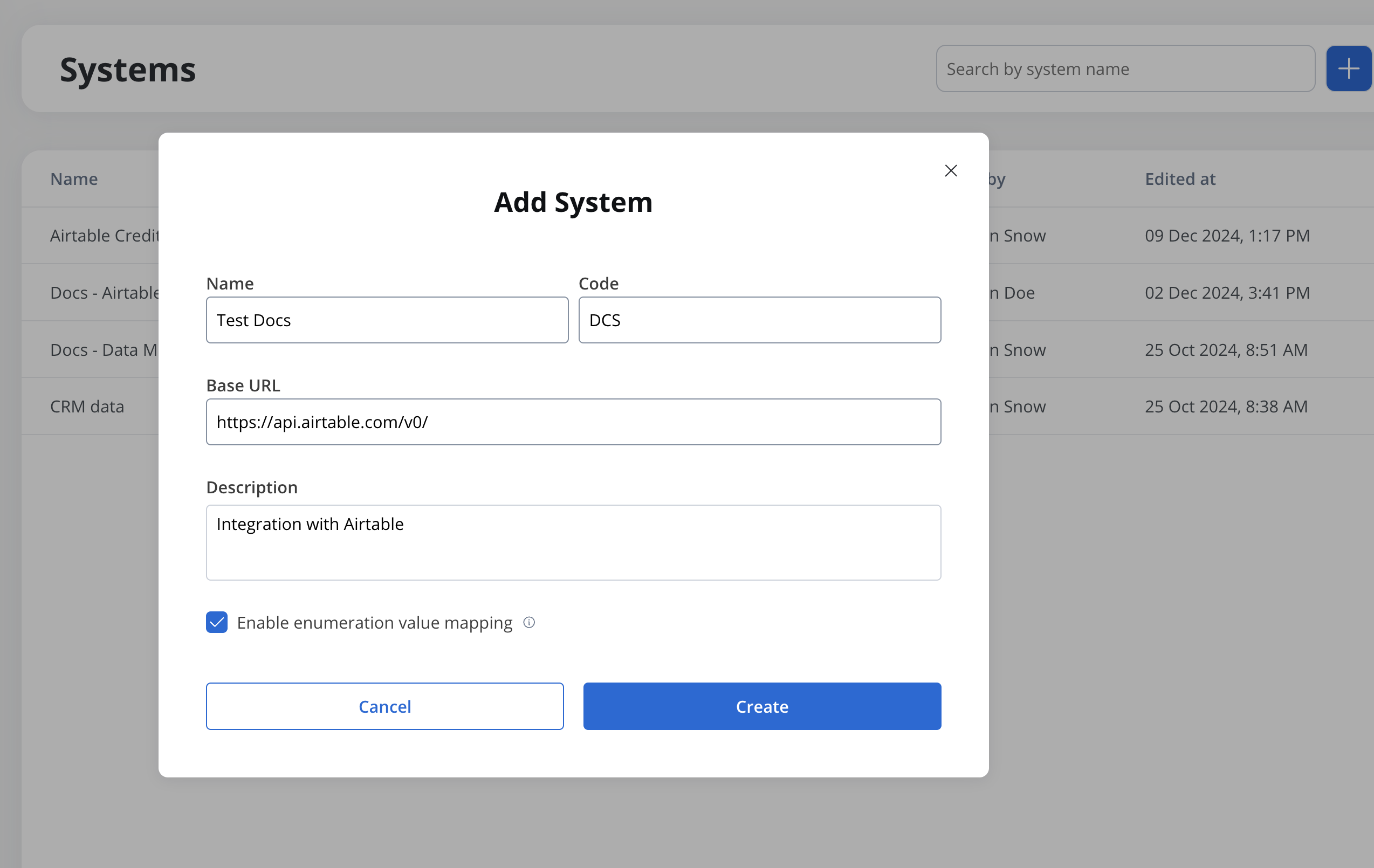
- Set up authorization (Service Token, Bearer Token, or No Auth). In our example, we will set the auth type as a bearer and we will set it at system level:
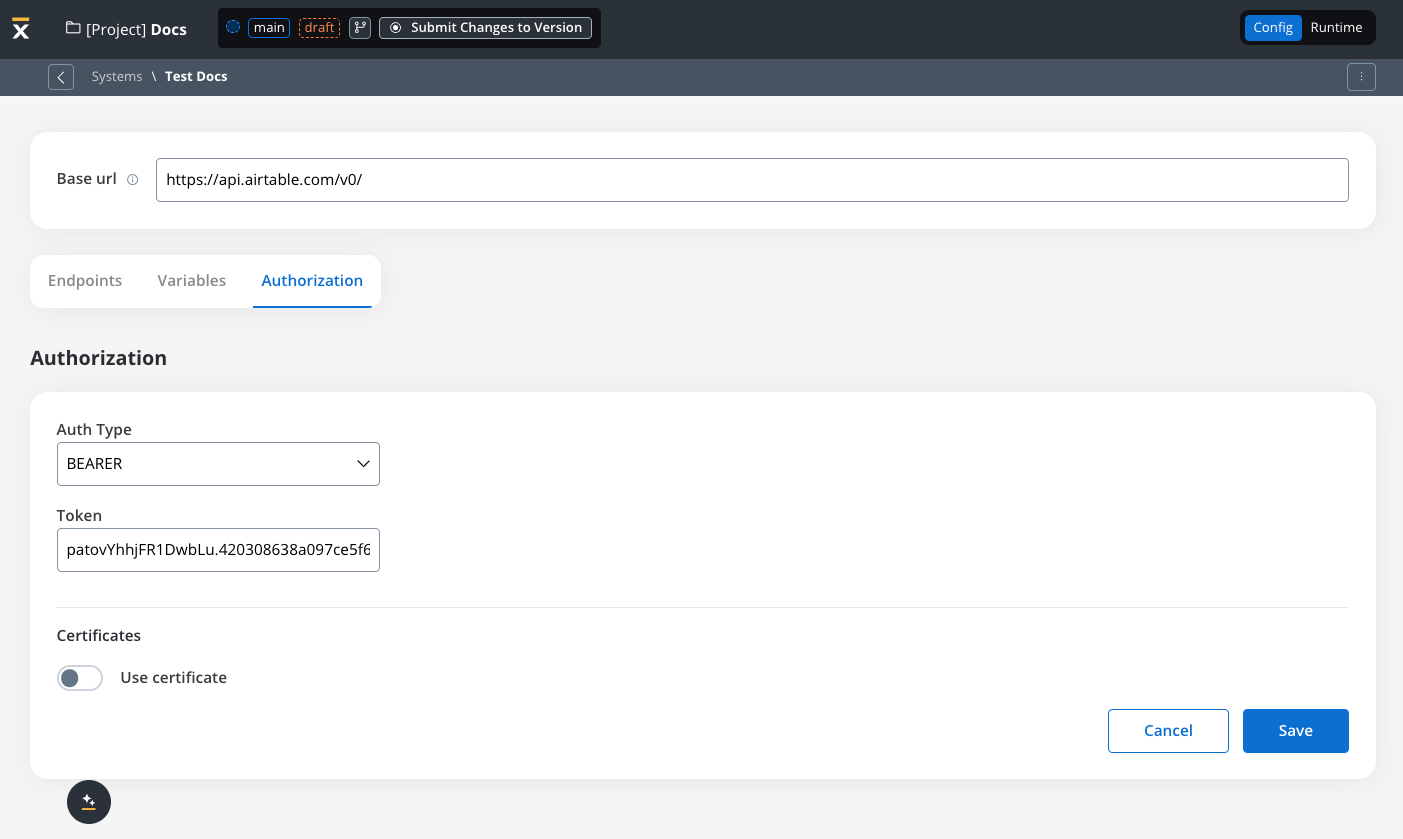
Defining REST integration endpoints
In this section you can define REST API endpoints that can be reused across different workflows.- Under the Endpoints section, add the necessary endpoints for system integration.
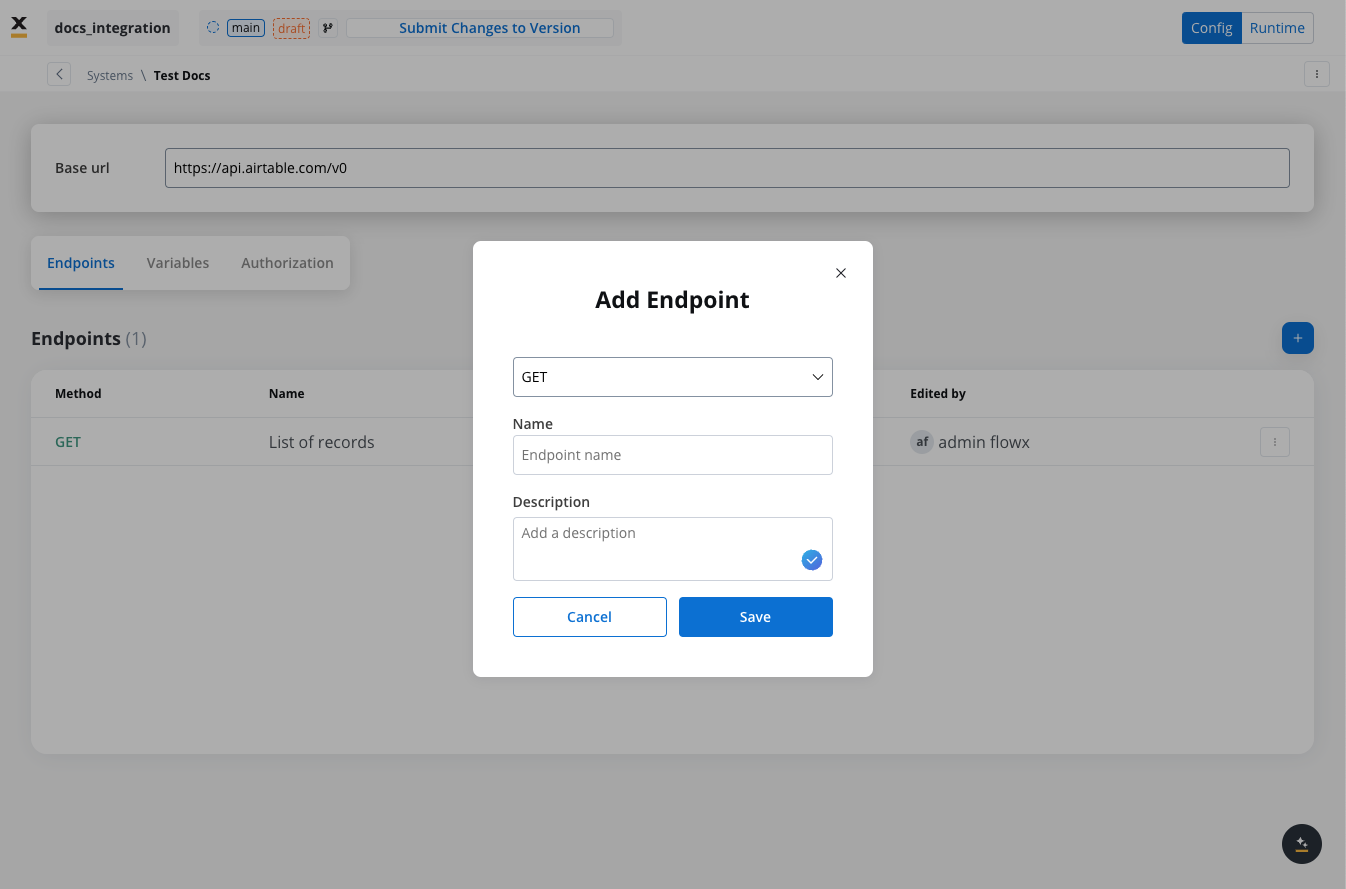
- Configure an endpoint by filling in the following properties:
- Method: GET, POST, PUT, PATCH, DELETE.
- Path: Path for the endpoint.
- Parameters: Path, query, and header parameters.
- Response Settings: Expected response codes and formats.
- Body: JSON payload for requests.
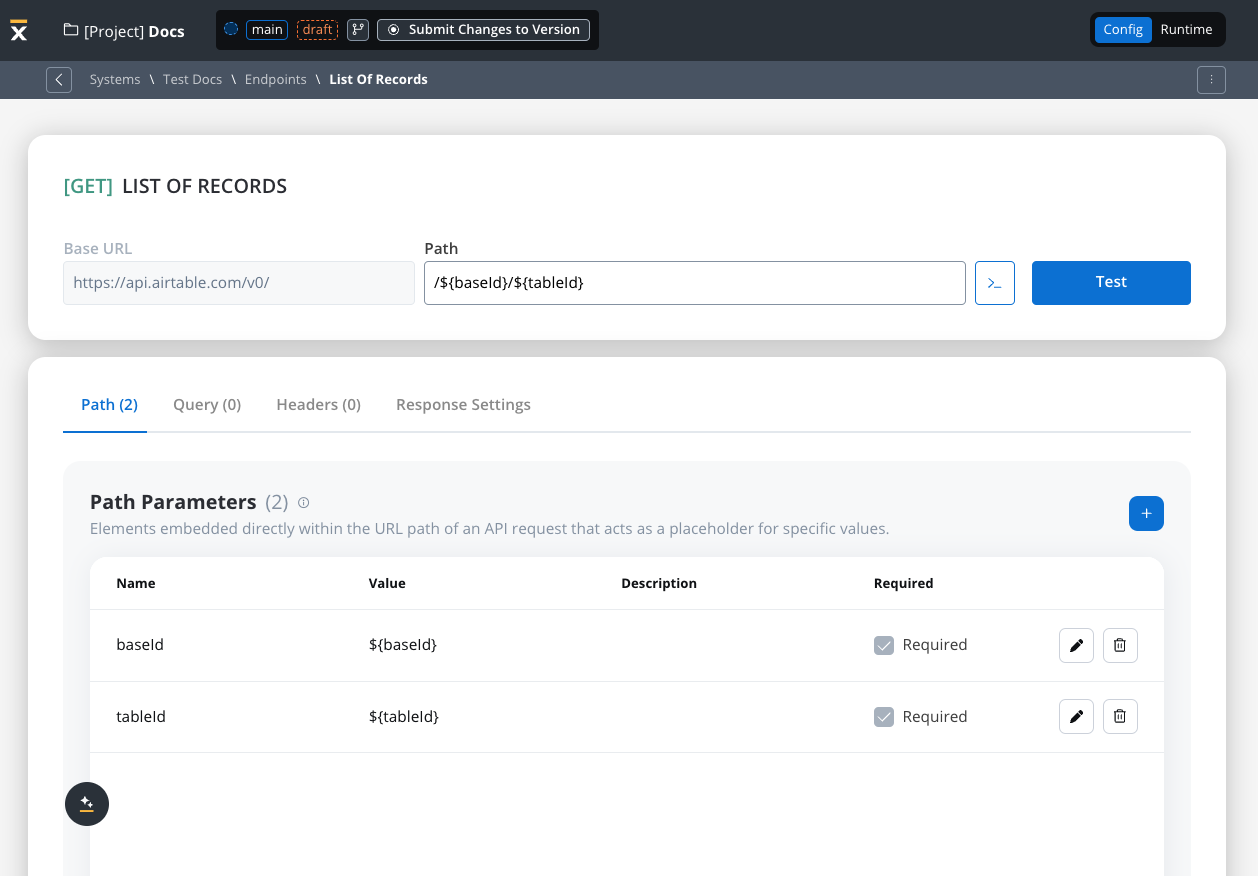
Defining variables
The Variables tab allows you to store system-specific variables that can be referenced throughout workflows using the format${variableName}.
These declared variables can be utilized not only in workflows but also in other sections, such as the Endpoint or Authorization tabs.
For example: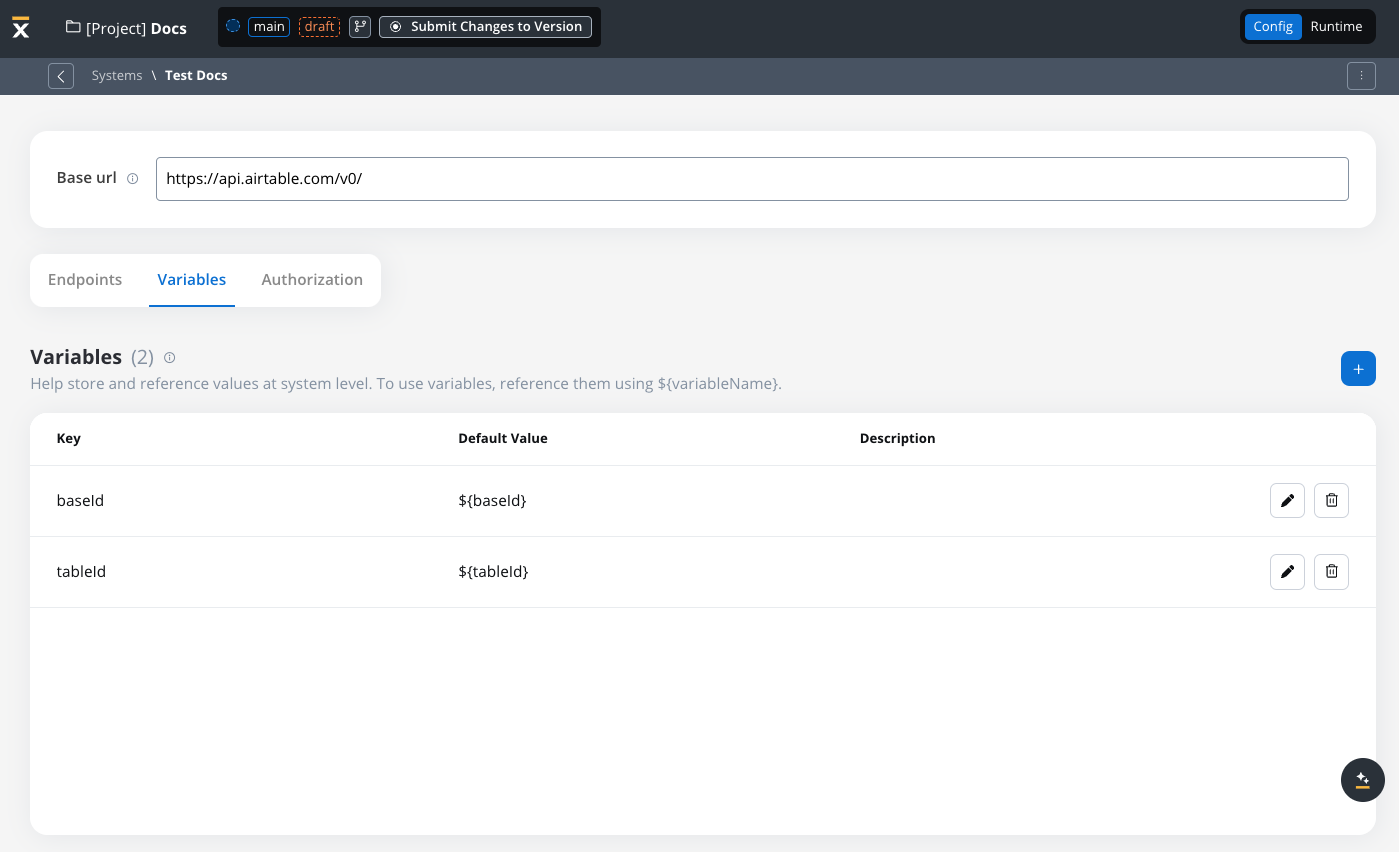
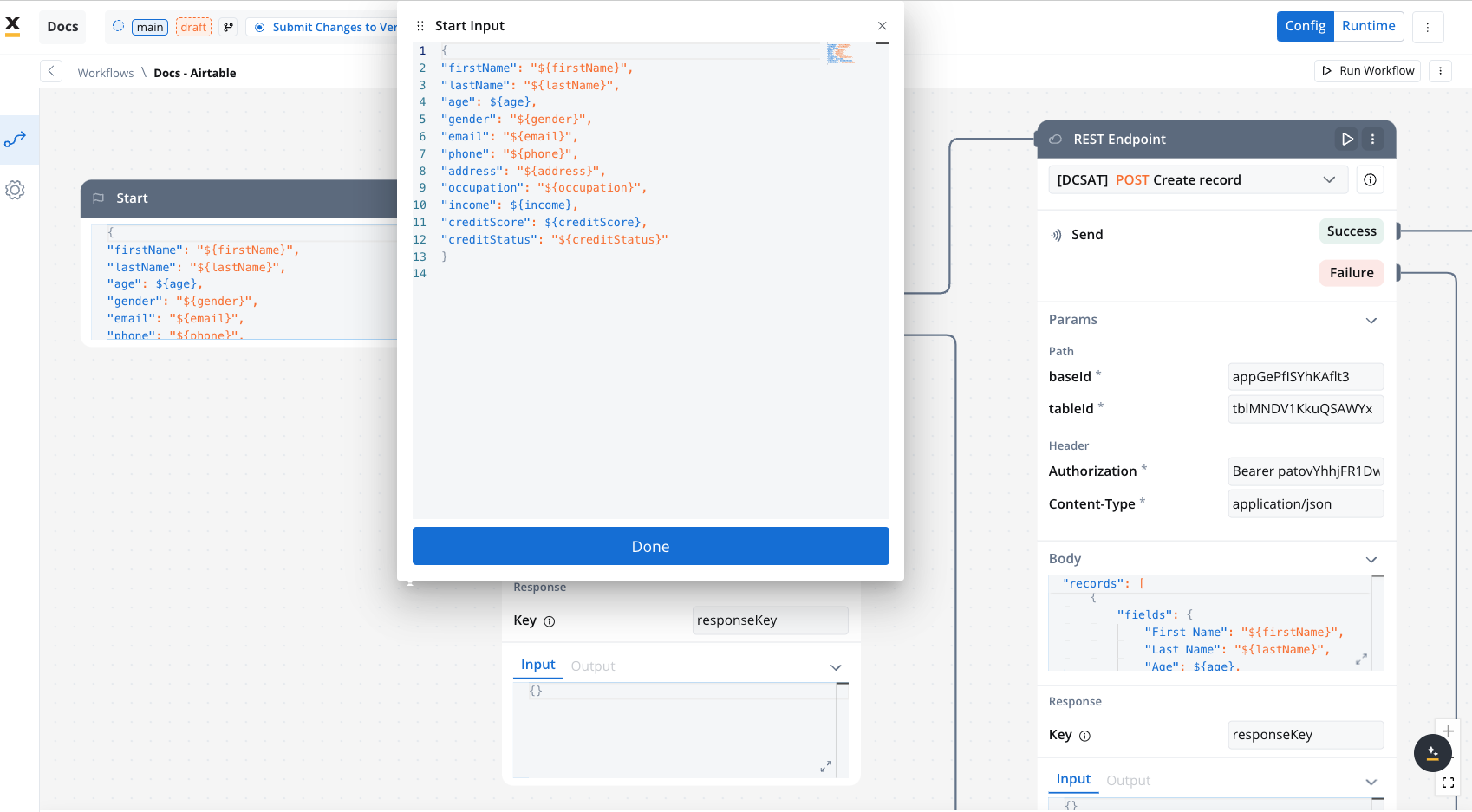
- For our integration example, you can declare configuration parameters and use the variables to store your tableId and baseId and reference them the Variables tab.
- Use variables in the Base URL to switch between different environments, such as UAT or production.
Endpoint parameter types
When configuring endpoints, several parameter types help define how the endpoint interacts with external systems. These parameters ensure that requests are properly formatted and data is correctly passed.Path parameters
Elements embedded directly within the URL path of an API request that acts as a placeholder for specific value.- Used to specify variable parts of the endpoint URL (e.g.,
/users/{userId}). - Defined with
${parameter}format. - Mandatory in the request URL.
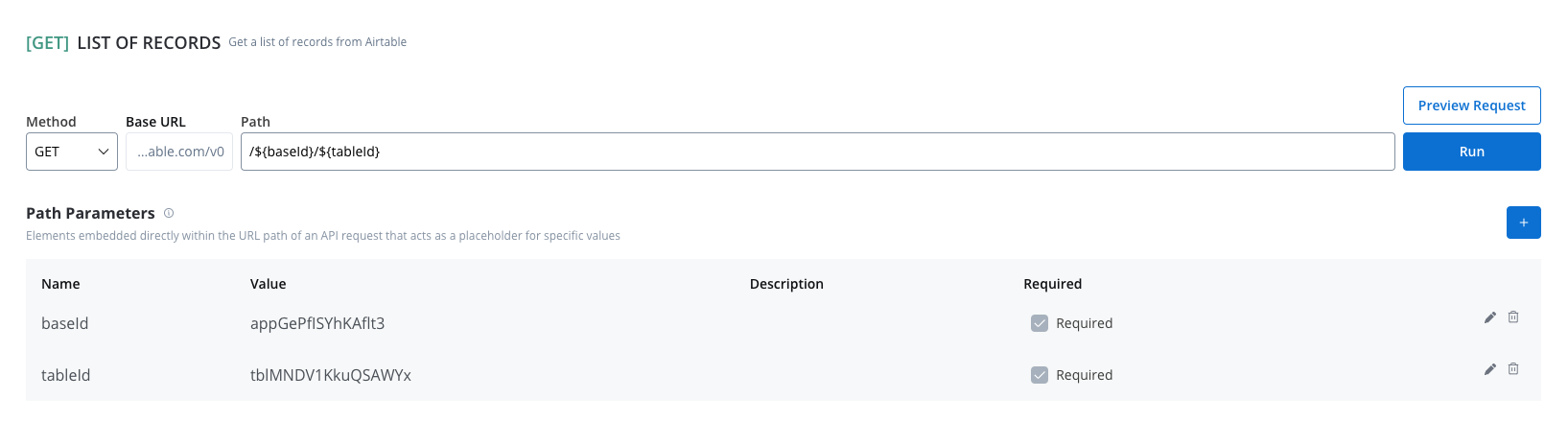
Query parameters
Query parameters are added to the end of a URL to provide extra information to a web server when making requests.- Query parameters are appended to the URL after a
?symbol and are typically used for filtering or pagination (e.g.,?search=value) - Useful for filtering or pagination.
- Example URL with query parameters: https://api.example.com/users?search=johndoe&page=2.
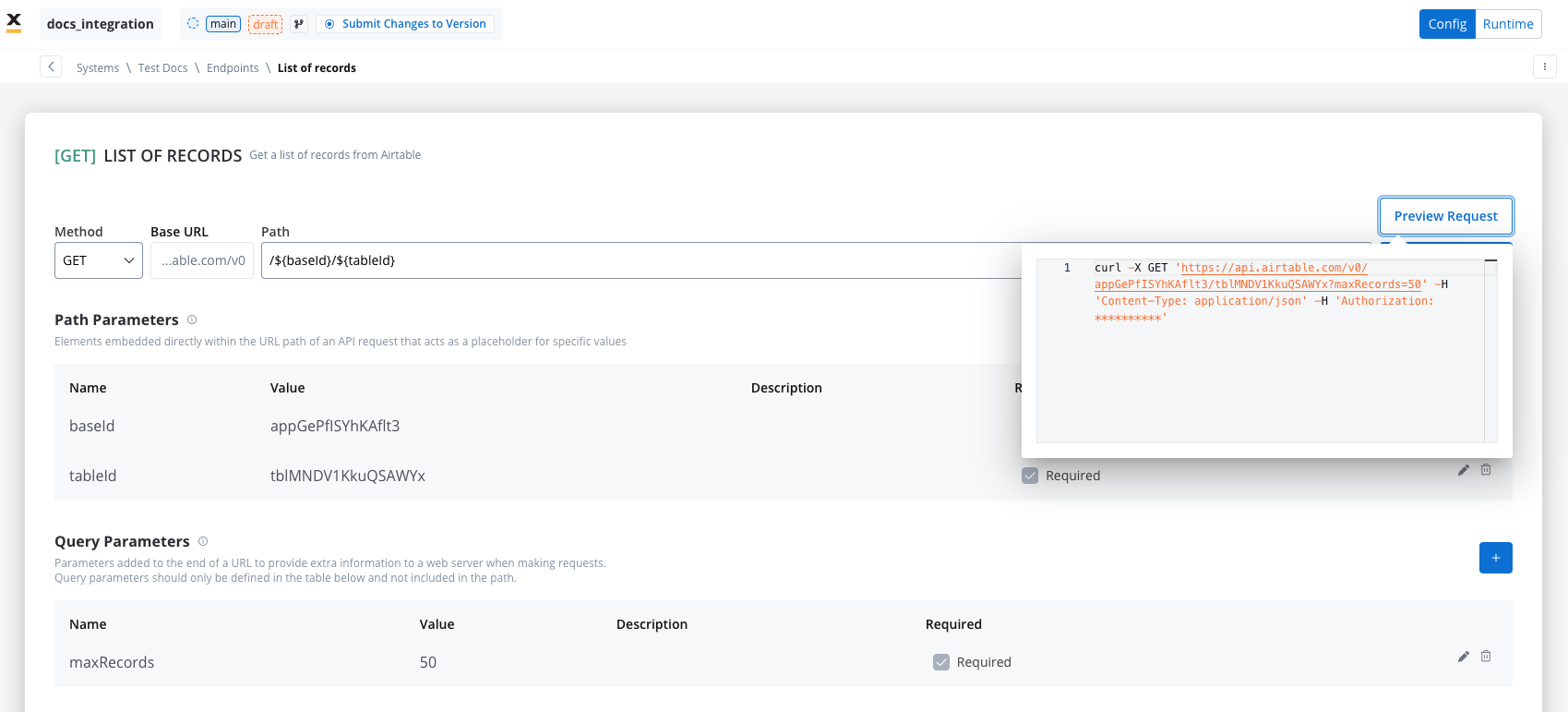
To preview how query parameters are sent in the request, you can use the Preview feature to see the exact request in cURL format. This shows the complete URL, including query parameters.
Header parameters
Used to give information about the request and basically to give instructions to the API of how to handle the request- Header parameters (HTTP headers) provide extra details about the request or its message body.
- They are not part of the URL. Default values can be set for testing and overridden in the workflow.
- Custom headers sent with the request (e.g.,
Authorization: Bearer token). - Define metadata or authorization details.

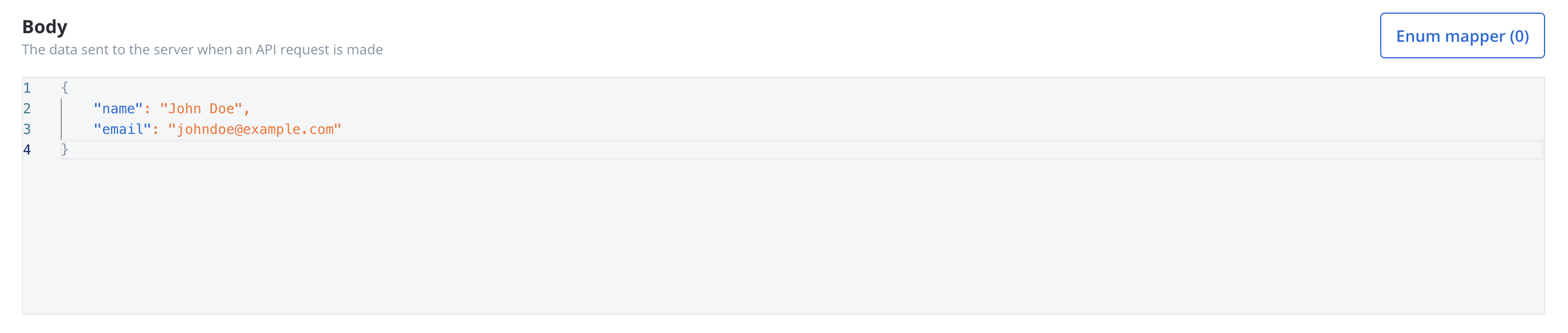
Body parameters
The data sent to the server when an API request is made.- These are the data fields included in the body of a request, usually in JSON format.
- Body parameters are used in POST, PUT, and PATCH requests to send data to the external system (e.g., creating or updating a resource).
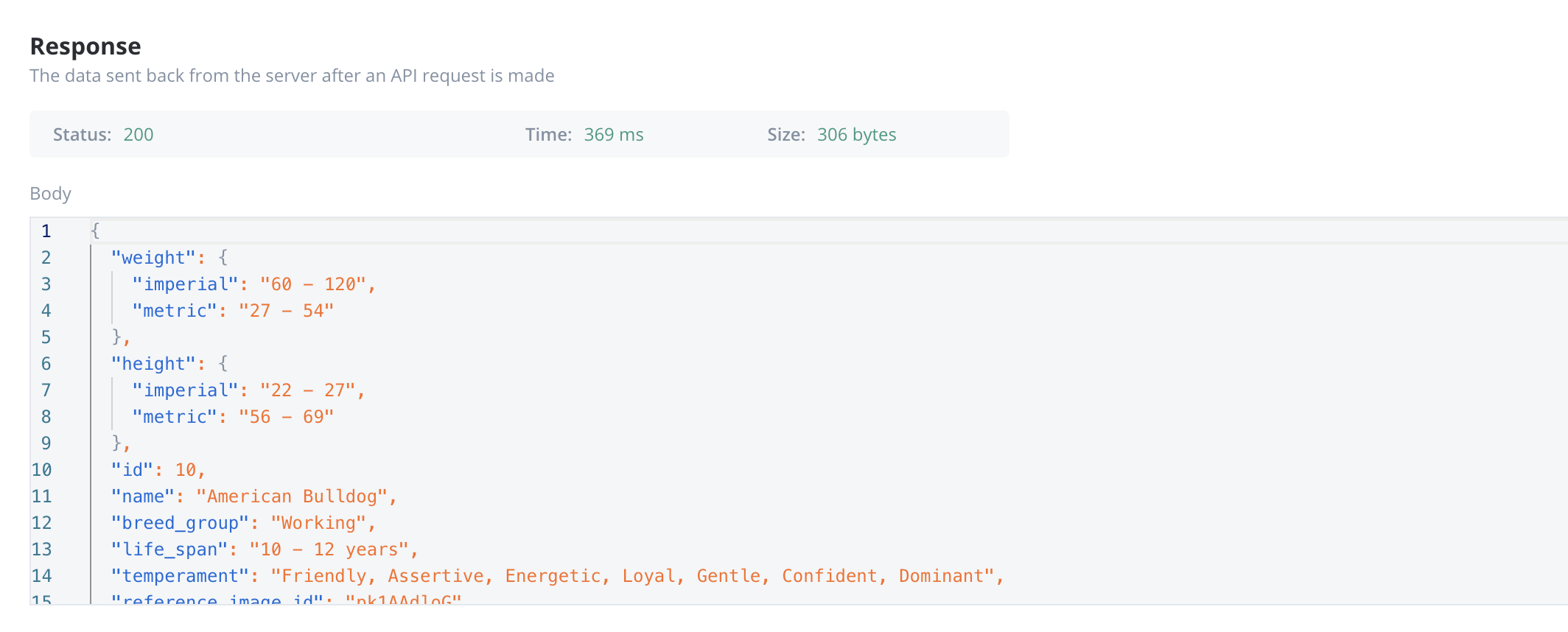
Response body parameters
The data sent back from the server after an API request is made.- These parameters are part of the response returned by the external system after a request is processed. They contain the data that the system sends back.
- Typically returned in GET, POST, PUT, and PATCH requests. Response body parameters provide details about the result of the request (e.g., confirmation of resource creation, or data retrieval)
Enum mapper
The enum mapper for the request body enables you to configure enumerations for specific keys in the request body, aligning them with values from the External System or translations into another language.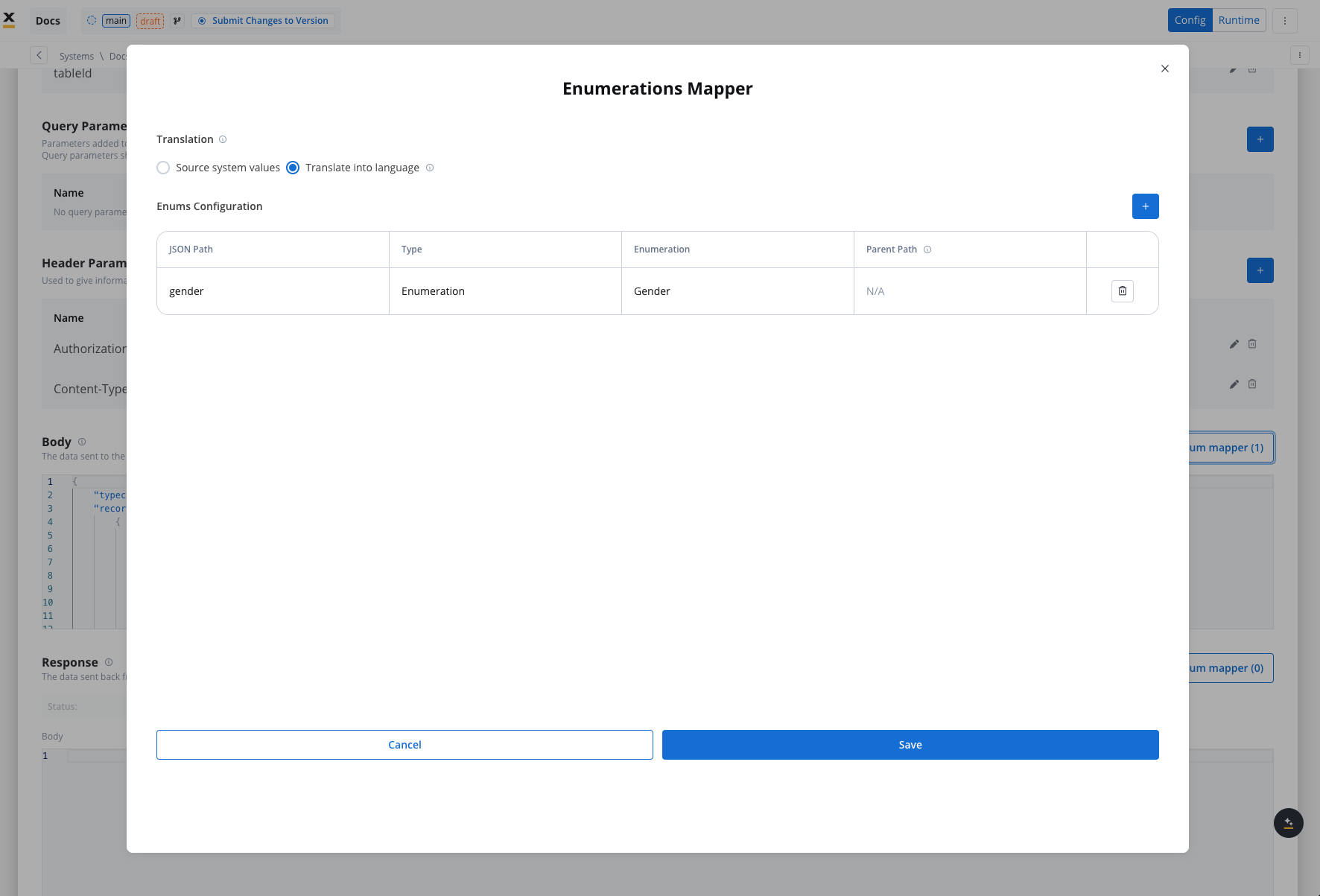
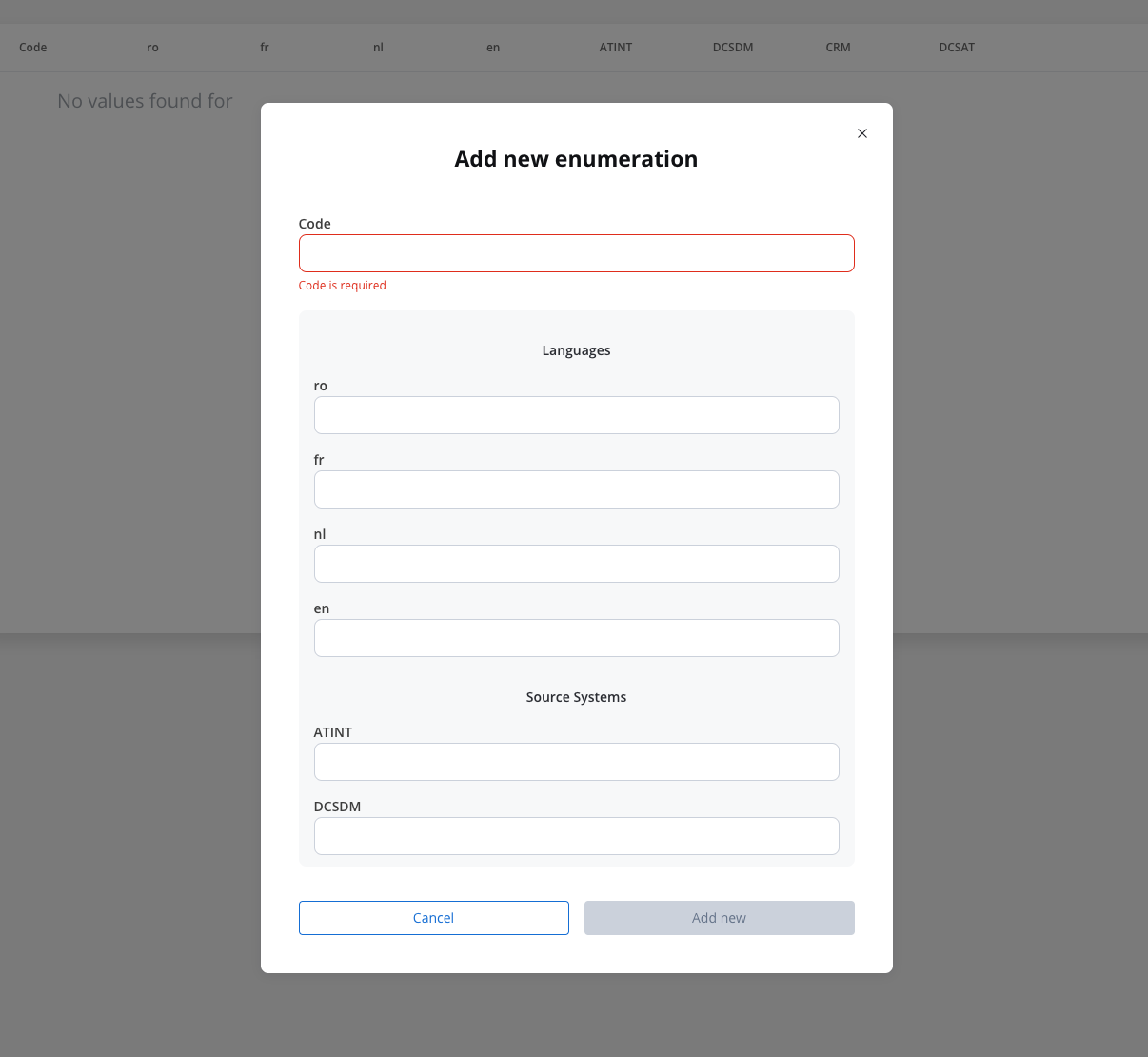
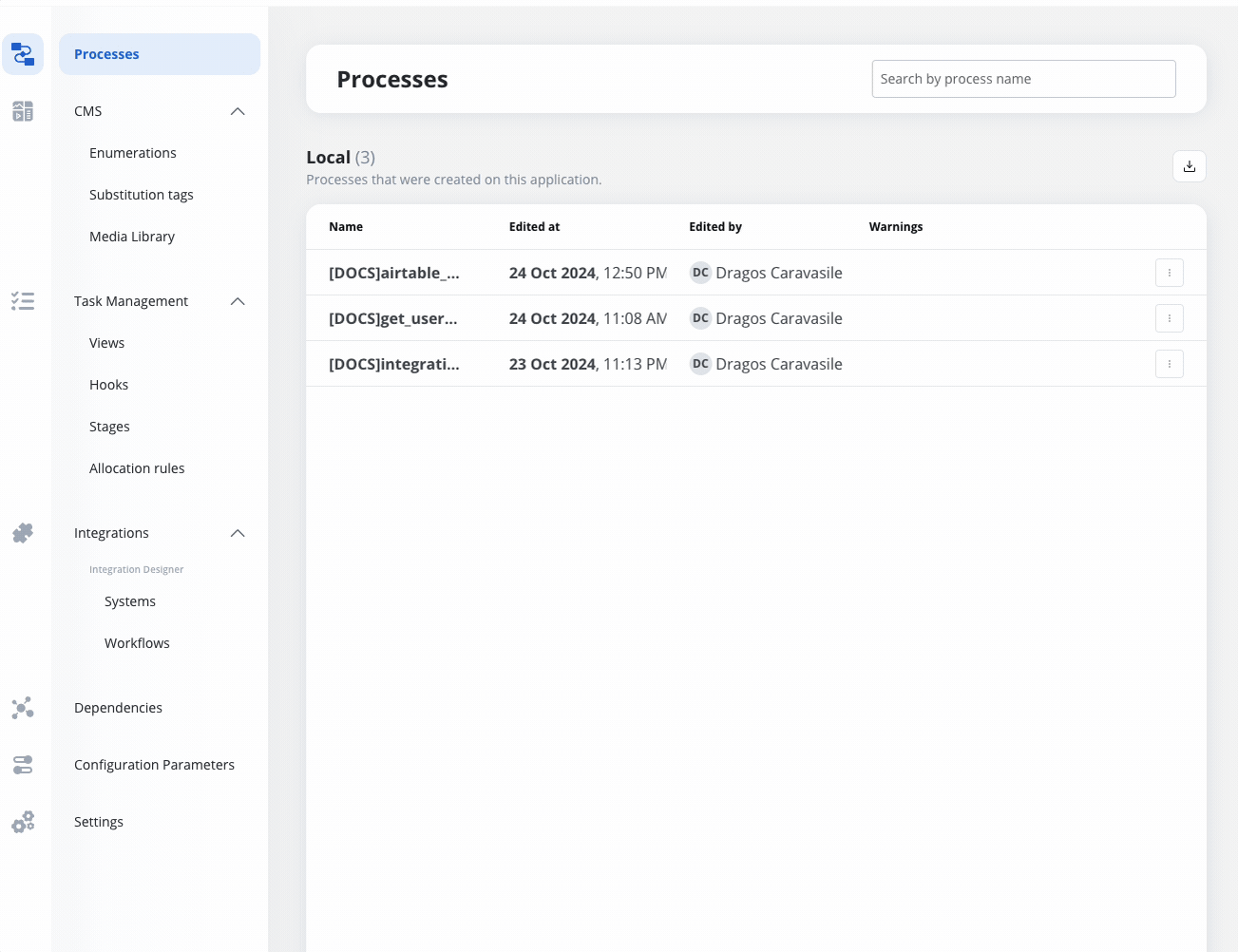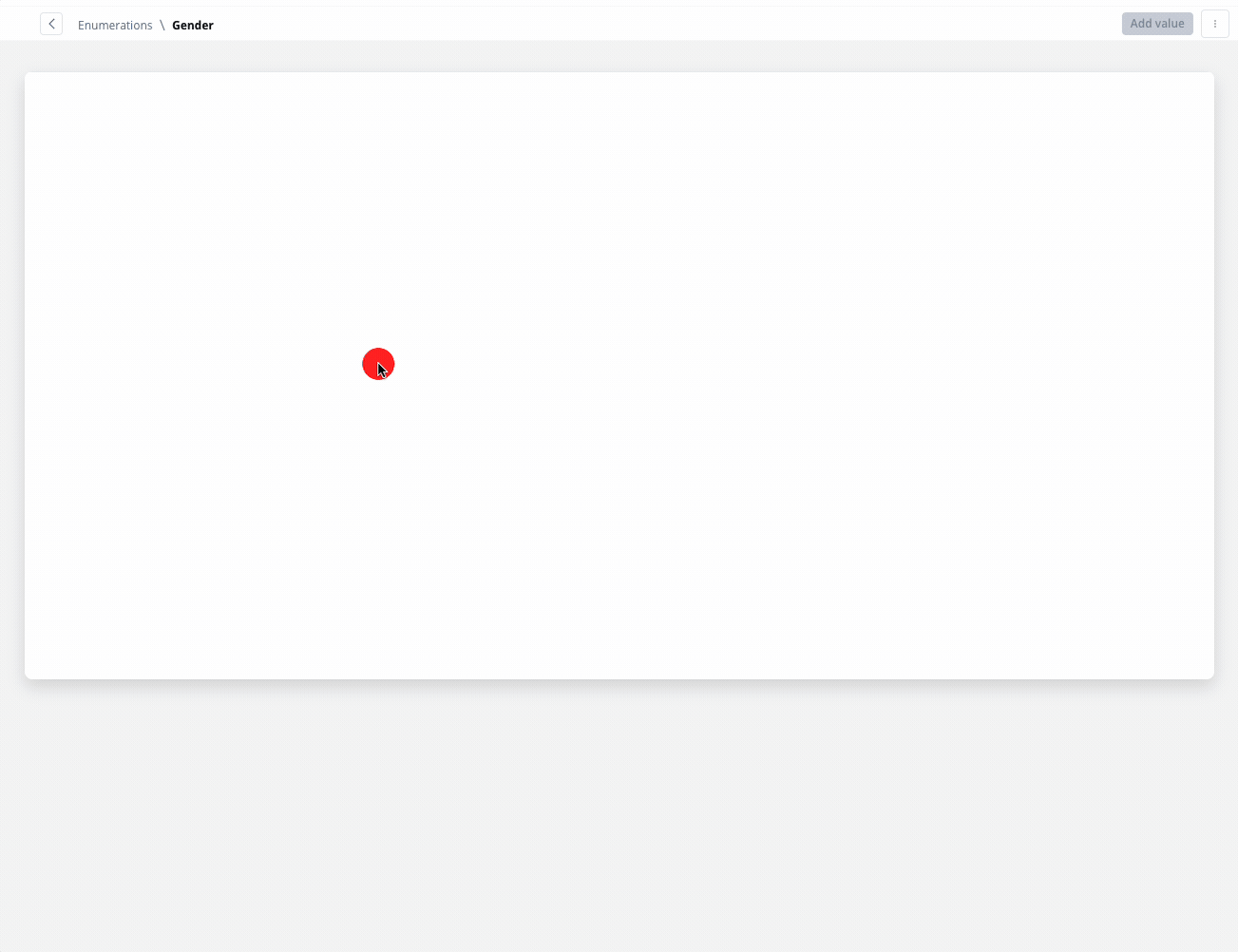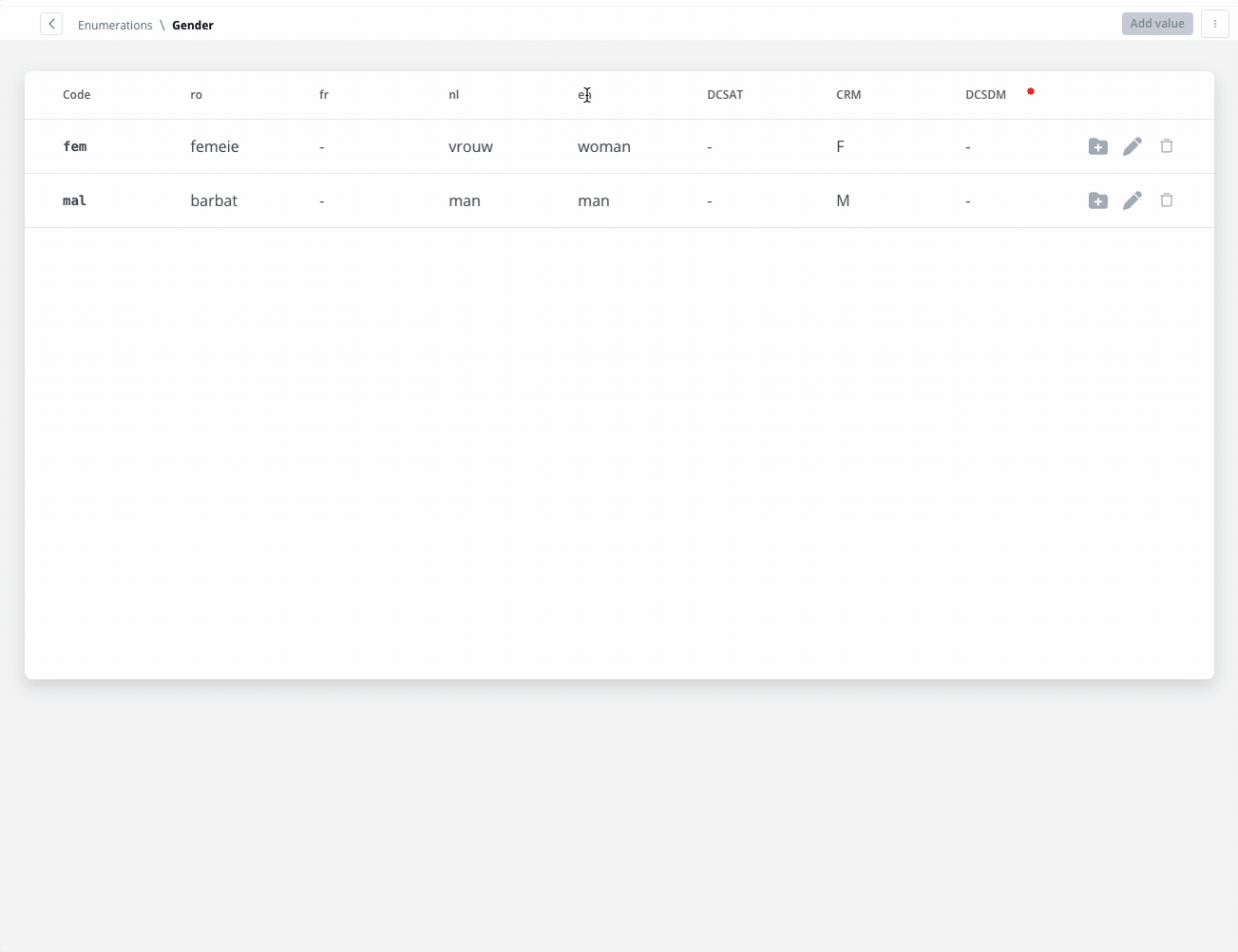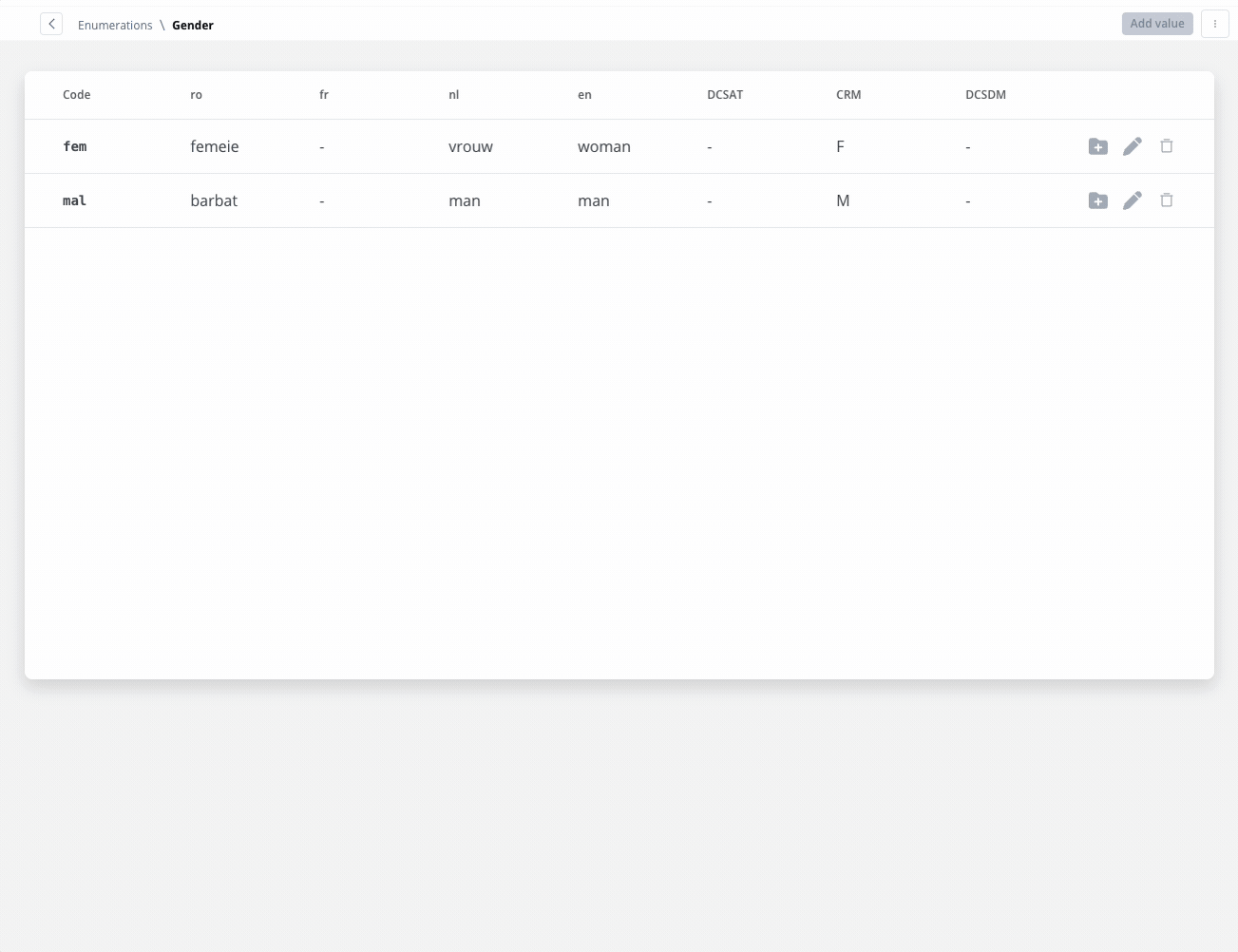
Select whether to use in the integration the enumeration value corresponding to the External System or the translation into another language.For translating into language a header parameter called ‘Language’ is required to specify the language for translation.
Configuring authorization
- Select the required Authorization Type from a predefined list.
- Enter the relevant details based on the selected type (e.g., Realm and Client ID for Service Accounts).
- These details will be automatically included in the request headers when the integration is executed.
Authorization methods
The Integration Designer supports several authorization methods, allowing you to configure the security settings for API calls. Depending on the external system’s requirements, you can choose one of the following authorization formats: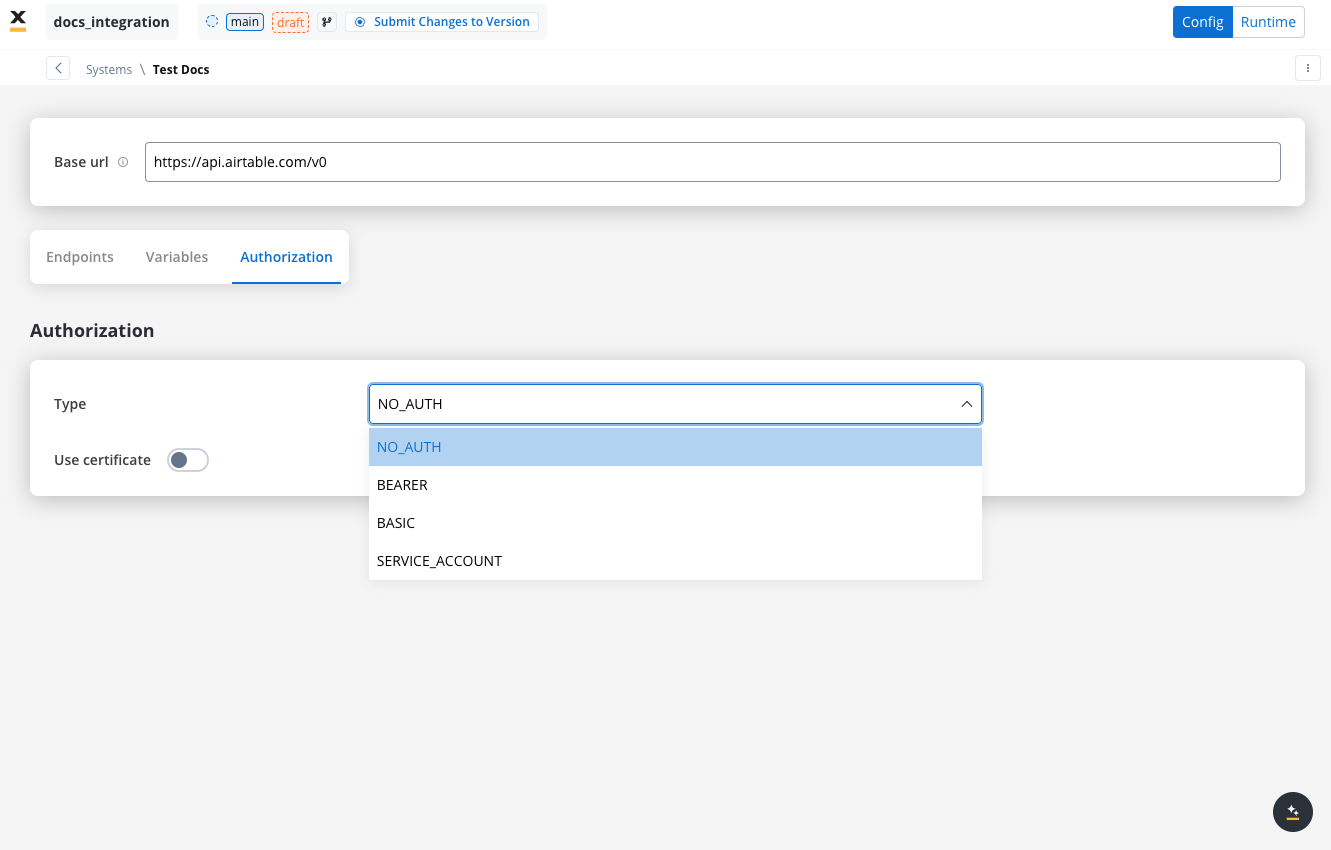
Service account
Service Account authentication requires the following key fields:- Identity Provider Url: The URL for the identity provider responsible for authenticating the service account.
- Client Id: The unique identifier for the client within the realm.
- Client secret: A secure secret used to authenticate the client alongside the Client ID.
- Scope: Specifies the access level or permissions for the service account.
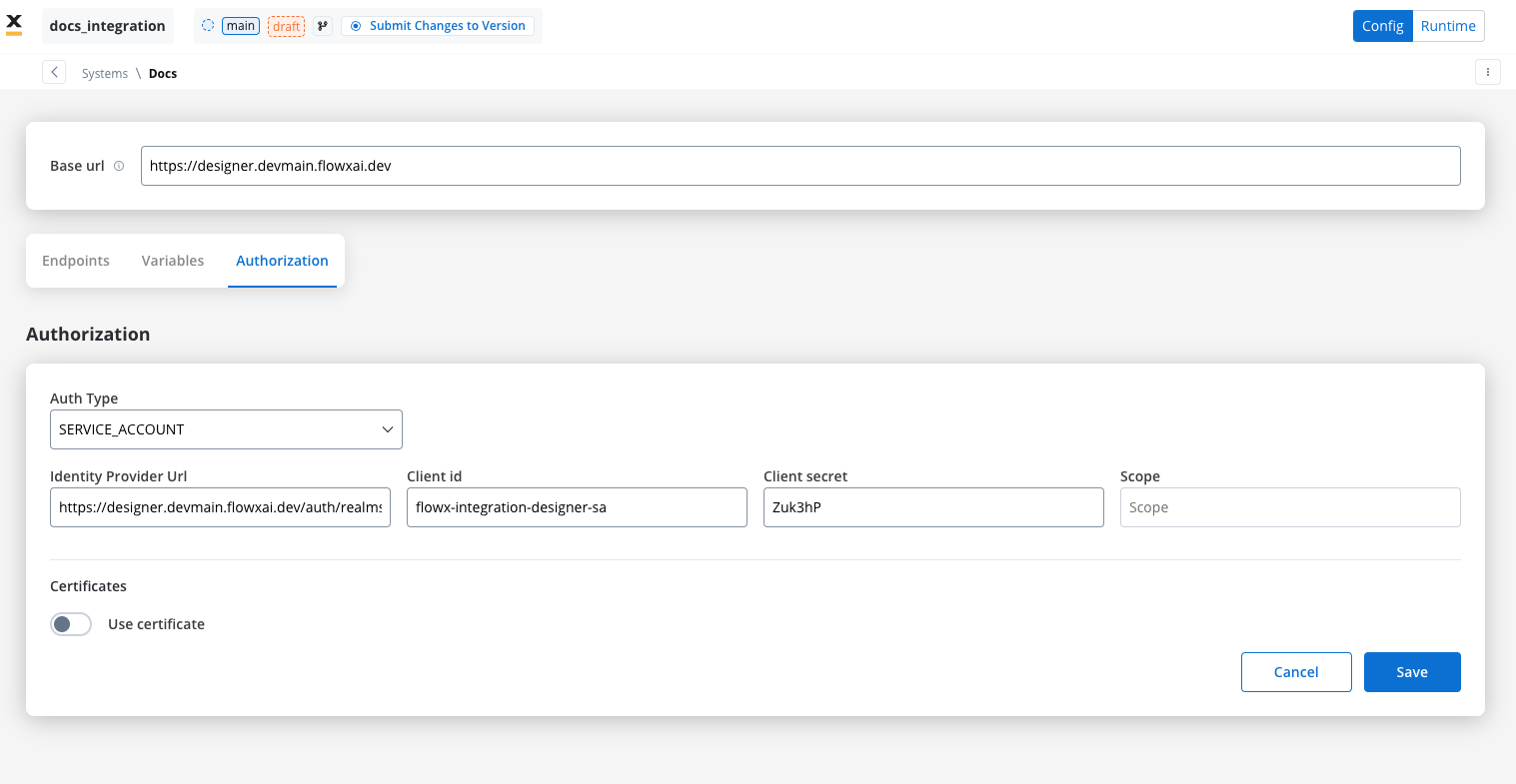
When using Entra as an authentication solution, the Scope parameter is mandatory. Ensure it is defined correctly in the authorization settings.
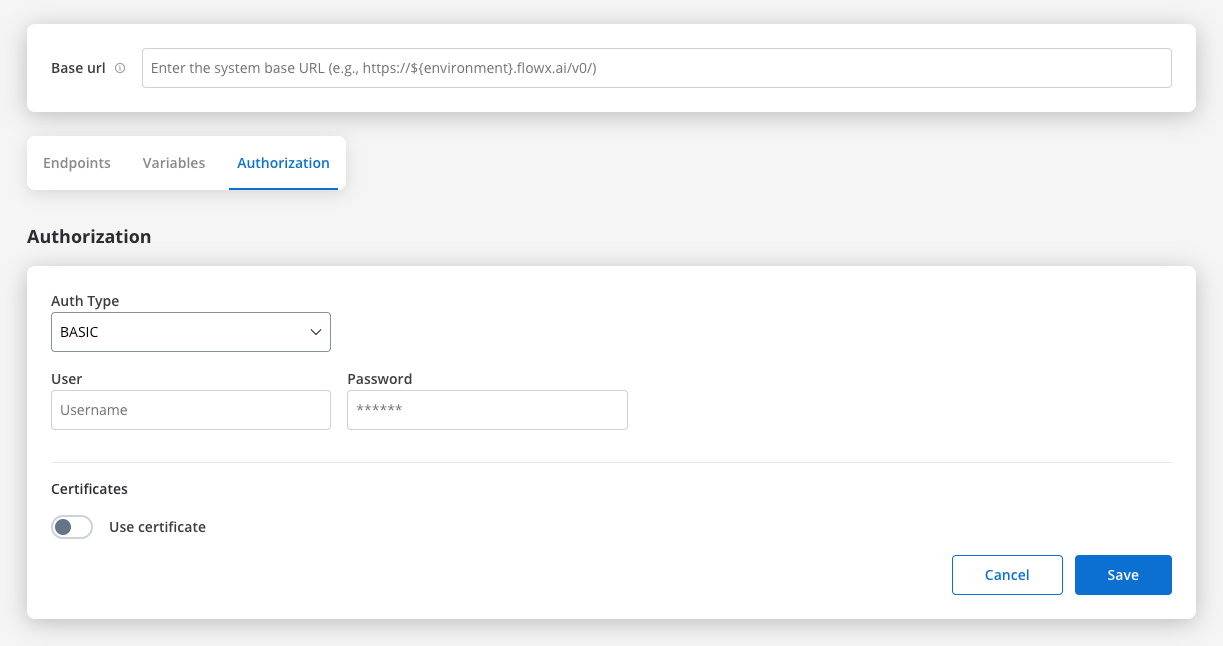
Basic authentication
- Requires the following credentials:
- Username: The account’s username.
- Password: The account’s password.
- Suitable for systems that rely on simple username/password combinations for access.
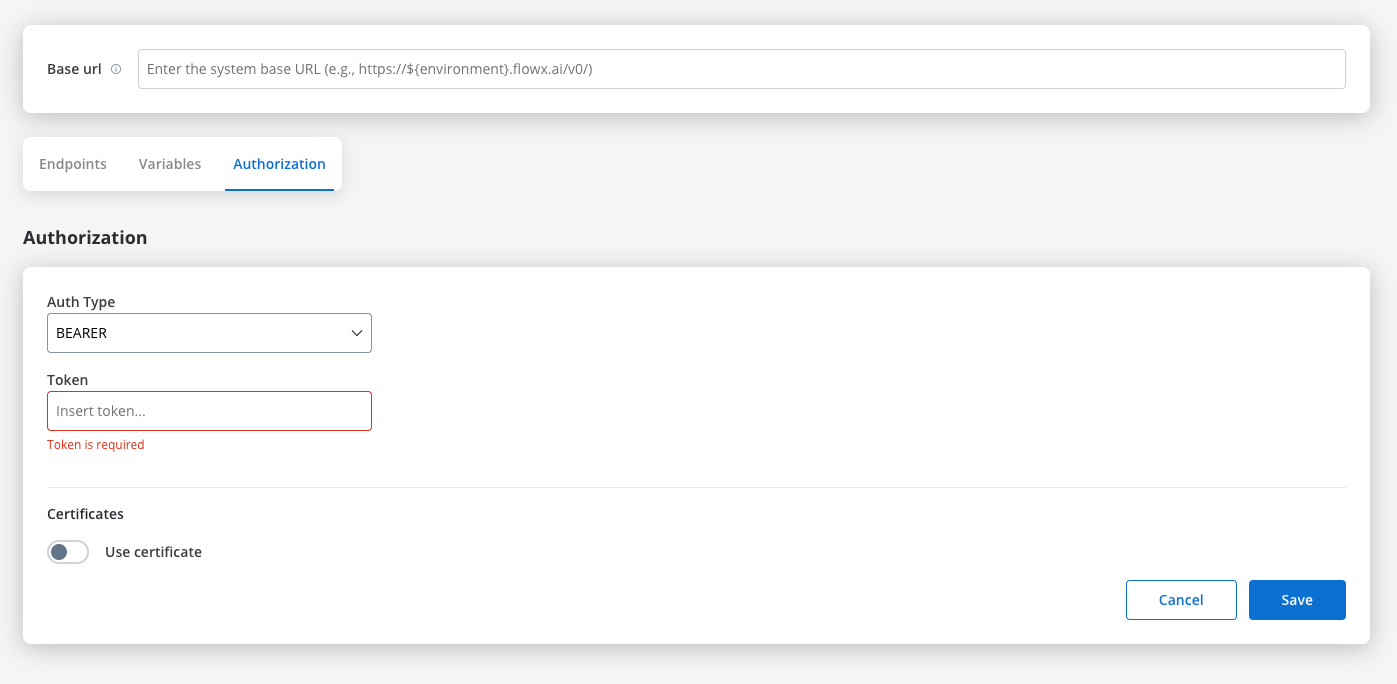
Bearer
- Requires an Access Token to be included in the request headers.
- Commonly used for OAuth 2.0 implementations.
- Header Configuration: Use the format
Authorization: Bearer {access_token}in headers of requests needing authentication.
- System-Level Example: You can store the Bearer token at the system level, as shown in the example below, ensuring it’s applied automatically to future API calls:
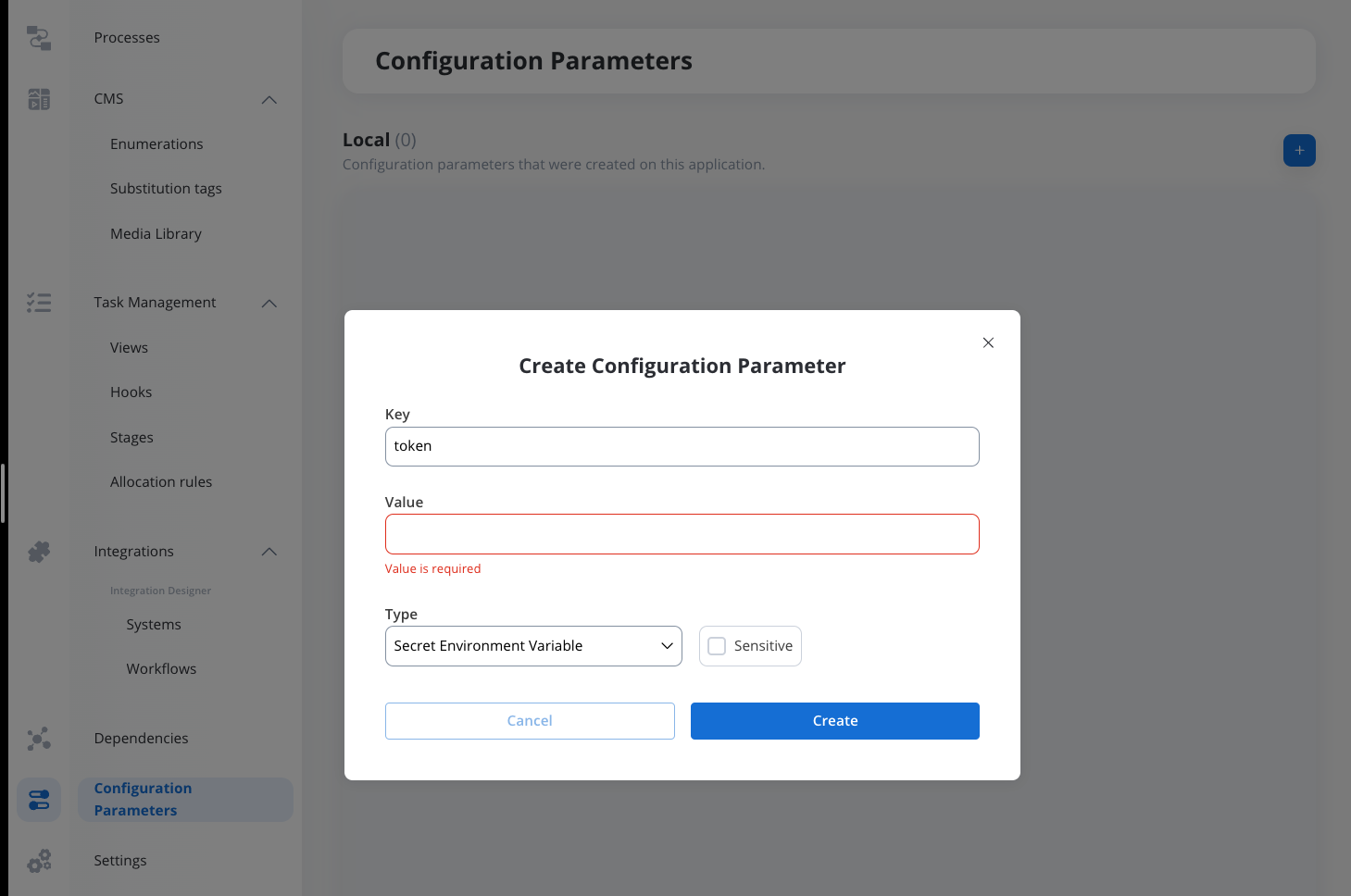
Store tokens in a configuration parameter so updates propagate across all requests seamlessly when tokens are refreshed or changed.
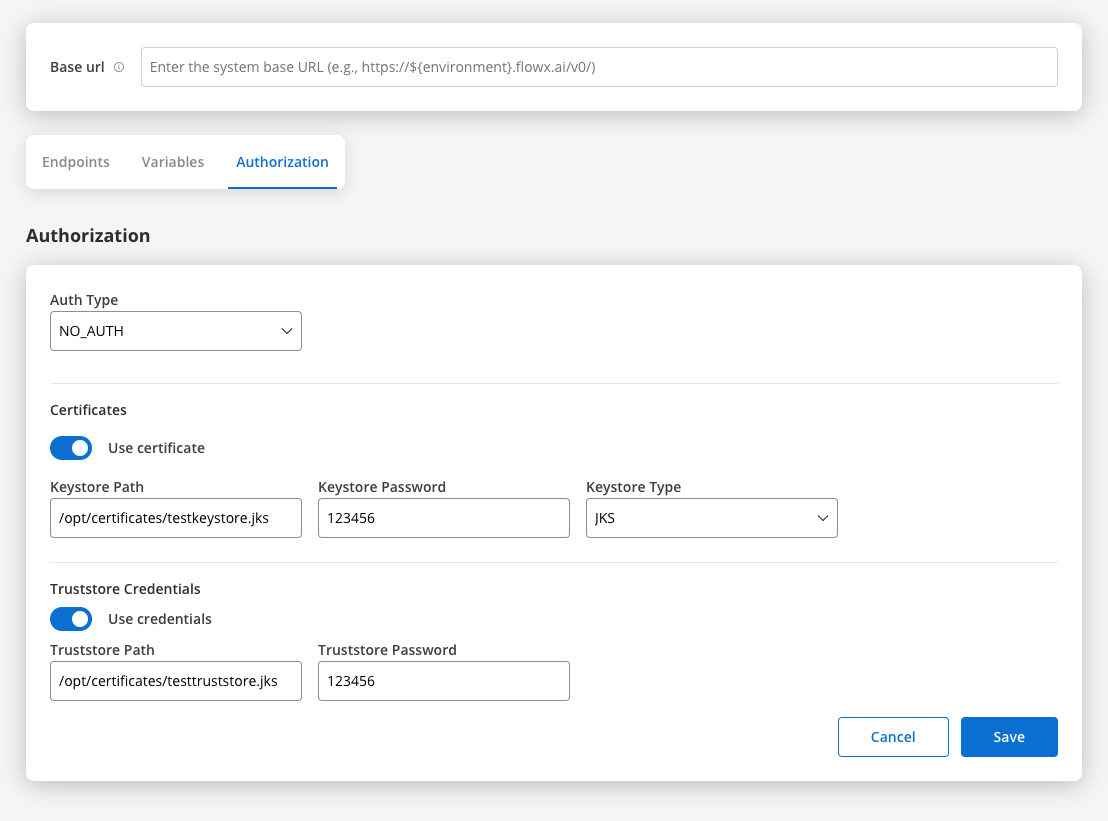
Certificates
You might want to access another external system that require a certificate to do that. Use this setup to configure the secure communication with the system. It includes paths to both a Keystore (which holds the client certificate) and a Truststore (which holds trusted certificates). You can toggle these features based on the security requirements of the integration.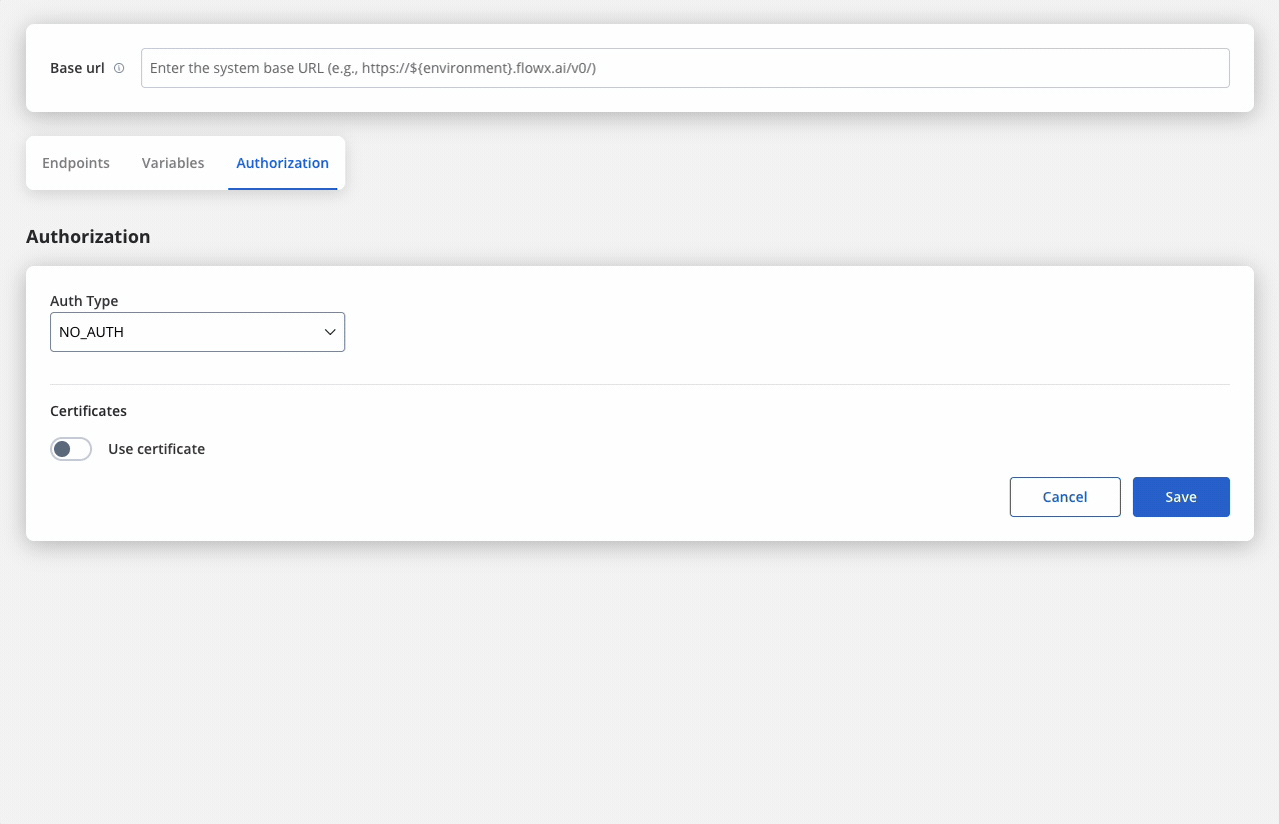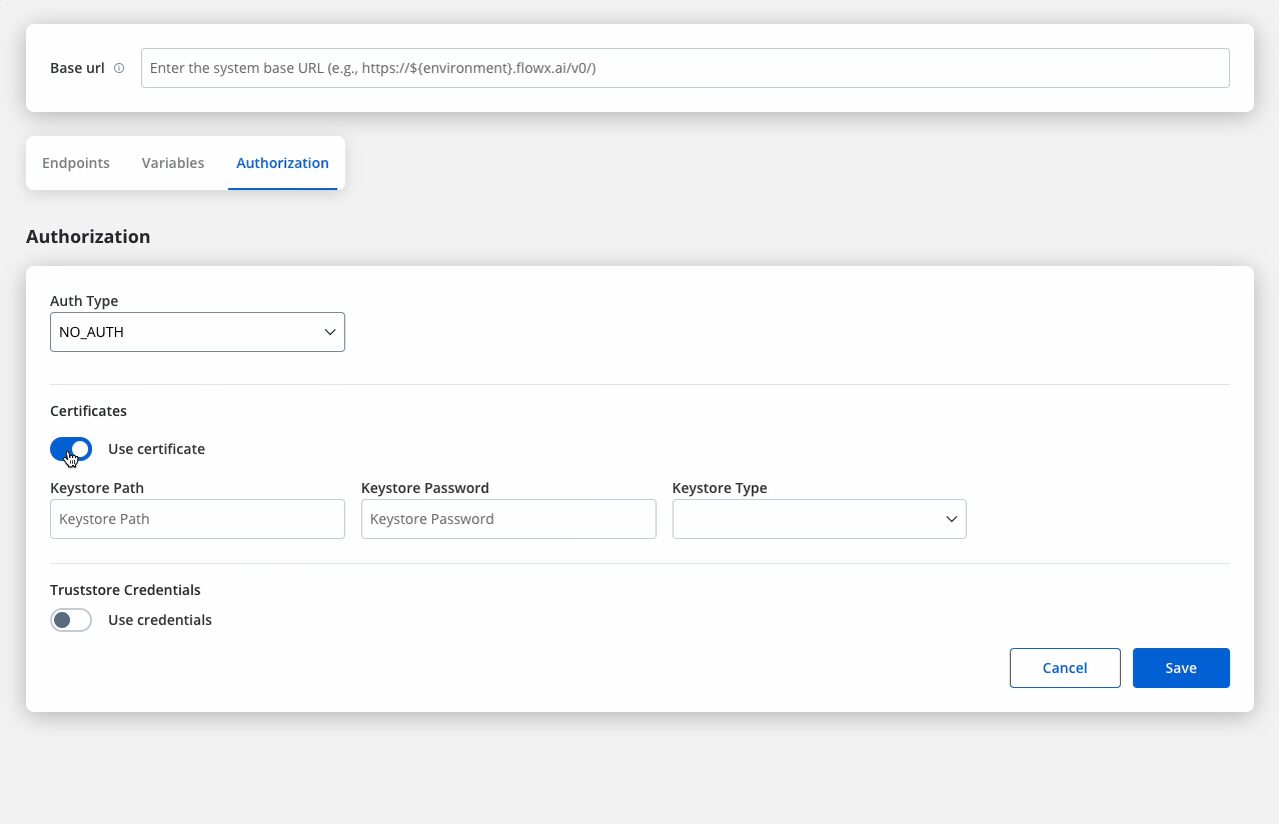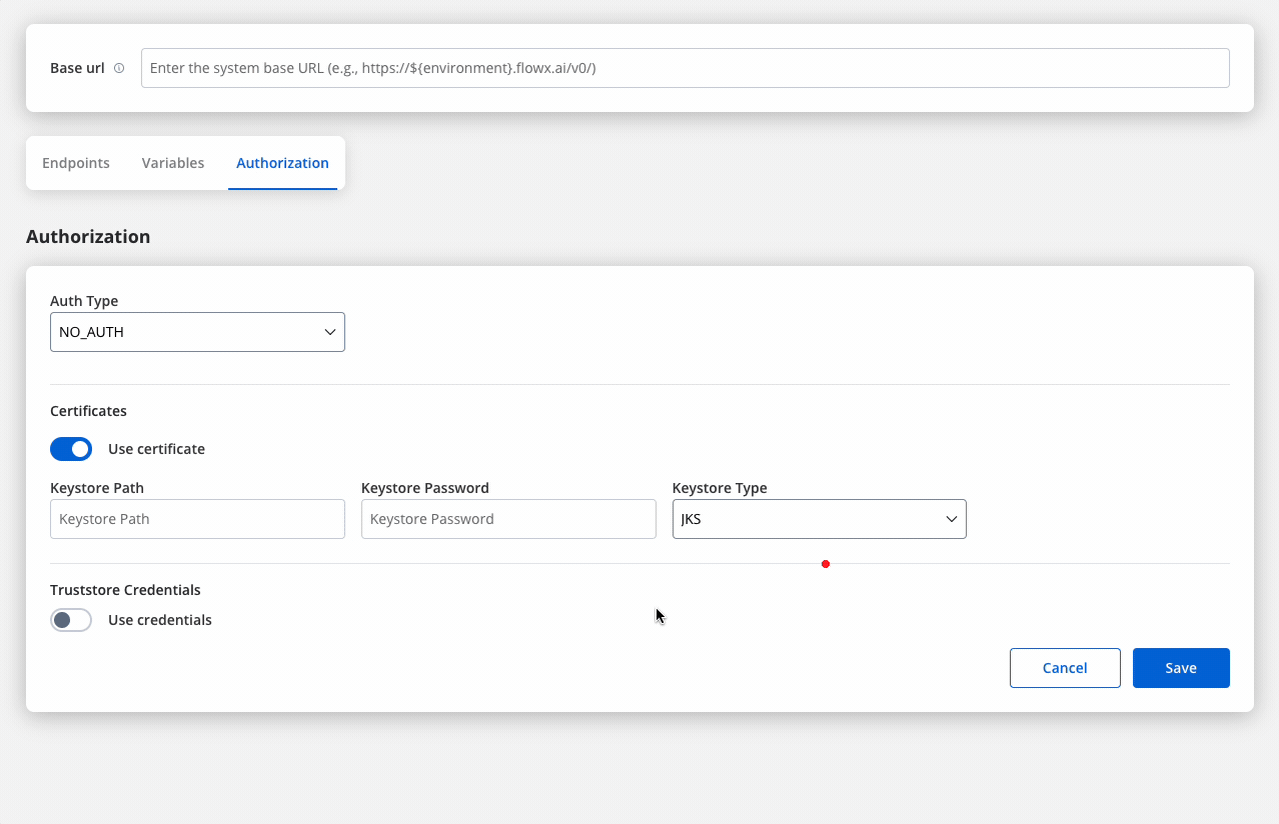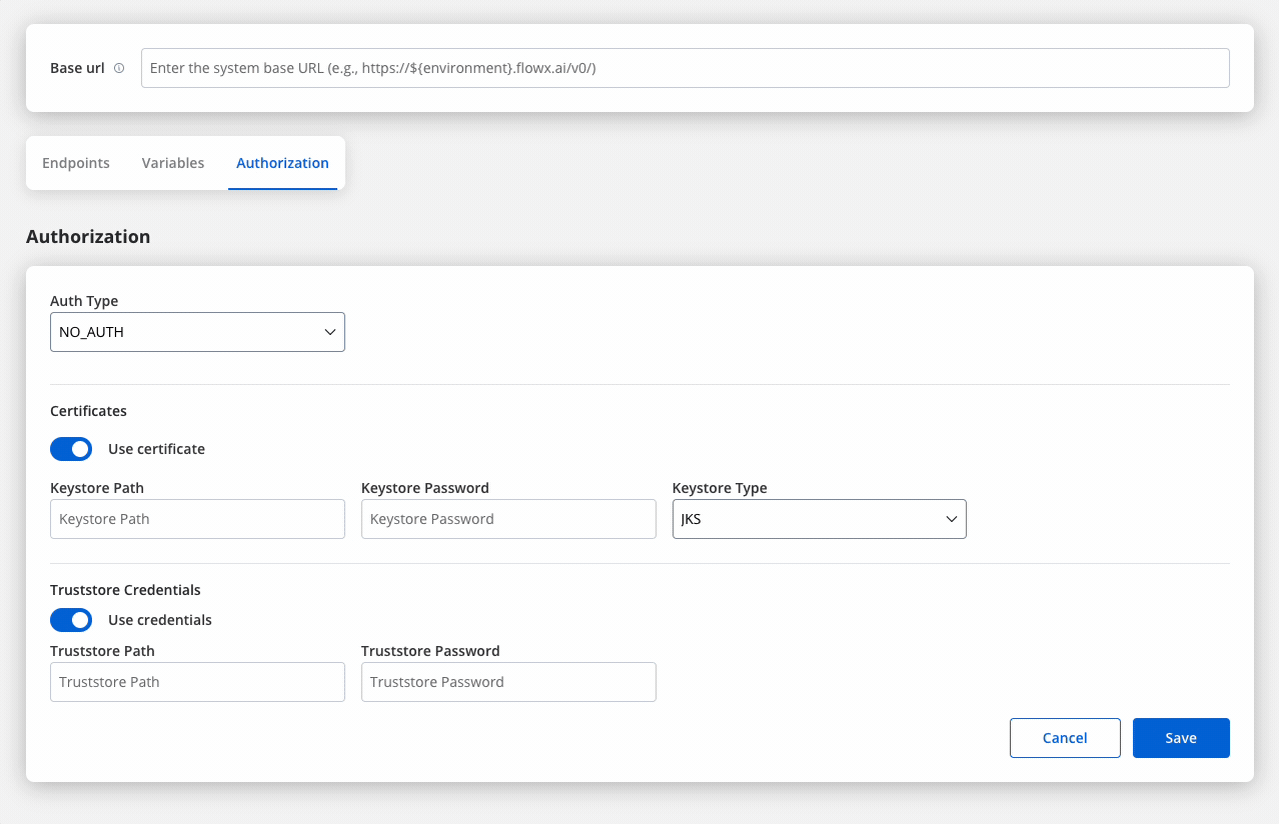
- Keystore Path: Specifies the file path to the keystore, in this case,
/opt/certificates/testkeystore.jks. The keystore contains the client certificate used for securing the connection. - Keystore Password: The password used to unlock the keystore.
- Keystore Type: The format of the keystore, JKS or PKCS12, depending on the system requirements.
- Truststore Path: The file path is set to
/opt/certificates/testtruststore.jks, specifying the location of the truststore that holds trusted certificates. - Truststore Password: Password to access the truststore.
Workflows
A workflow defines a series of tasks and processes to automate system integrations. Within the Integration Designer, workflows can be configured using different components to ensure efficient data exchange and process orchestration.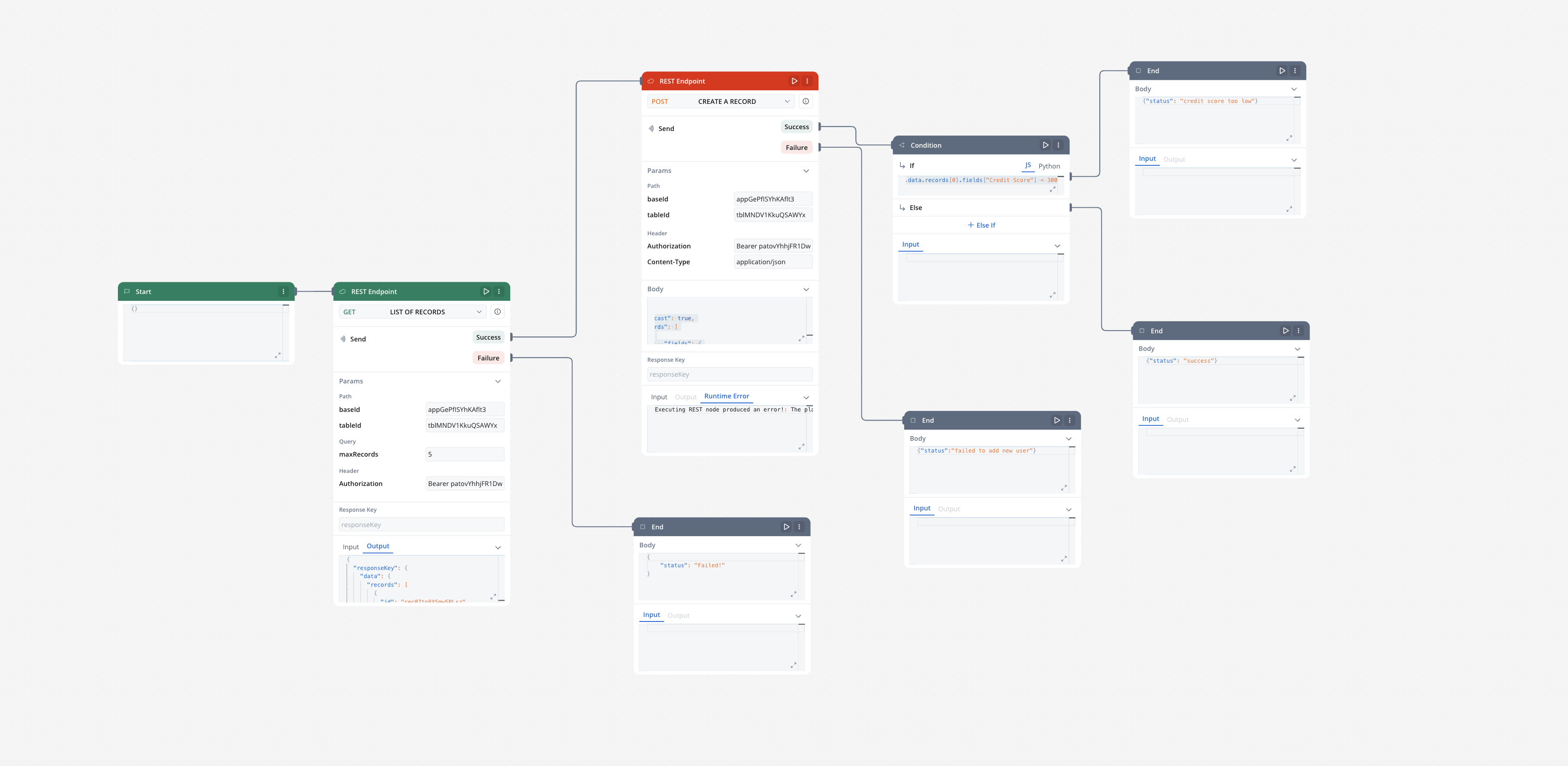
Creating a workflow
- Navigate to Workflow Designer:
- In FlowX.AI Designer to Projects -> Your application -> Integrations -> Workflows.
- Create a New Workflow, provide a name and description, and save it.
- Start to design your workflow by adding nodes to represent the steps of your workflow:
- Start Node: Defines where the workflow begins and also defines the input parameter for subsequent nodes.
- REST endpoint nodes: Add REST API calls for fetching or sending data.
- Fork nodes (conditions): Add conditional logic for decision-making.
- Data mapping nodes (scripts): Write custom scripts in JavaScript or Python.
- End Nodes: Capture output data as the completed workflow result, ensuring the process concludes with all required information.
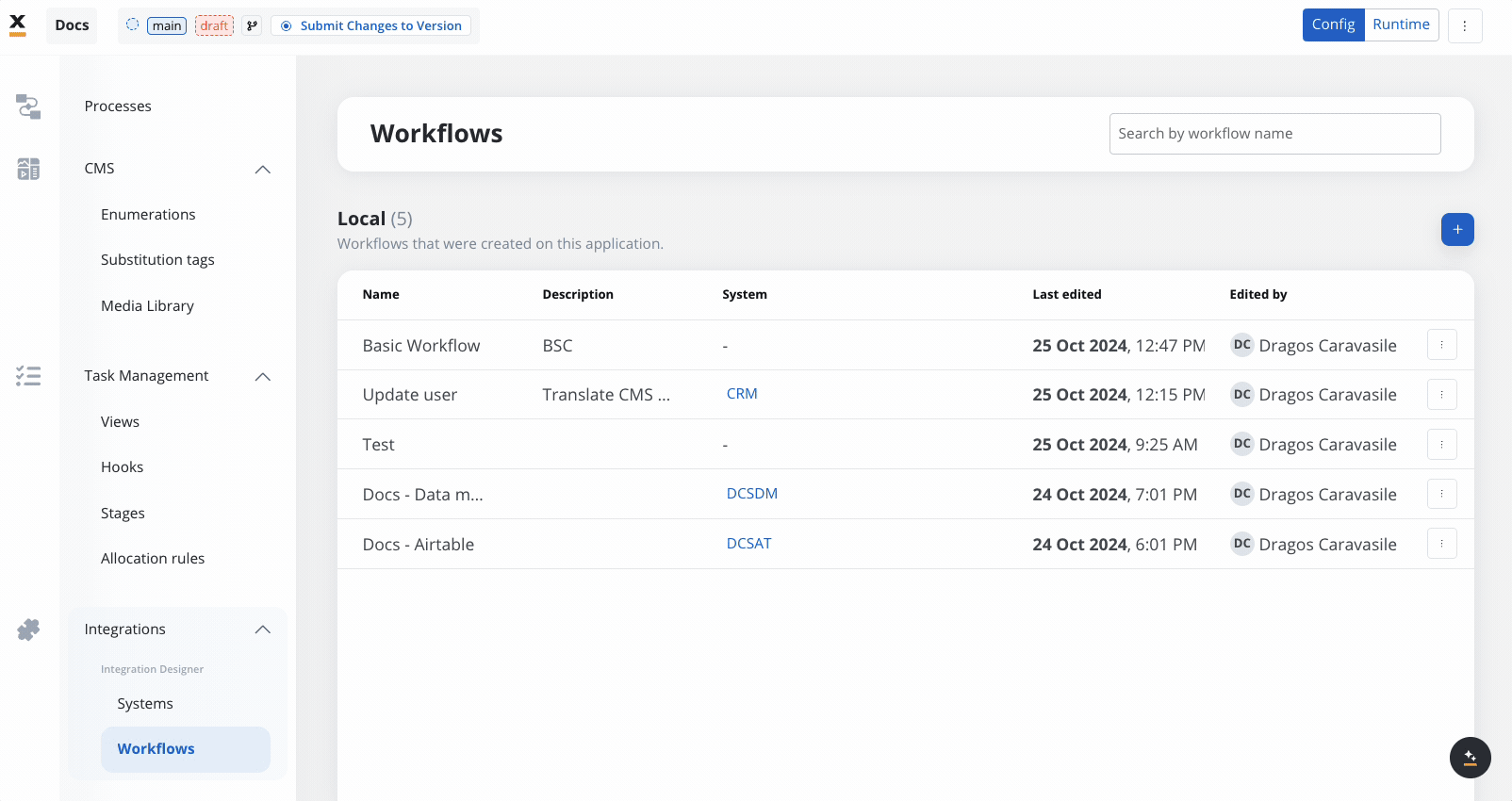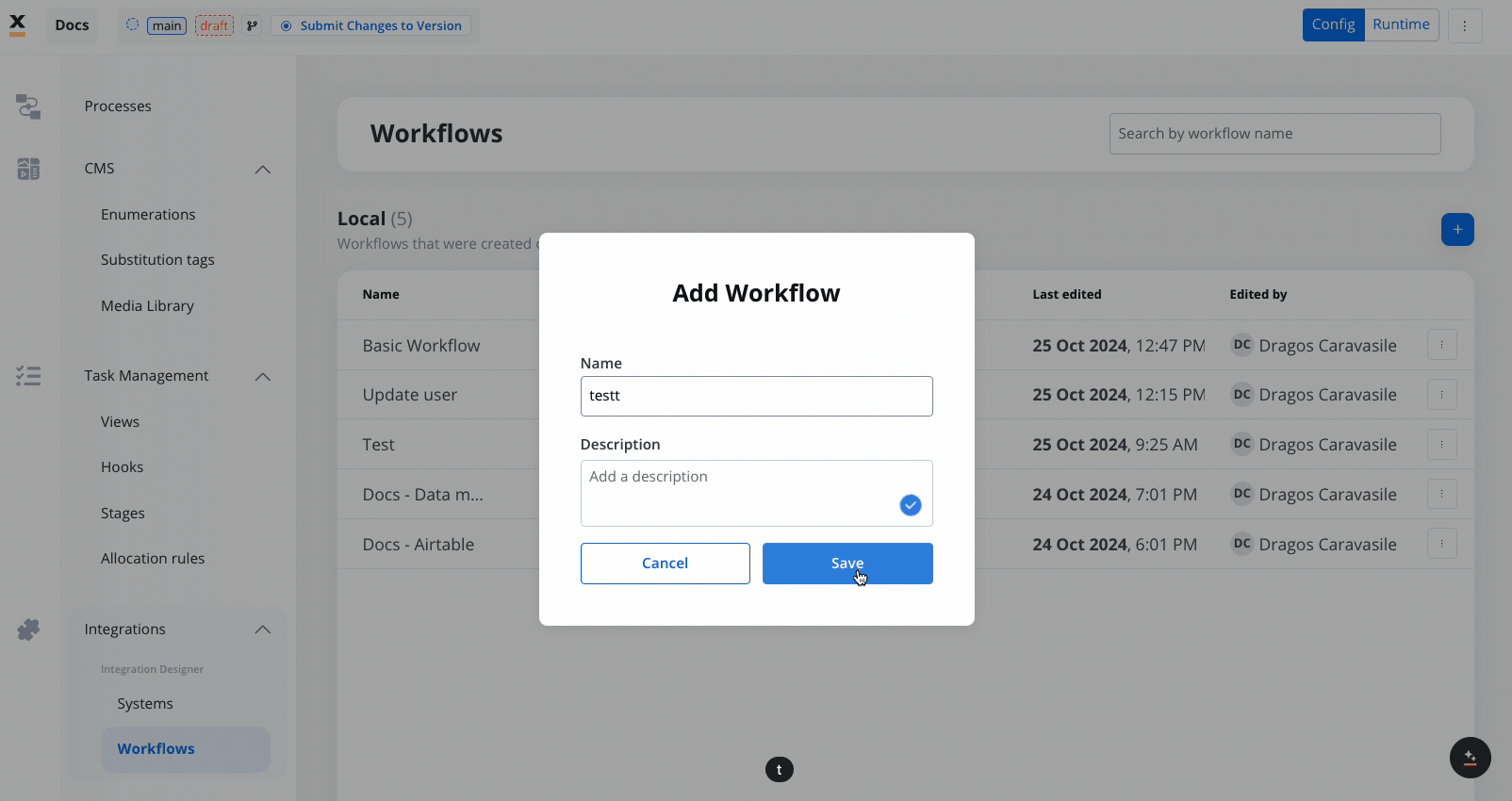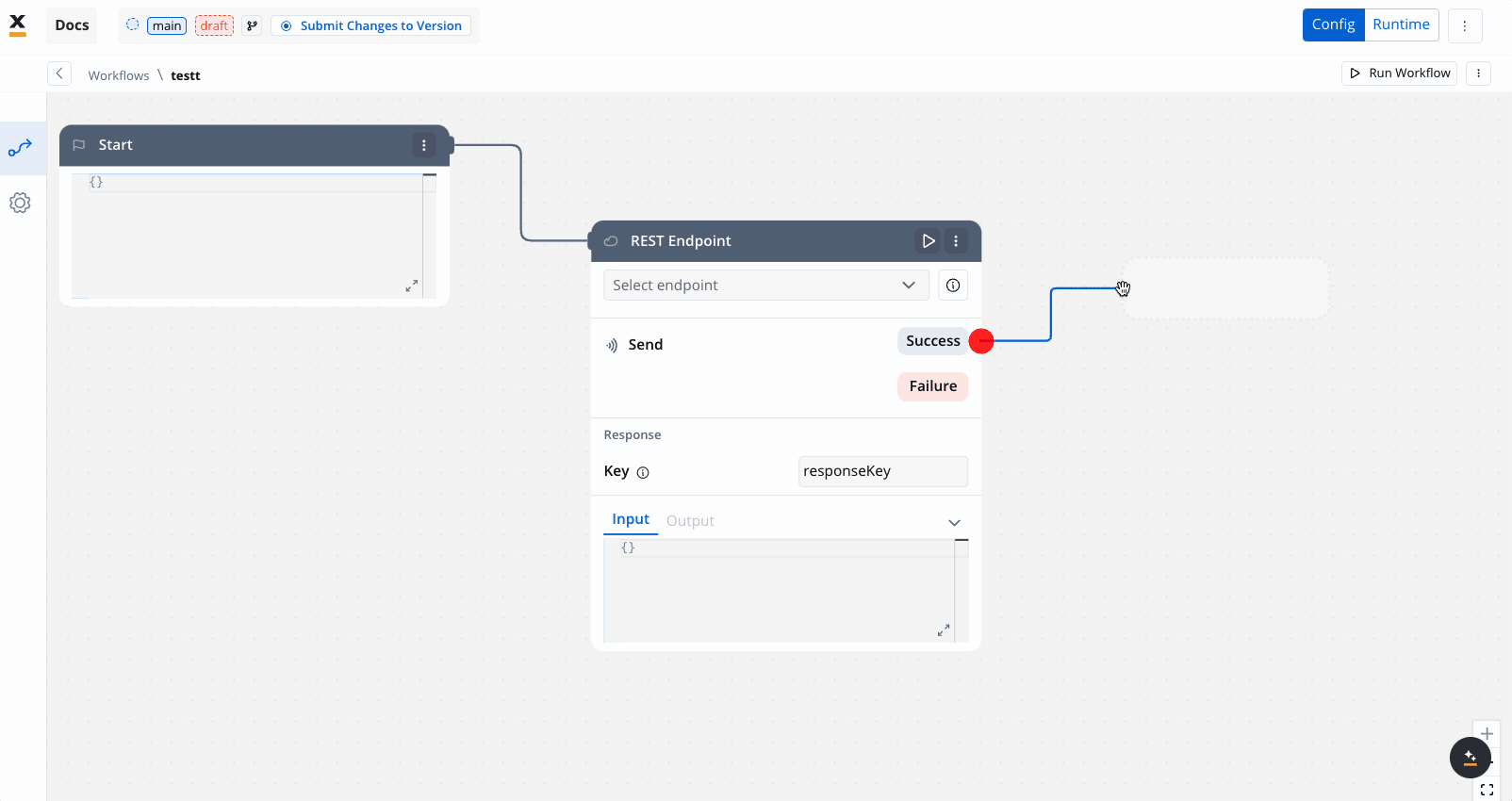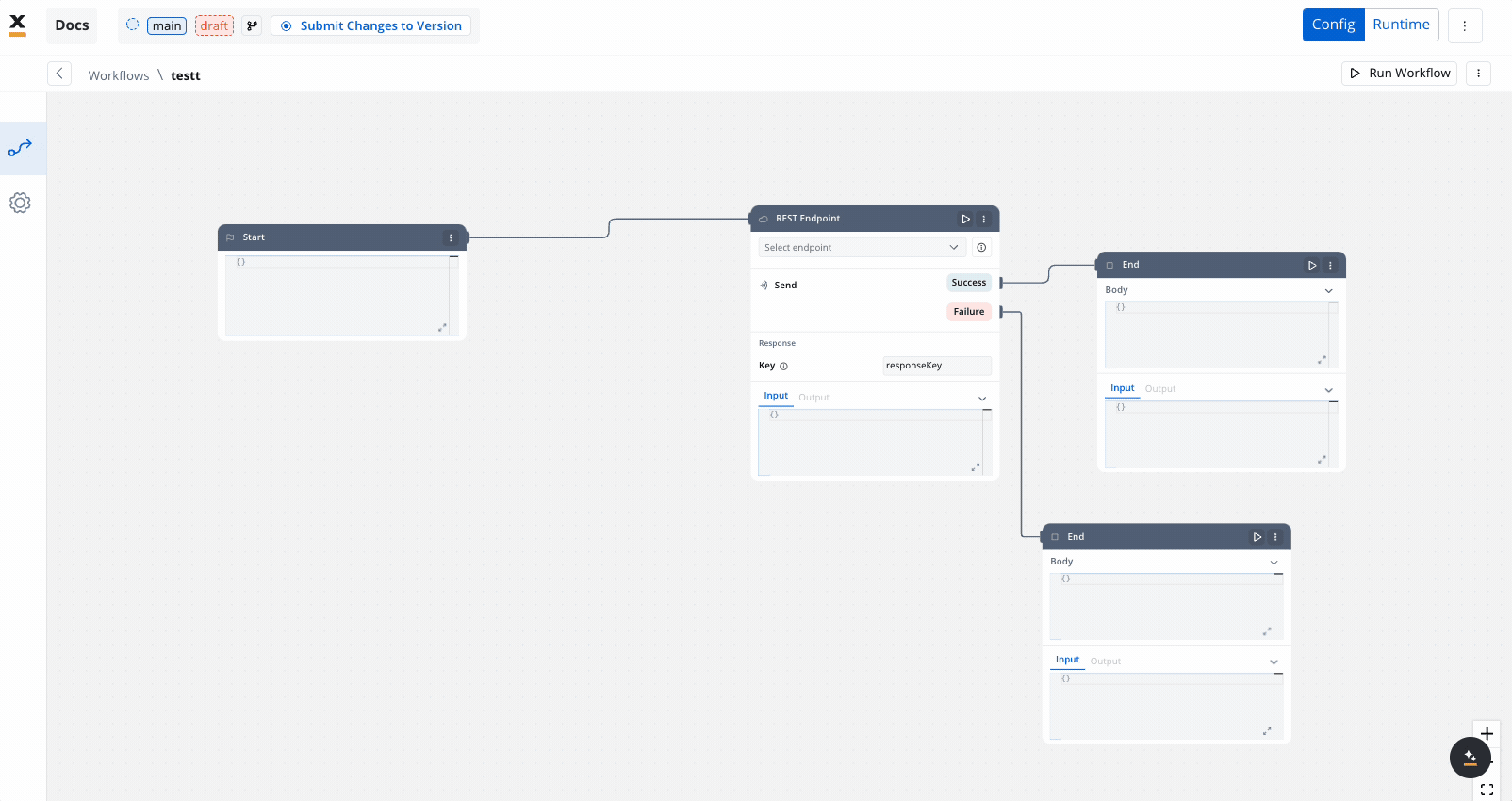
Workflow nodes
Users can visually build workflows by adding various nodes, including:- Workflow start node
- REST endpoint nodes
- Data mapping nodes (scripts)
- Fork nodes (conditions)
- End node
Worflow start node
The Start node is the default and mandatory first node in any workflow. It initializes the workflow and defines the input parameters defined on it for subsequent nodes.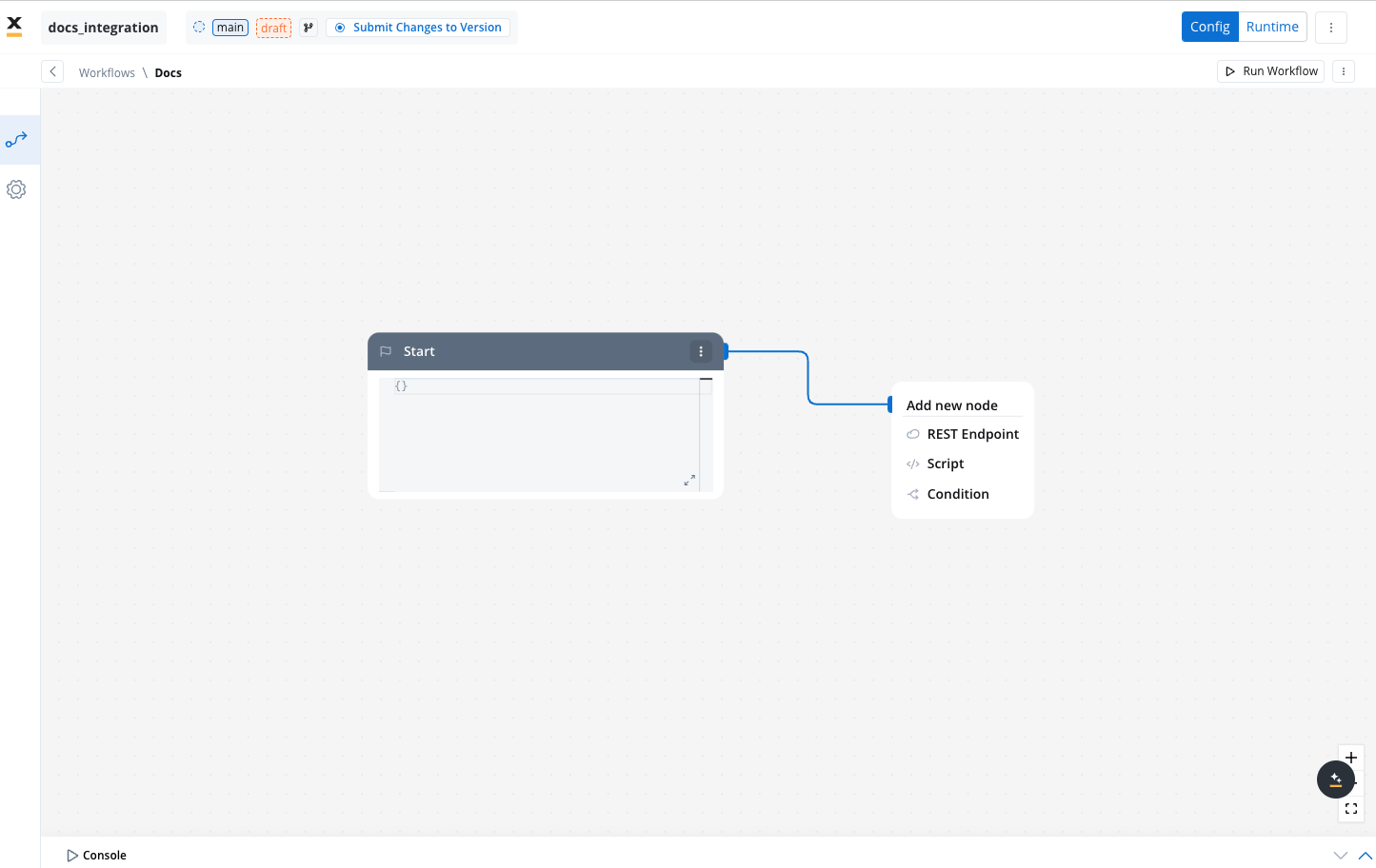
Make sure the data is also mapped in the Start Integration Workflow node action where you have the data.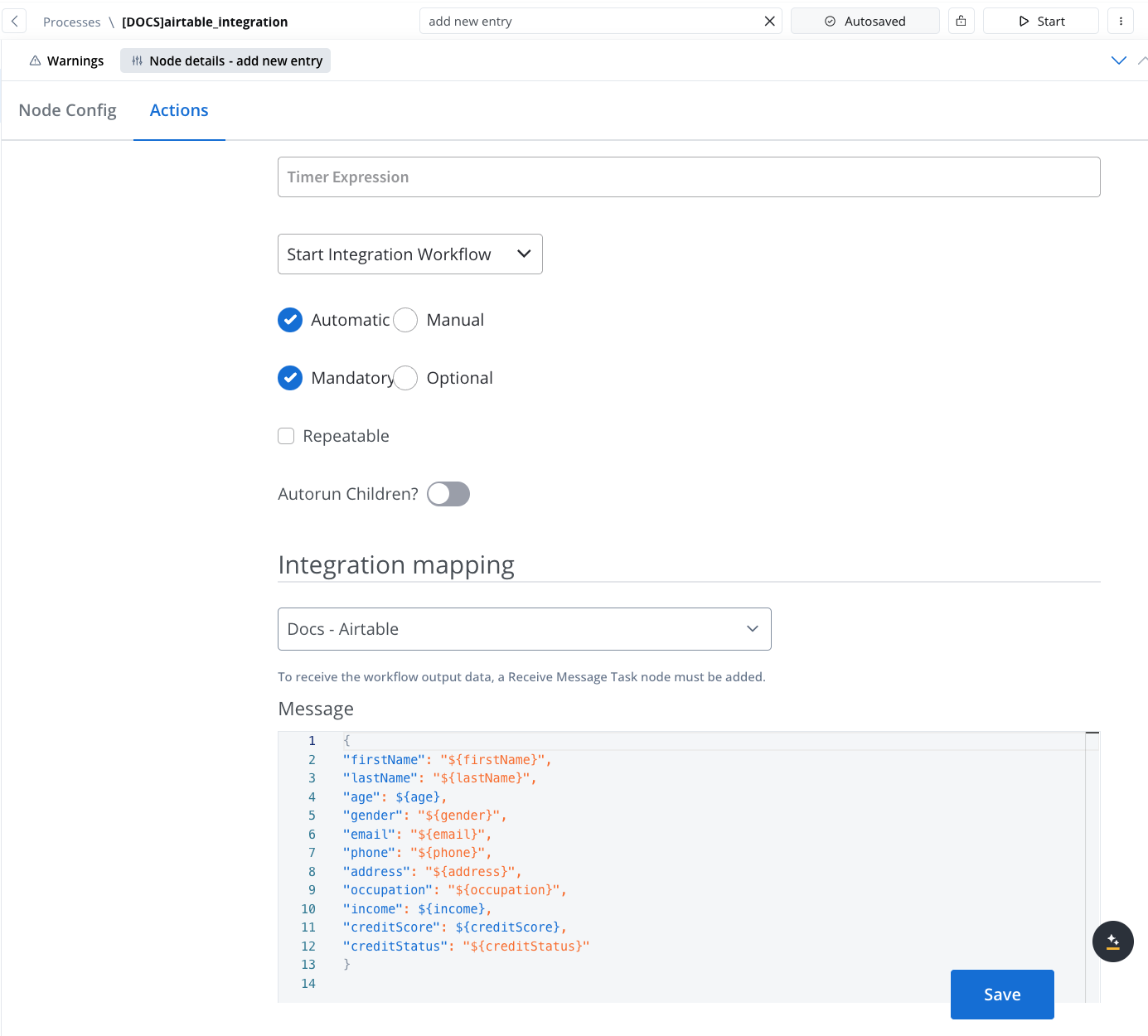
Only one Start node is allowed per workflow. The Start node is always the first node in the workflow and cannot have any incoming connections. Its sole function is to provide the initial data for the workflow.
The Start node cannot be altered in name, nor can it be deleted from the workflow.
REST endpoint nodes
The REST endpoint node enables communication with external systems to retrieve or update data by making REST API calls. It supports multiple methods like GET, POST, PUT, PATCH, and DELETE. Endpoints are selected via a dropdown menu, where available endpoints are grouped by the system they belong to.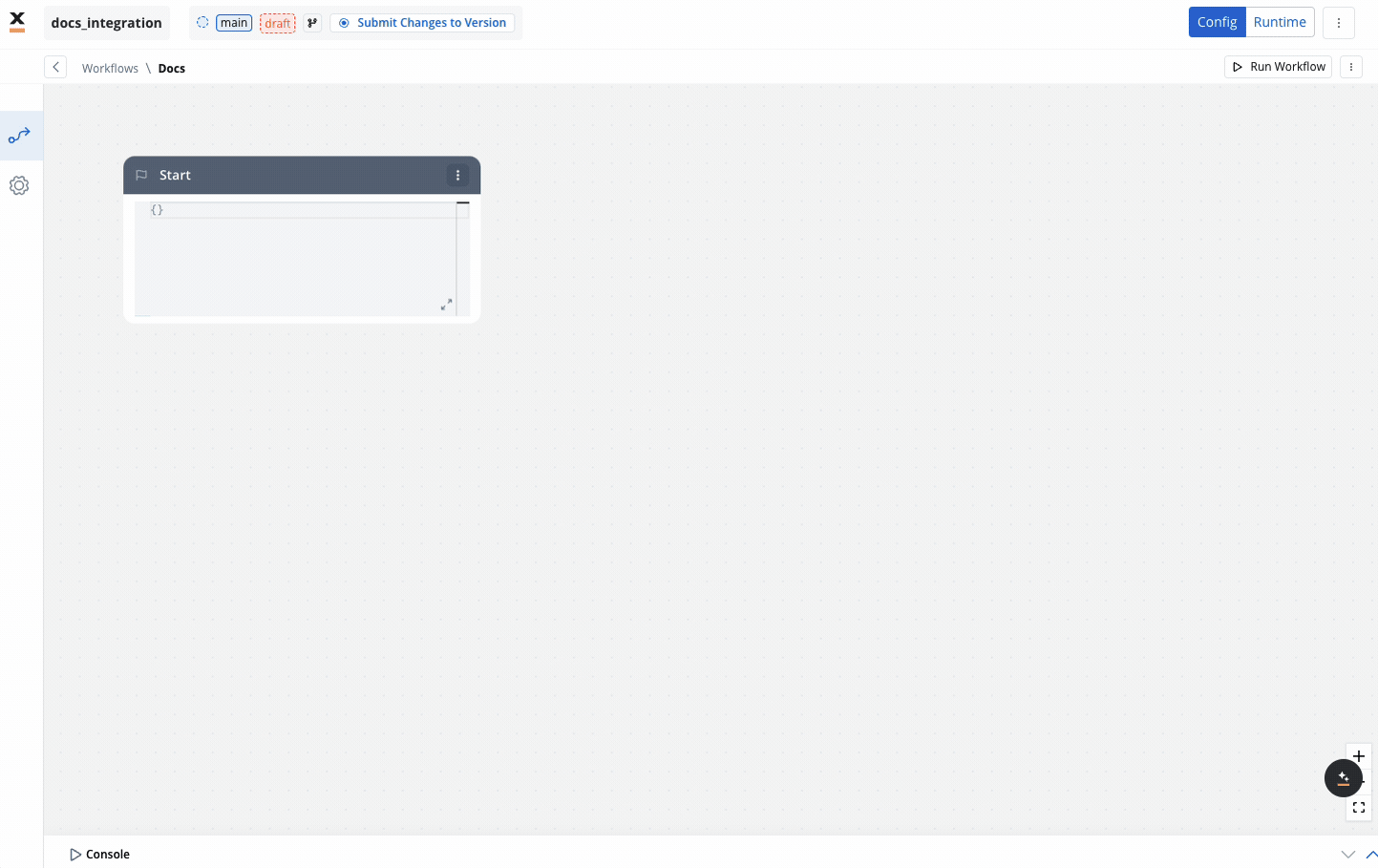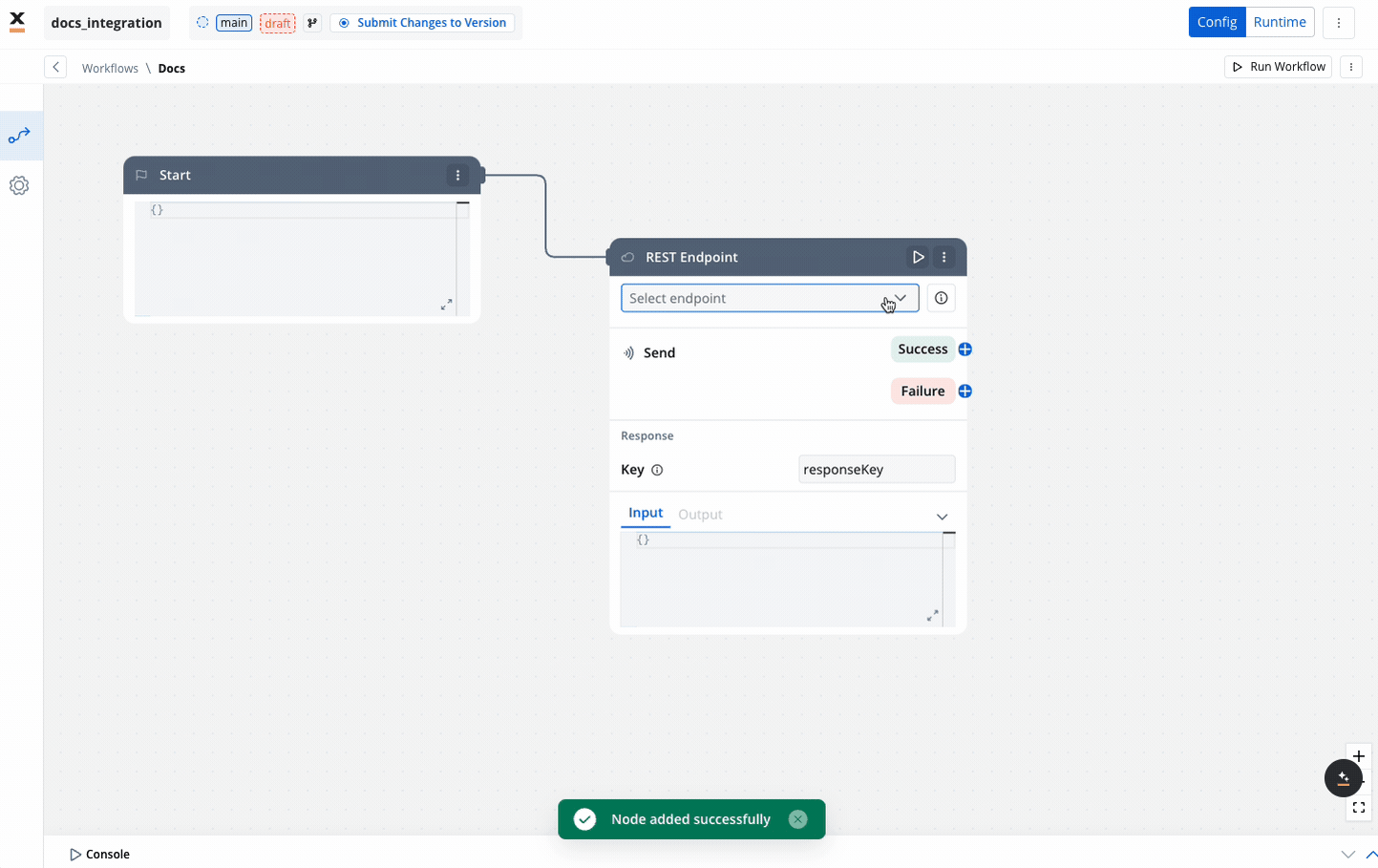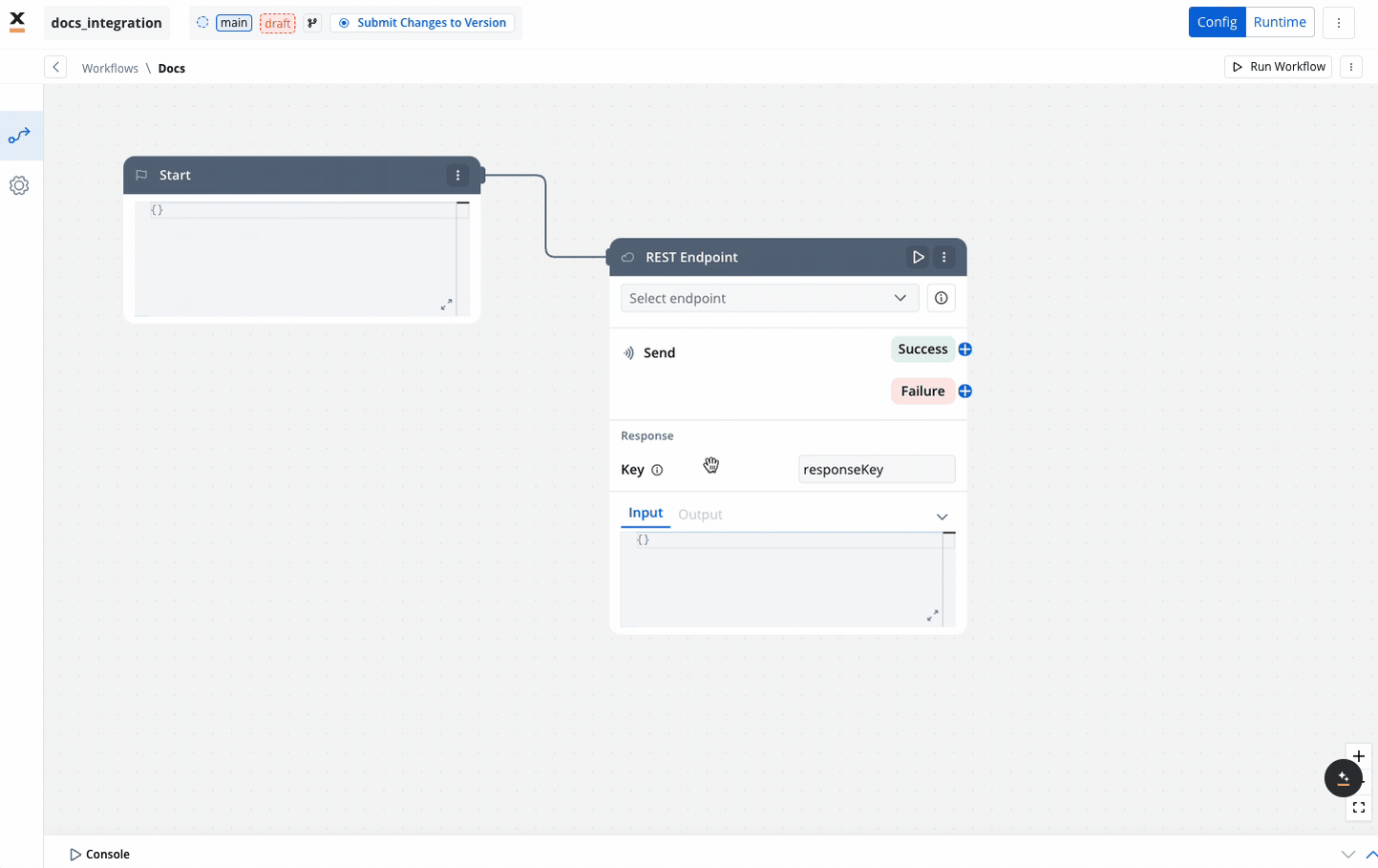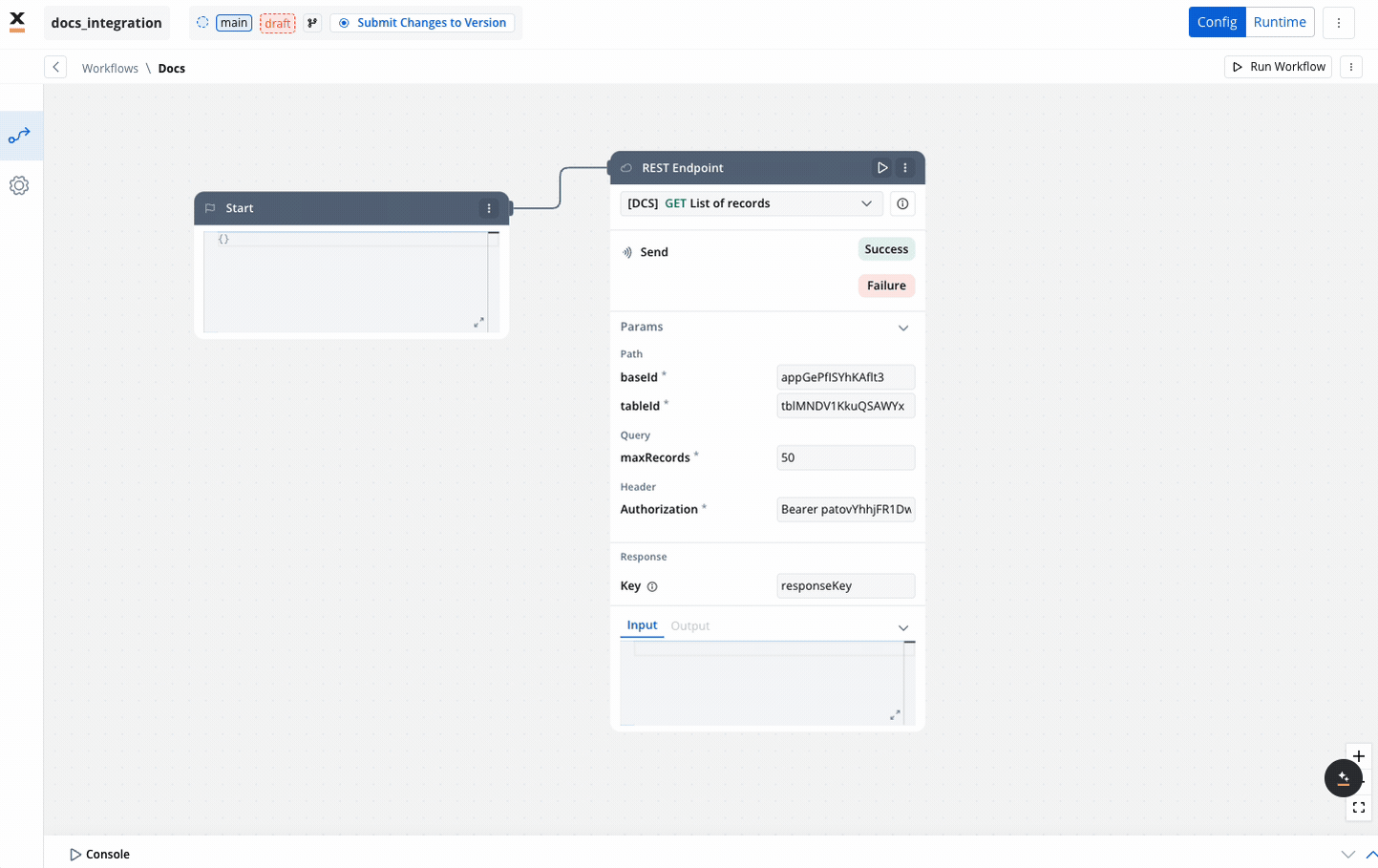
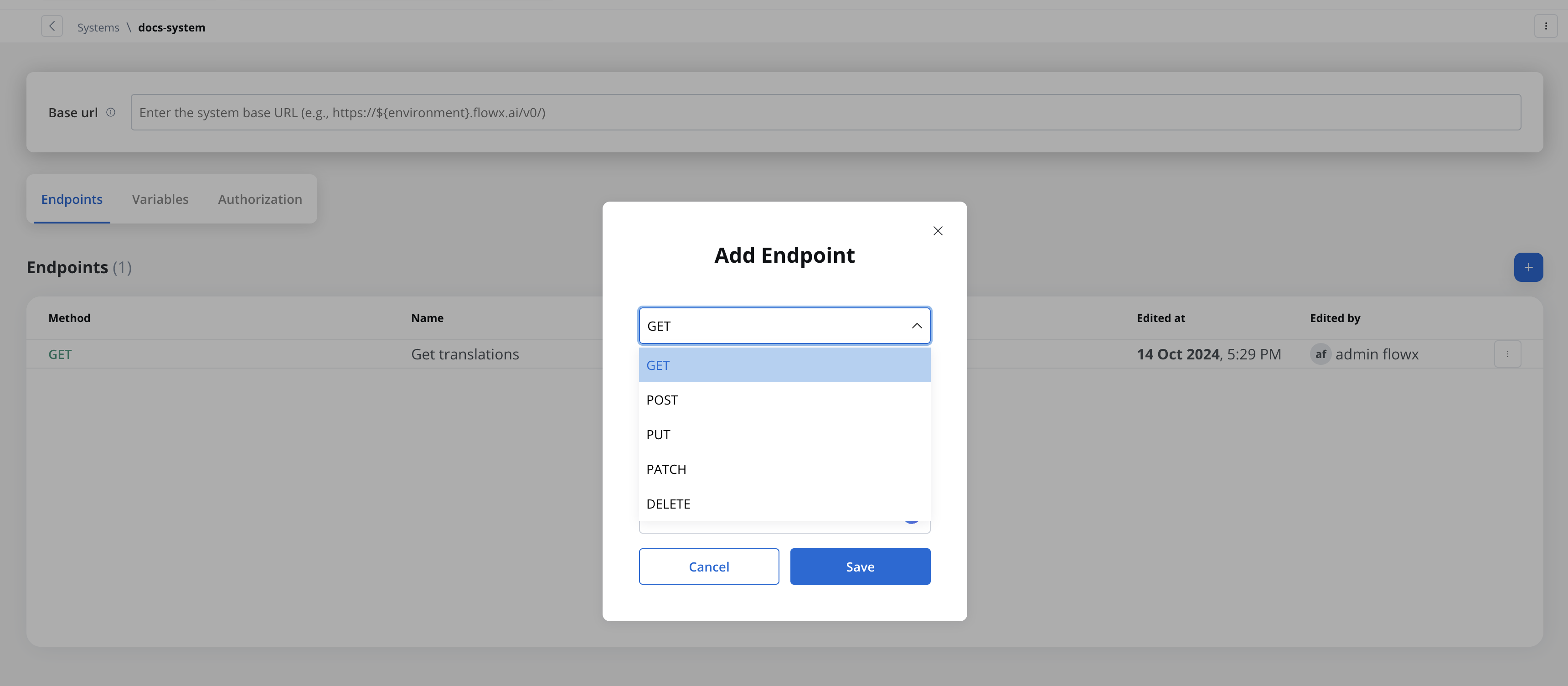
You can include multiple REST endpoint nodes within the same workflow, allowing for integration with various systems or endpoints.
Unlike some nodes, the Endpoint Call node can be run independently, making it possible to test the connection or retrieve data without executing the entire workflow.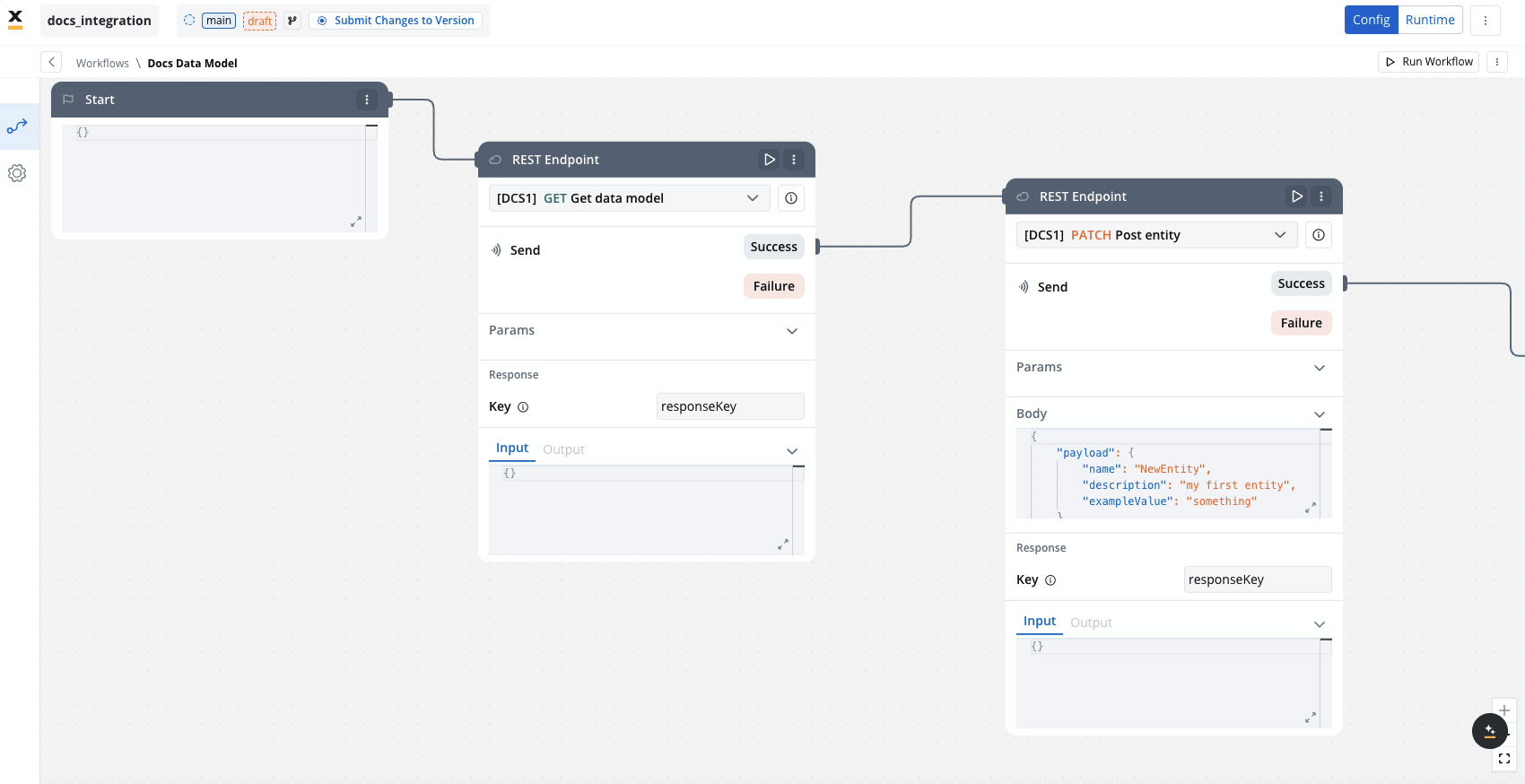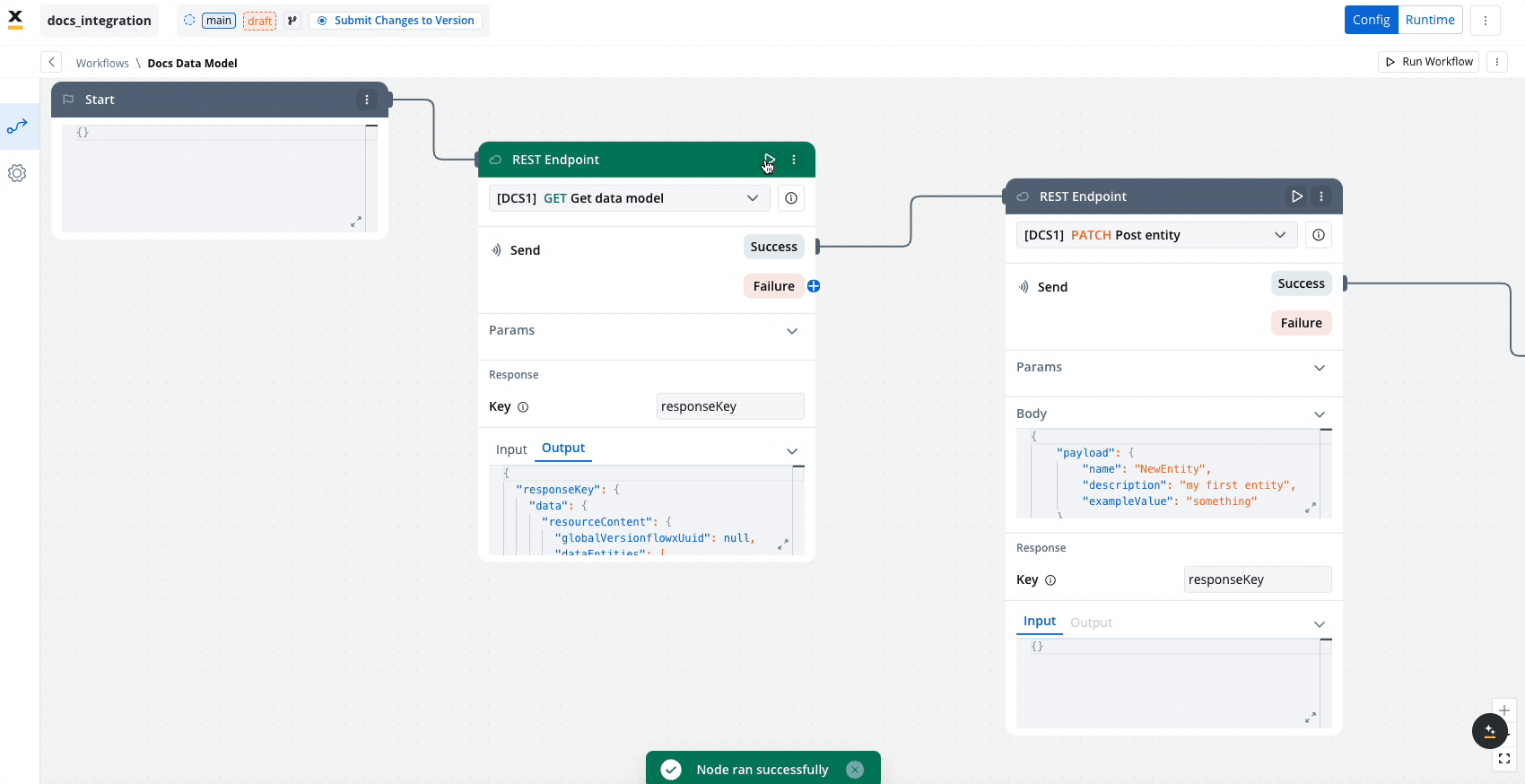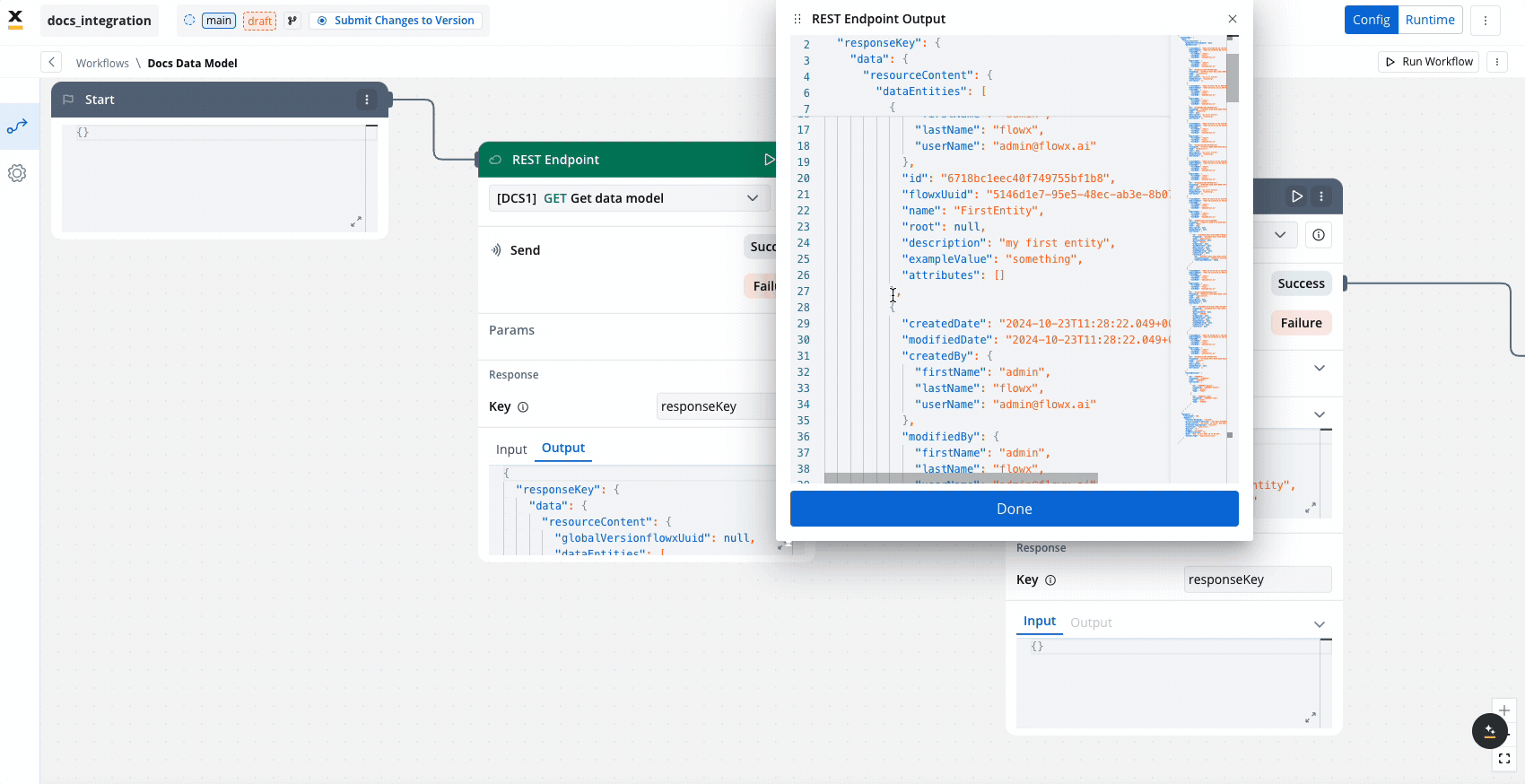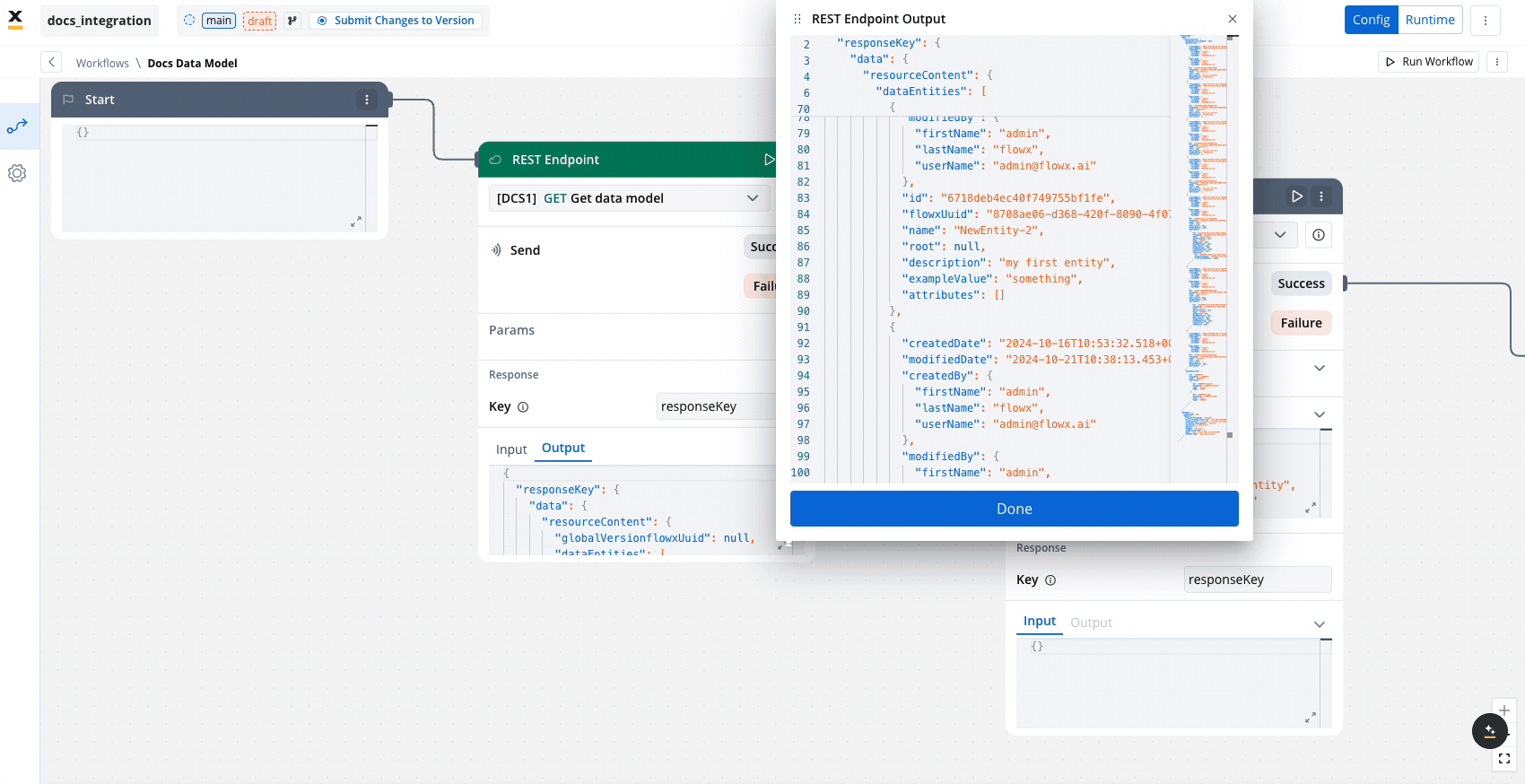
- Params:
- Response key: The response from the endpoint node, including both data and metadata, is organized under a predefined response key.
- Input:
- This tab contains read-only JSON data that is automatically populated with the output from the previous node in the workflow.
- Output:
- It displays the API response in JSON format.
Condition (fork) nodes
The Condition node evaluates incoming data from a connected node based on defined logical conditions(if/else if with). It directs the workflow along different paths depending on whether the condition evaluates to TRUE or FALSE.Defining Conditions in JavaScript or PythonLogical conditions for the Condition Node can be written in either JavaScript or Python, depending on the requirements of your workflow.
- If the condition evaluates to TRUE, the workflow follows the If path.
- If the condition evaluates to FALSE, it follows the Else if path.
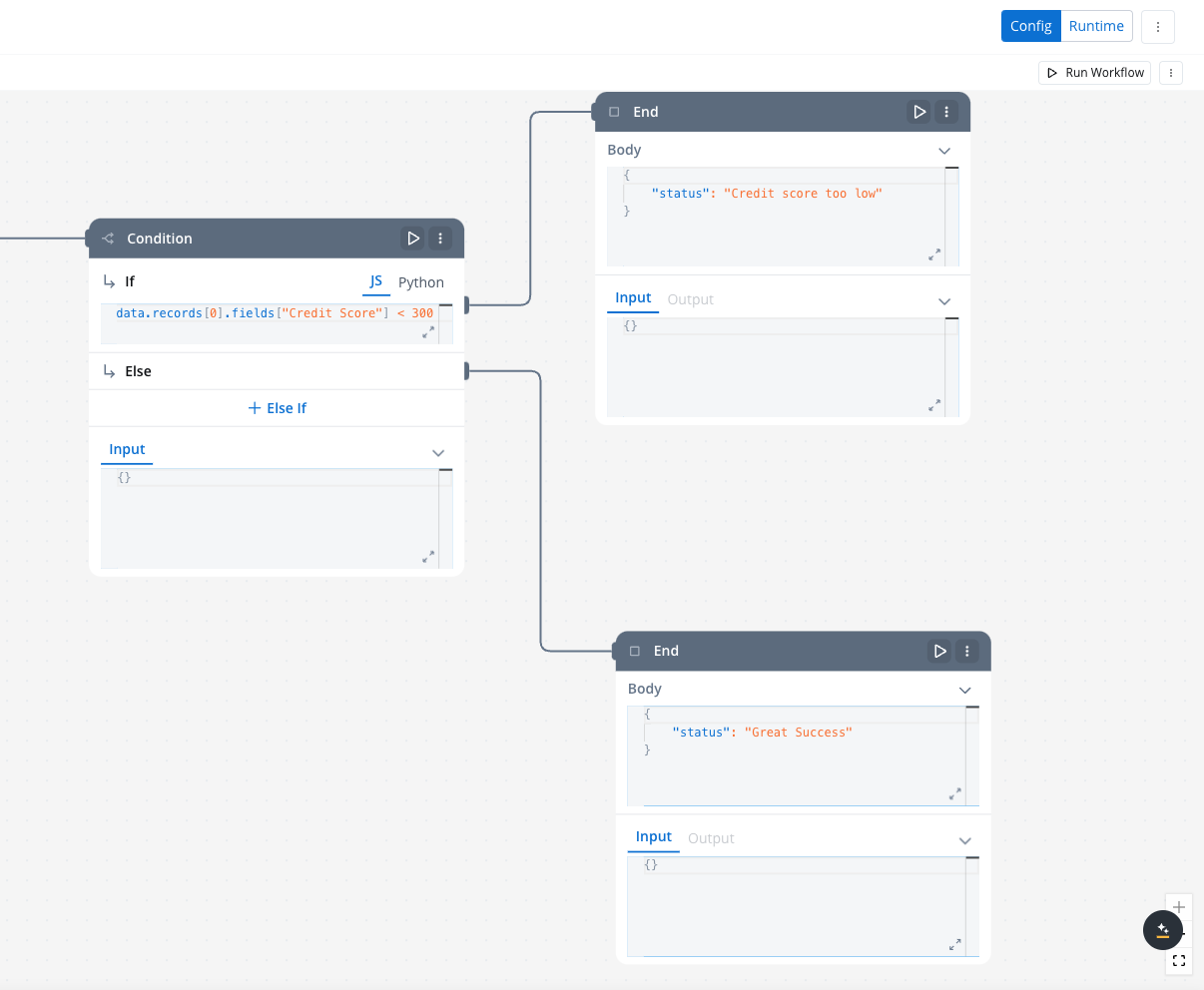
Data mapping nodes (scripts)
The Script node allows you to transform and map data between different systems during workflow execution by writing and executing custom code in JavaScript or Python. It enables complex data transformations and logic to be applied directly within the workflow.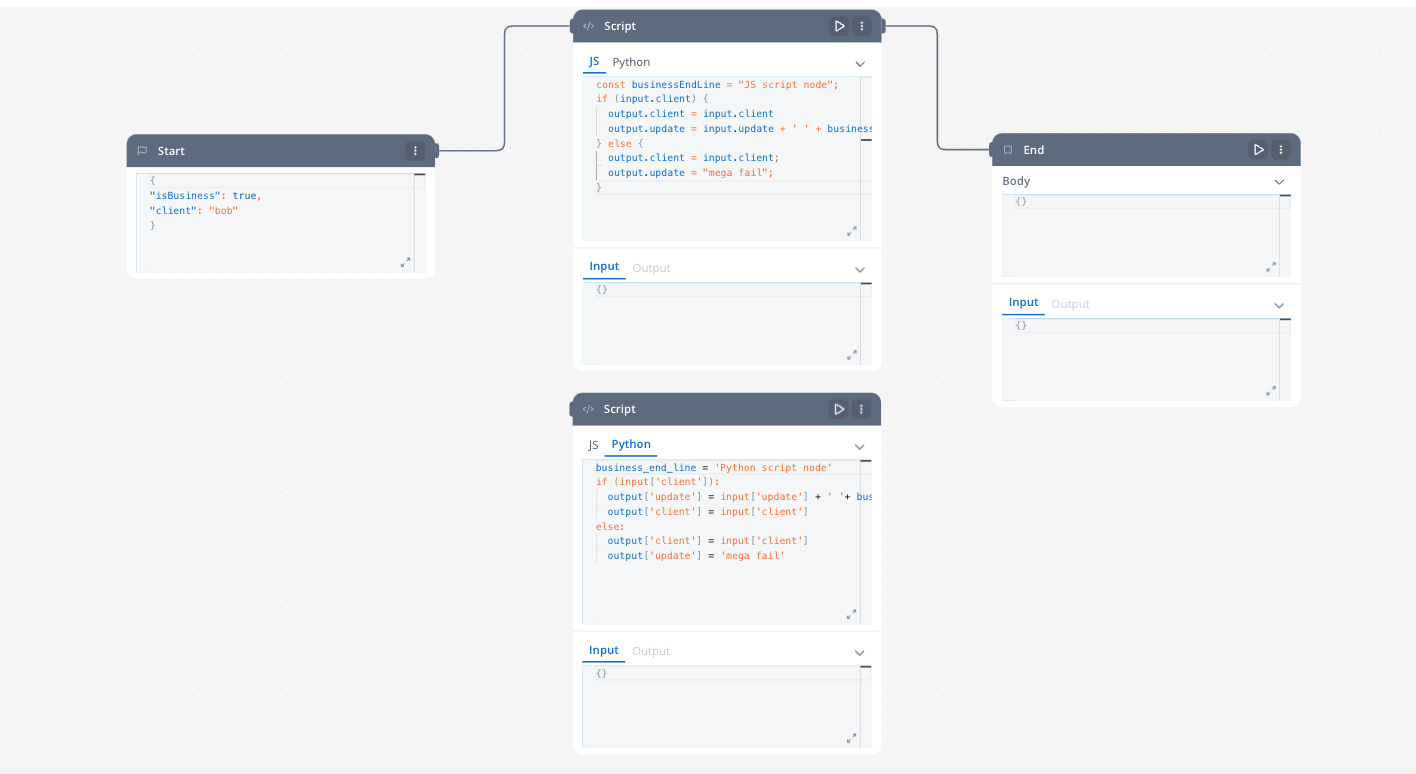
End node
The End node signifies the termination of a workflow’s execution. It collects the final output and completes the workflow process.Multiple End nodes can be included within a single workflow. This allows the workflow to have multiple possible end points based on different execution paths.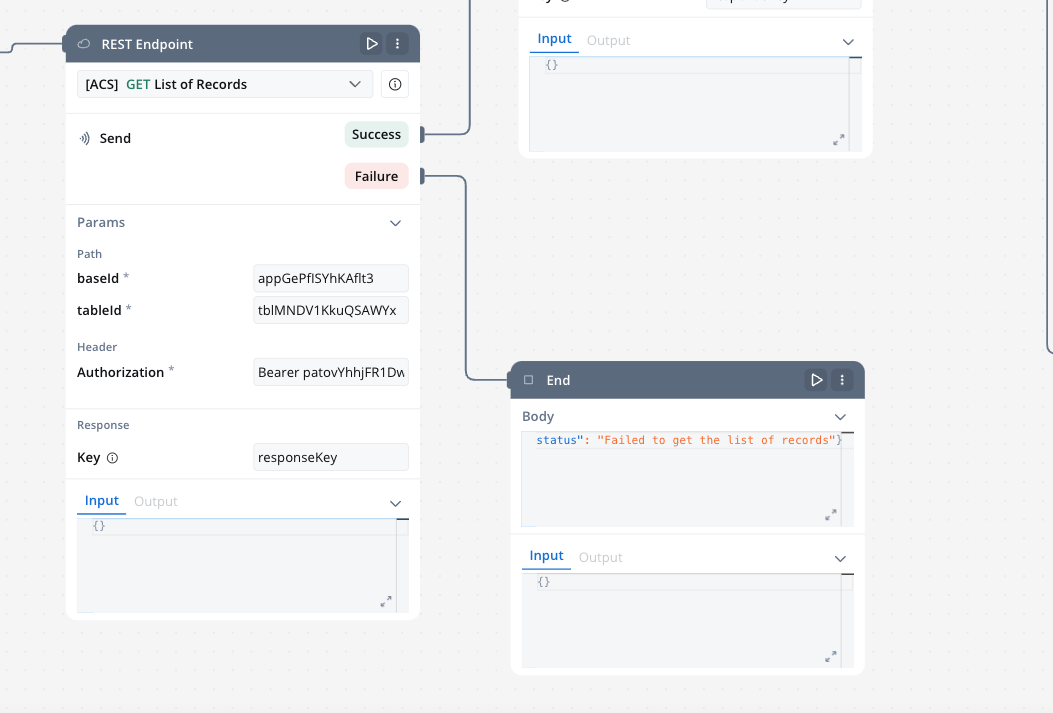
Testing the workflow
Debugging
Use the integrated console after running each workflow (either if you test your workflow in the workflow designer or in a process definition). It provides useful info like logs, input and output data about eacg endpoint and other details like execution time etc.Workflow integration
Integrating workflows into a BPMN process allows for structured handling of tasks like user interactions, data processing, and external system integrations. This is achieved by connecting workflow nodes to User Tasks and Service Tasks using the Start Integration Workflow action.1
Create a BPMN Process
-
Open the FlowX Process Designer:
- Navigate to Projects -> Your application -> Processes.
- Create a new process or edit an existing one.
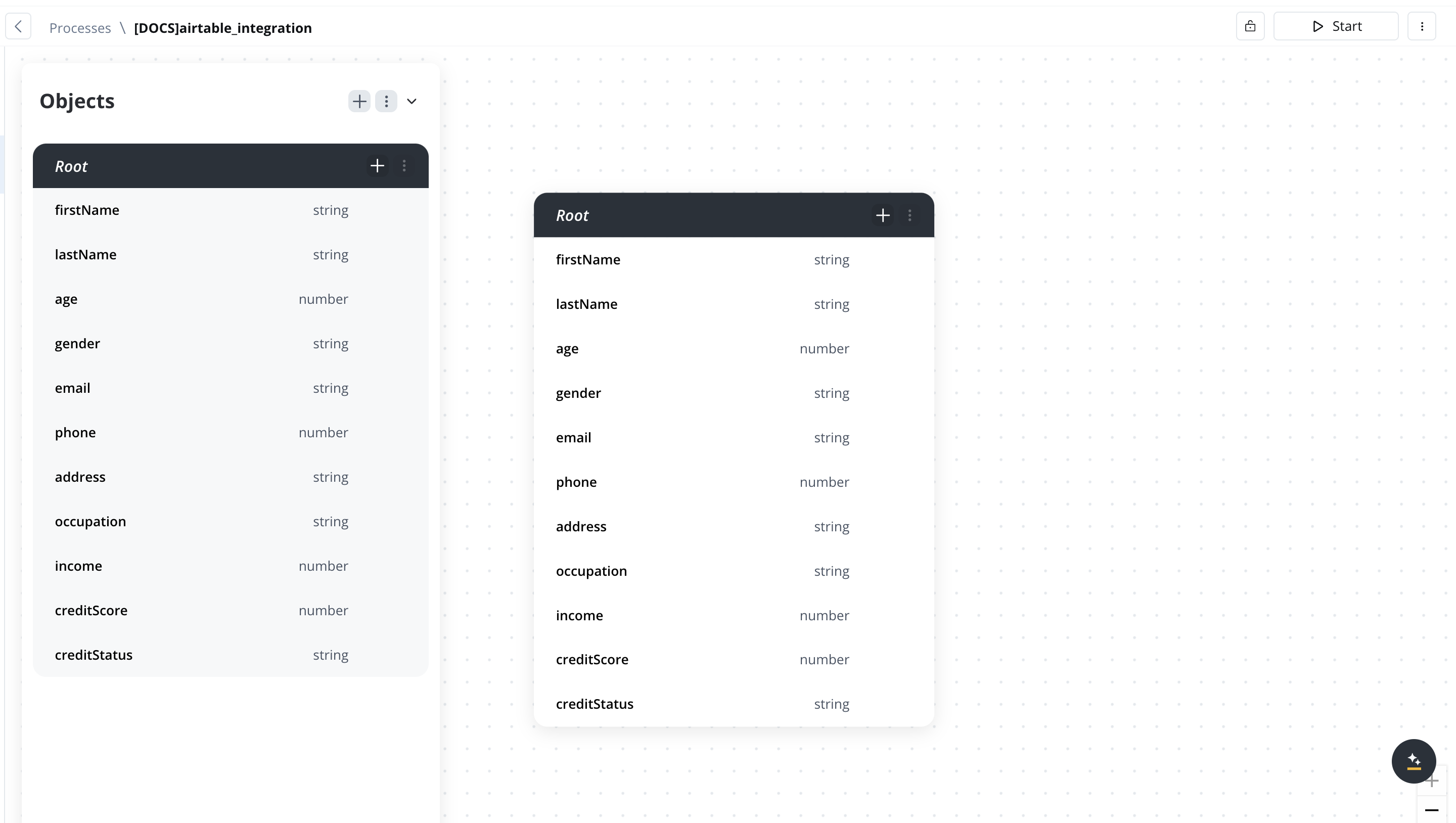
- Define the Data Model:
Needed if you want to send data from your user task to the workflow.
- Establish the data model that will be shared between the process and the workflow.
- Ensure all necessary data fields that the workflow will use are included.
2
Configure a User Task or Service Task
-
Add a Task:
- Insert a User Task or Service Task into your BPMN diagram.
- A User Task requires user input, while a Service Task can trigger automated actions without manual intervention.
-
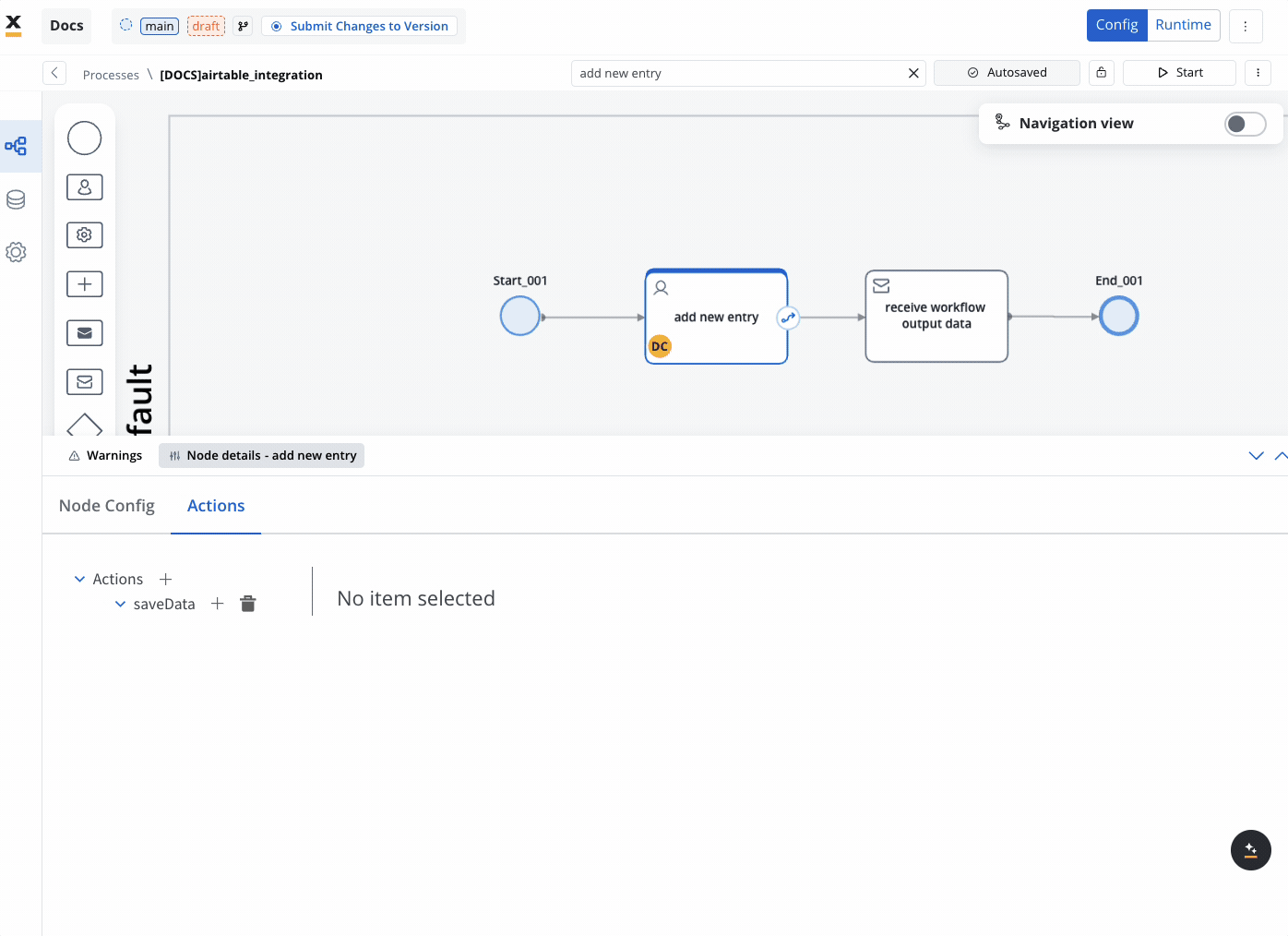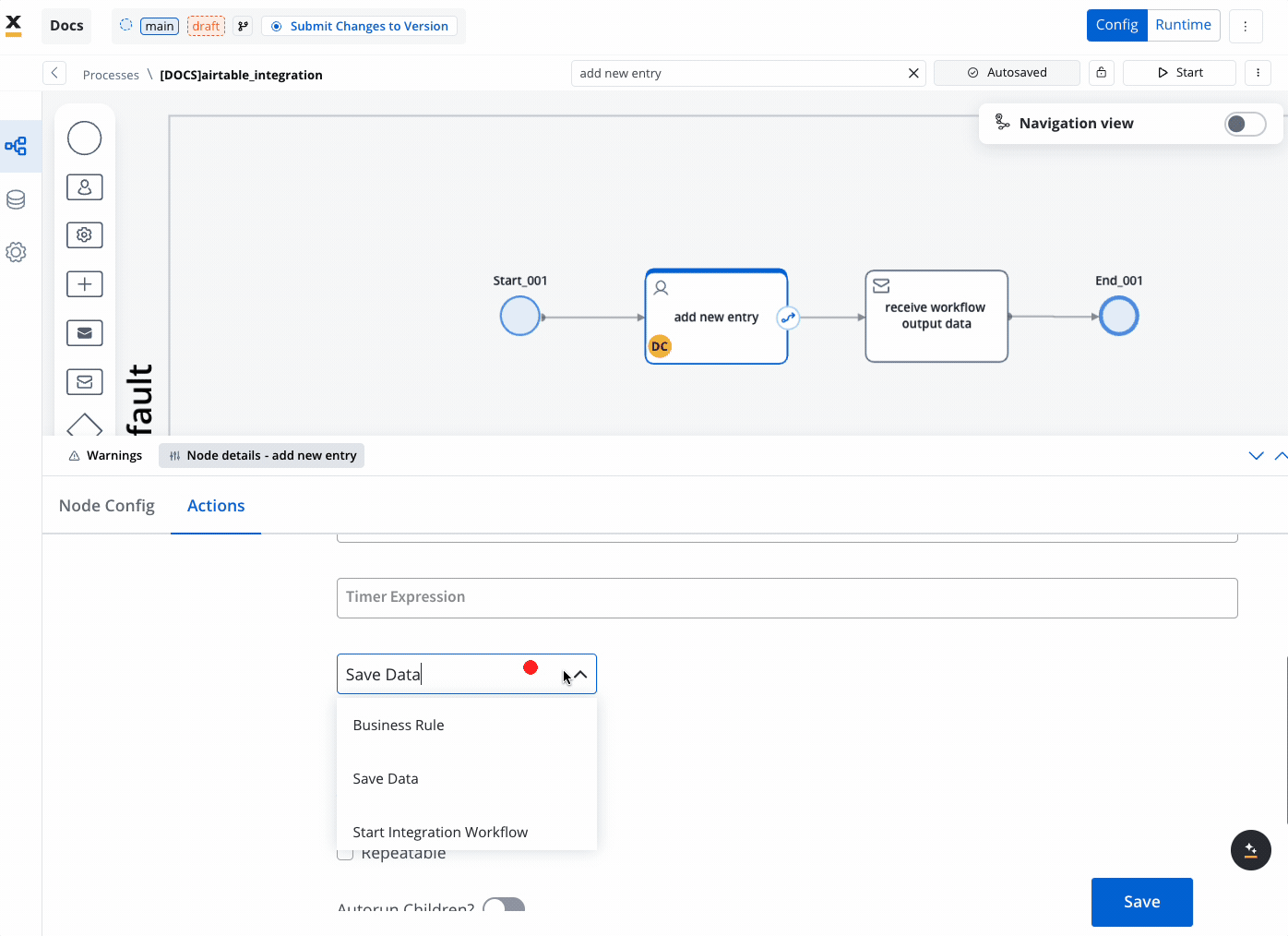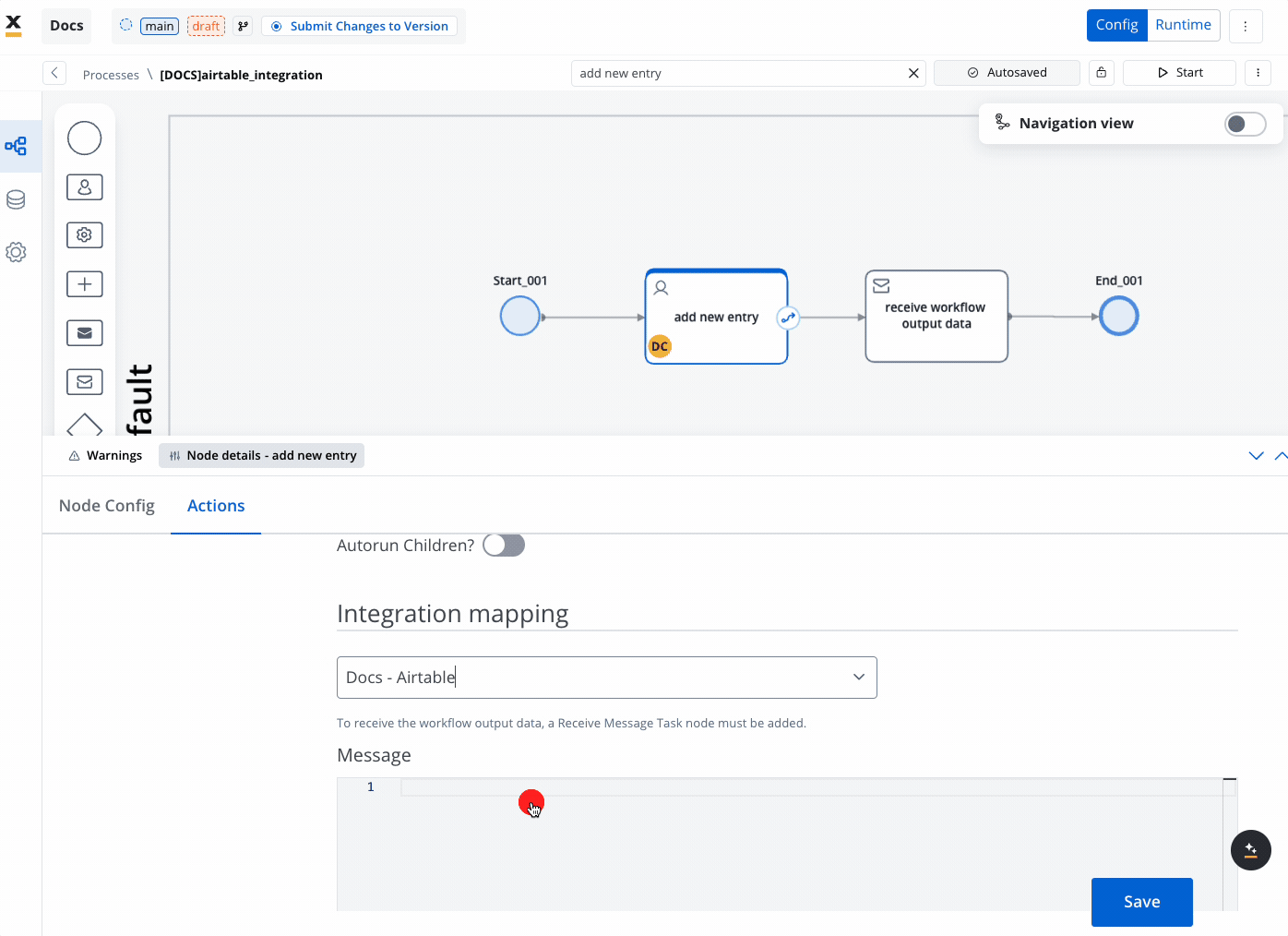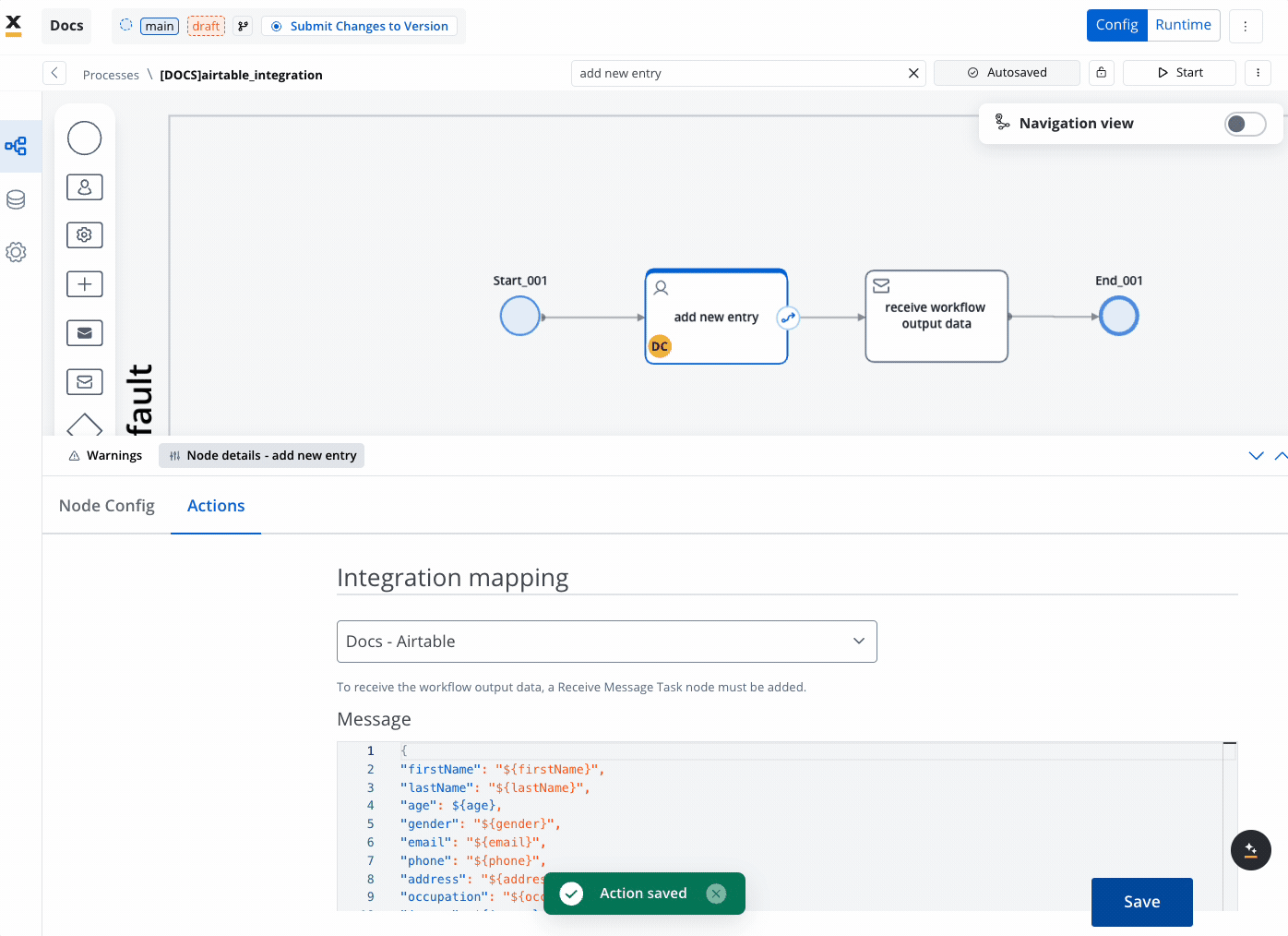
Configure Actions for the Task:
- In the node config, add a Start Integration Workflow action.
- Select the target workflow you want to integrate. This links the task with the predefined workflow in the Integration Designer.
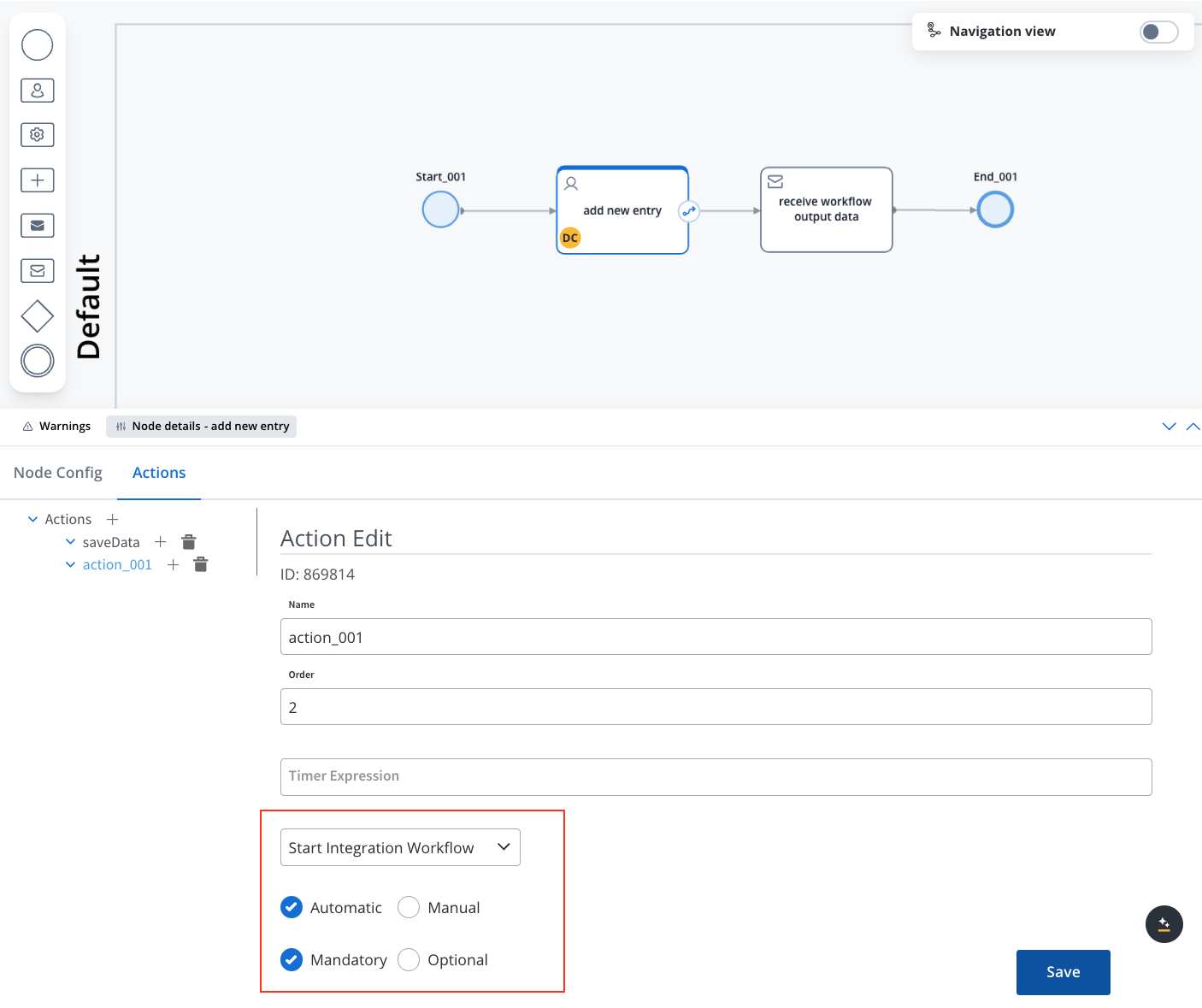
- Map the Payload:
- If input data is defined in the Start Node of the workflow, it will be automatically mapped in the Start Integration Workflow action. Ensure that the workflow’s Start Node contains the fields you need.
- Additional payload keys and values can also be set up as needed to facilitate data flow from the process to the workflow.
3
Receive Data from the Workflow
- Add a Receive Message Task:
- To handle data returned by the workflow, add a Receive Message Task in the BPMN diagram.
- This task captures the workflow’s output data, such as processing status or results sent via Kafka.
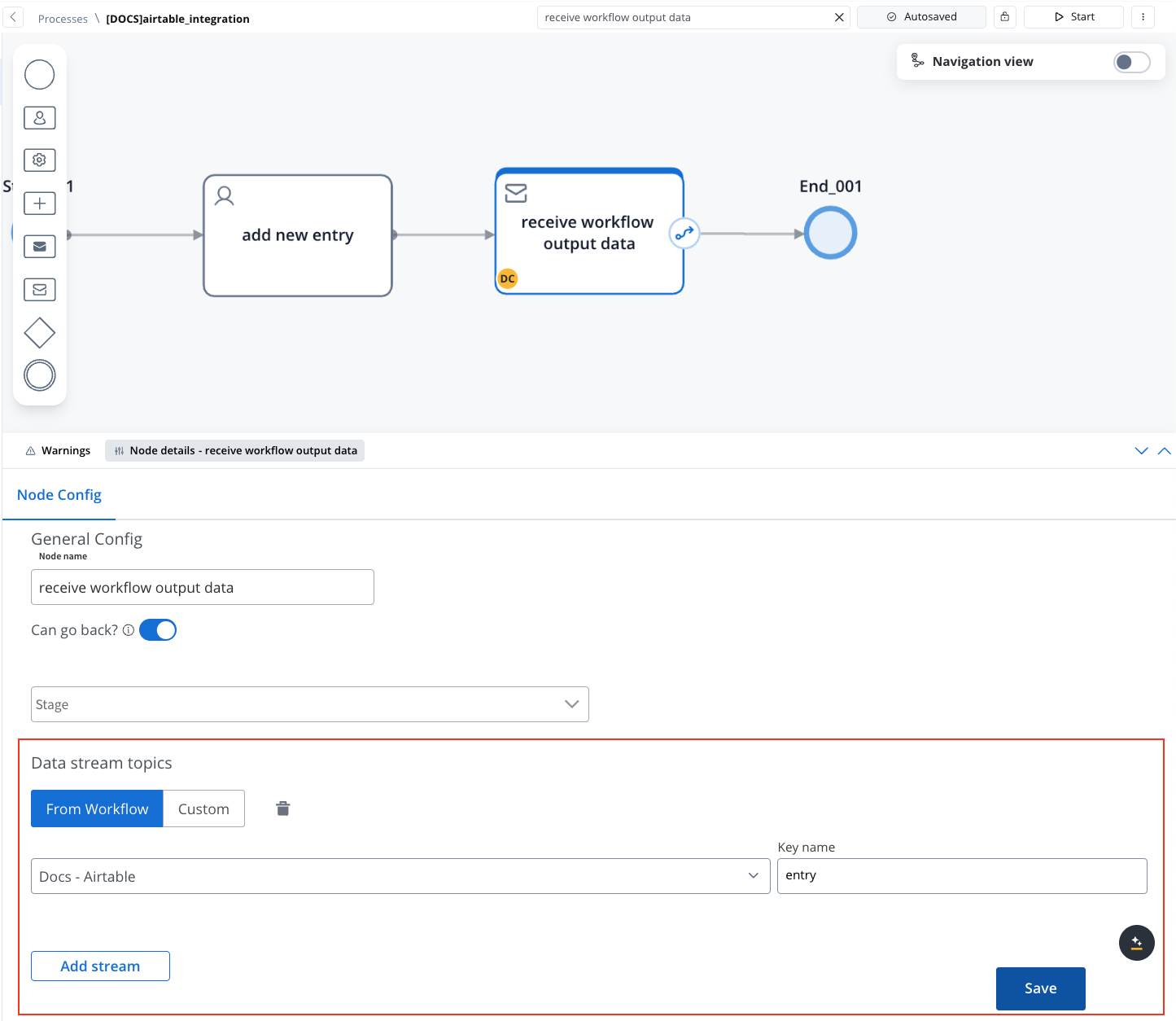
- Set Up a Data Stream Topic:
- In the Receive Message Task, select your workflow from the Data Stream Topics dropdown.
- Ensure that the workflow output data, including status or returned values, is accurately captured under a predefined key.
Integration with external systems
This example demonstrates how to integrate FlowX with an external system, in this example, using Airtable, to manage and update user credit status data. It walks through the setup of an integration system, defining API endpoints, creating workflows, and linking them to BPMN processes in FlowX Designer.Integration in FlowX
1
Define a System
Navigate to the Integration Designer and create a new system: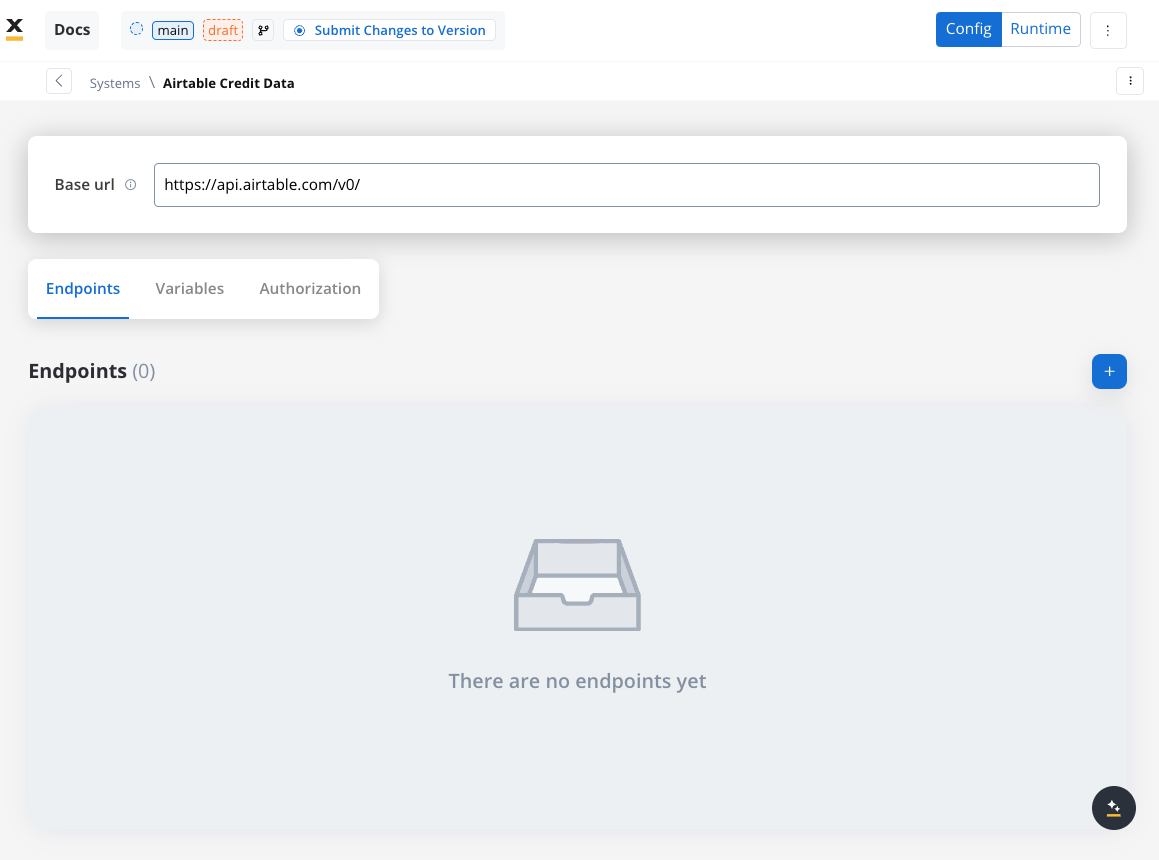
- Name: Airtable Credit Data
- Base URL:
https://api.airtable.com/v0/
2
Define Endpoints
In the Endpoints section, add the necessary API endpoints for system integration: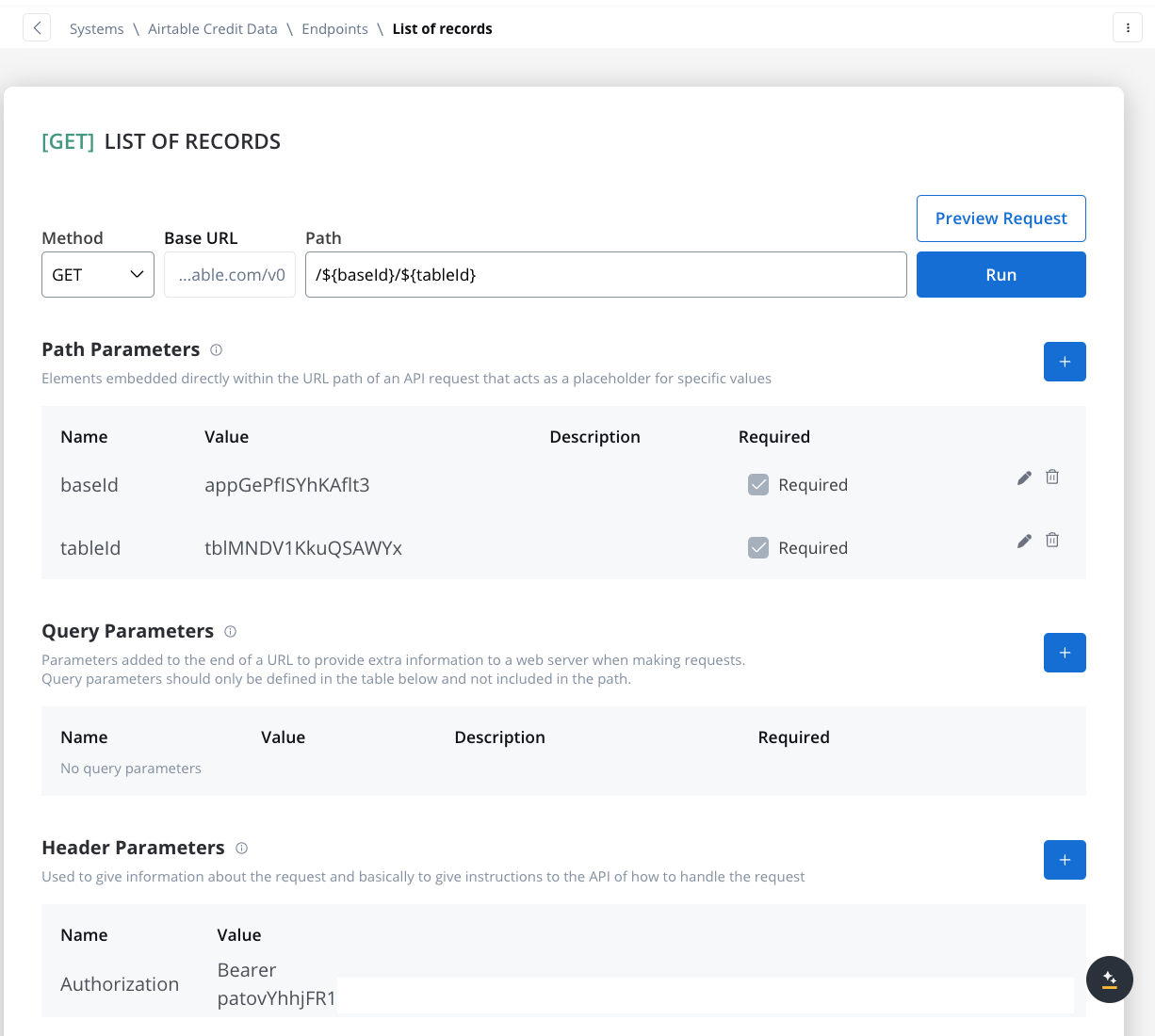
- Get Records Endpoint:
- Method: GET
- Path:
/${baseId}/${tableId} - Path Parameters: Add the values for the baseId and for the tableId so they will be available in the path.
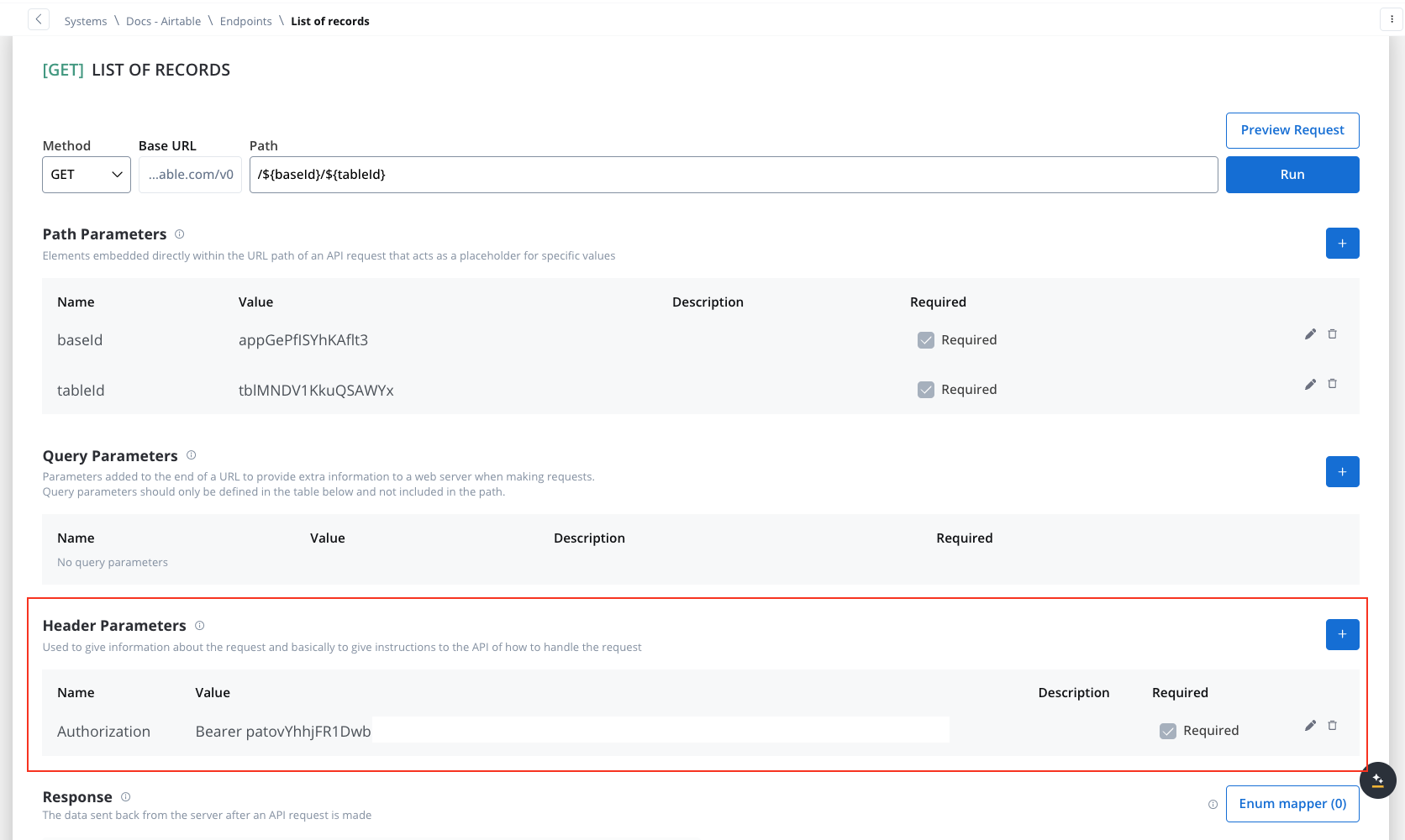
- Header Parameters: Authorization Bearer token
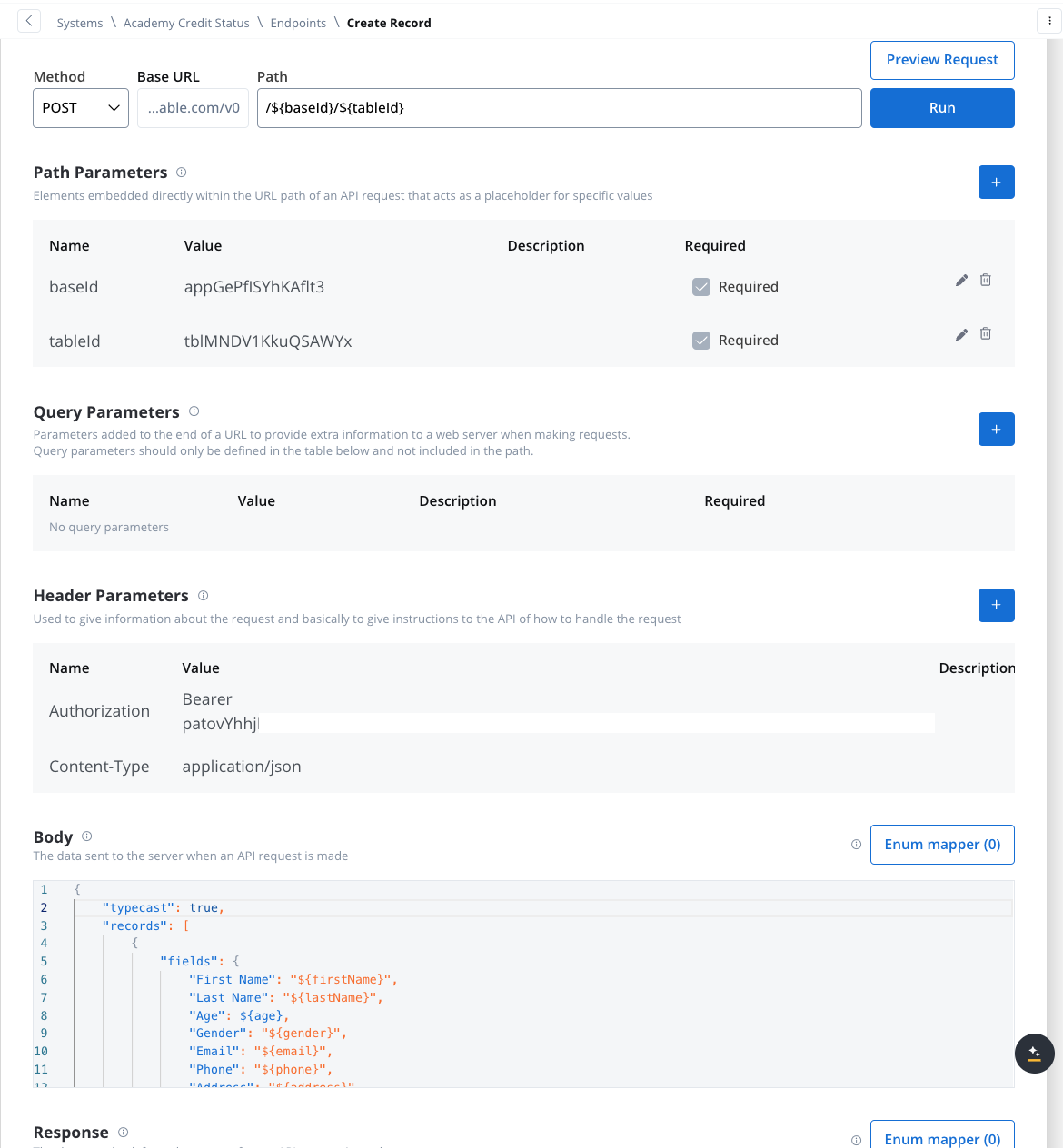
- Create Records Endpoint:
- Method: POST
- Path:
/${baseId}/${tableId} - Path Parameters: Add the values for the baseId and for the tableId so they will be available in the path.
- Header Parameters:
Content-Type: application/json- Authorization Bearer token
- Body: JSON format containing the fields for the new record. Example:
3
Design the Workflow
-
Open the Workflow Designer and create a new workflow.
- Provide a name and description.
-
Configure Workflow Nodes:
- Start Node: Initialize the workflow.
On the start node add the data that you want to extract from the process. This way when you will add the Start Workflow Integration node action it will be populated with this data.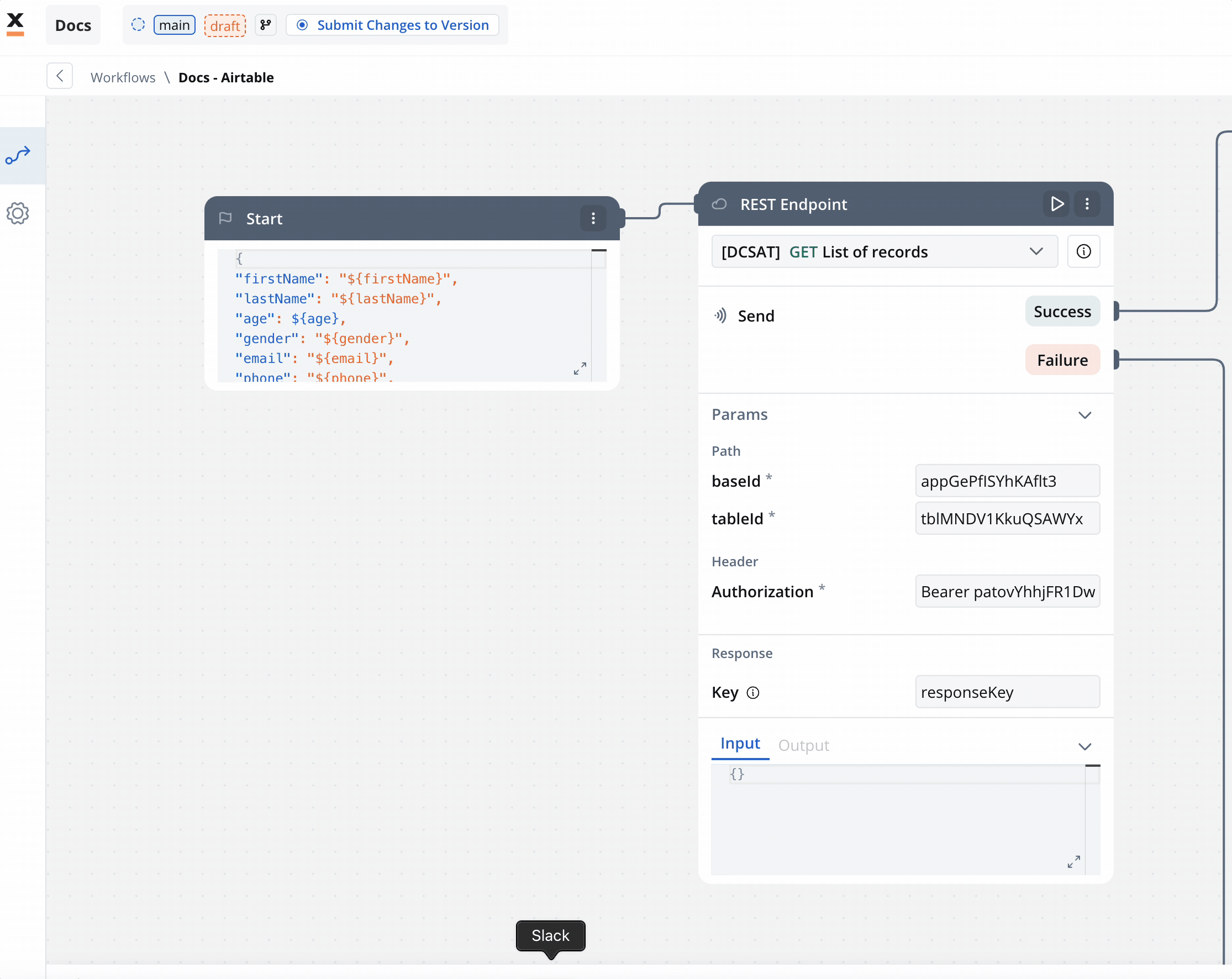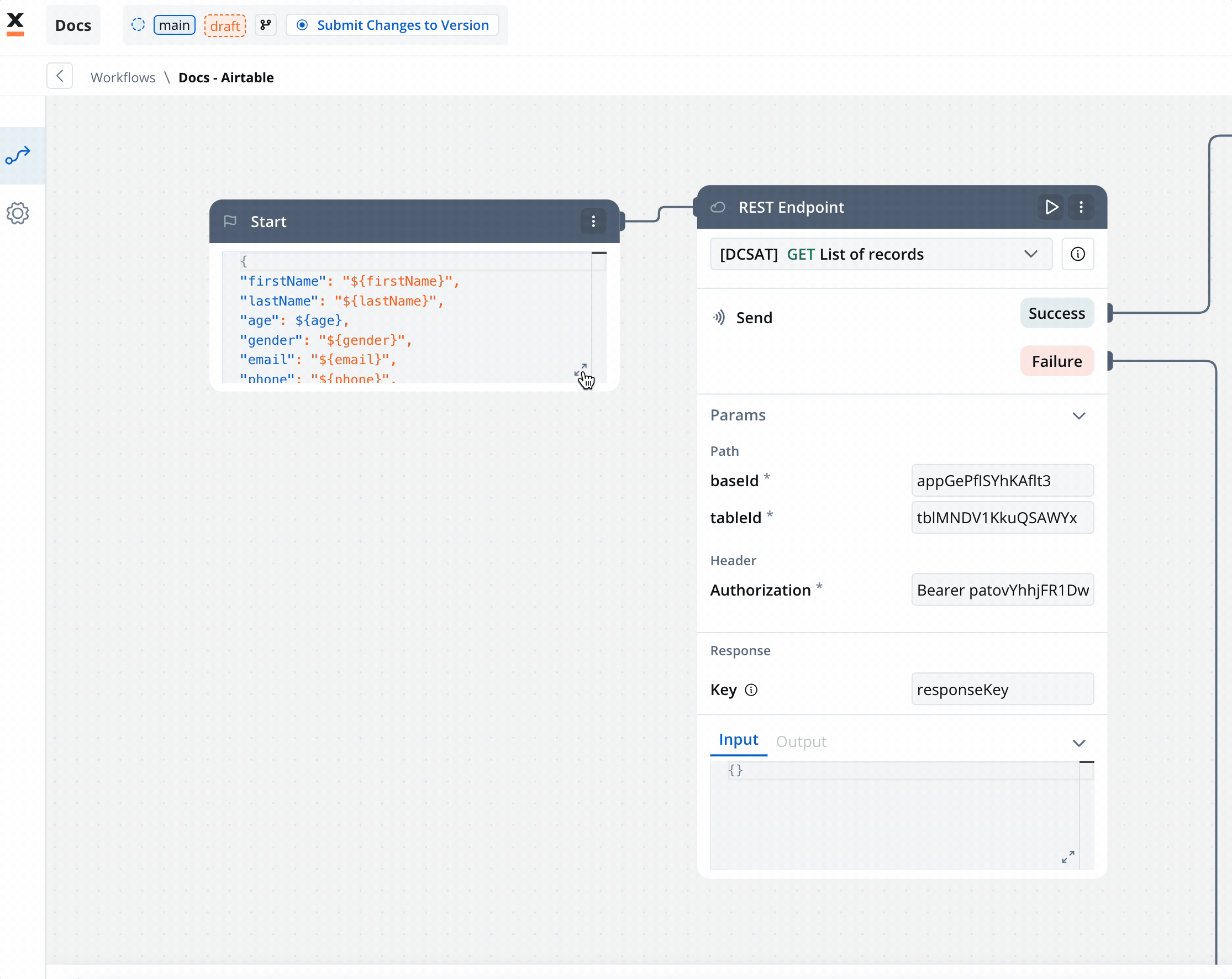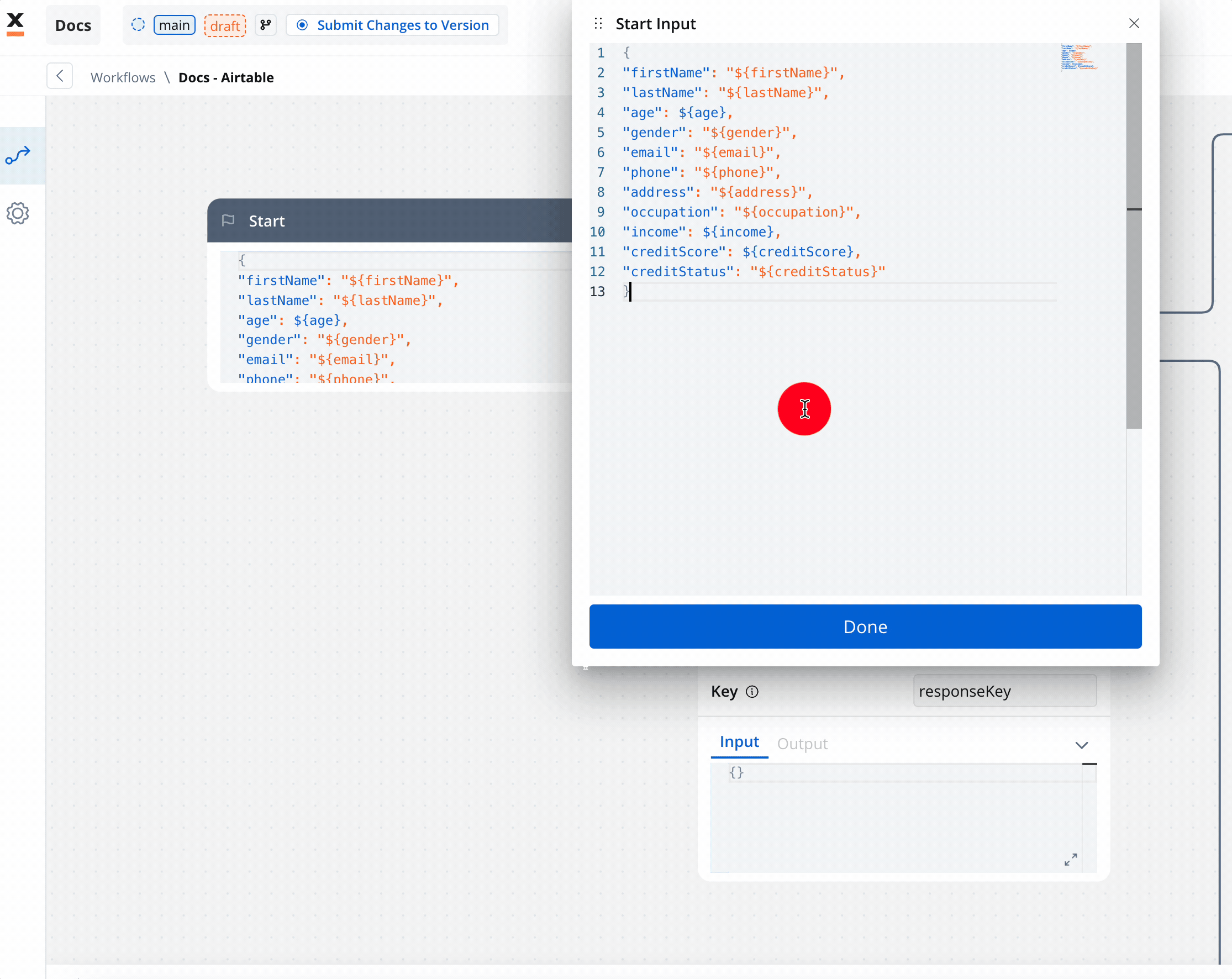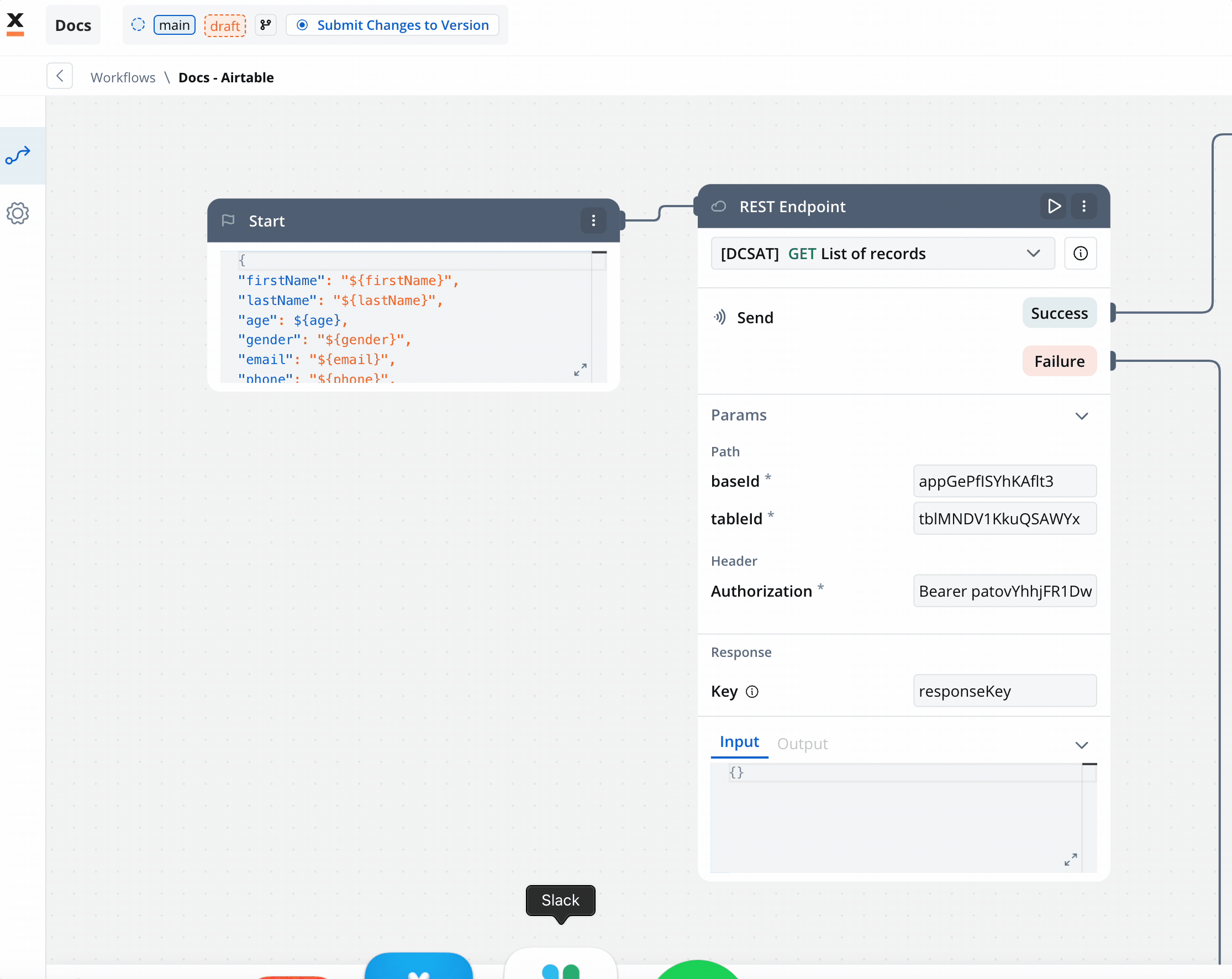 Make sure this keys are also mapped in the data model of your process with their corresponding attributes.
Make sure this keys are also mapped in the data model of your process with their corresponding attributes.
- REST Node: Set up API calls:
- GET Endpoint for fetching records from Airtable.
- POST Endpoint for creating new records.
- Condition Node: Add logic to handle credit scores (e.g., triggering a warning if the credit score is below 300).
- Script Node: Include custom scripts if needed for processing data (not used in this example).
- End Node: Define the end of the workflow with success or failure outcomes.
4
Link the Workflow to a Process
- Integrate the workflow into a BPMN process:
- Open the process diagram and include a User Task and a Receive Message Task.
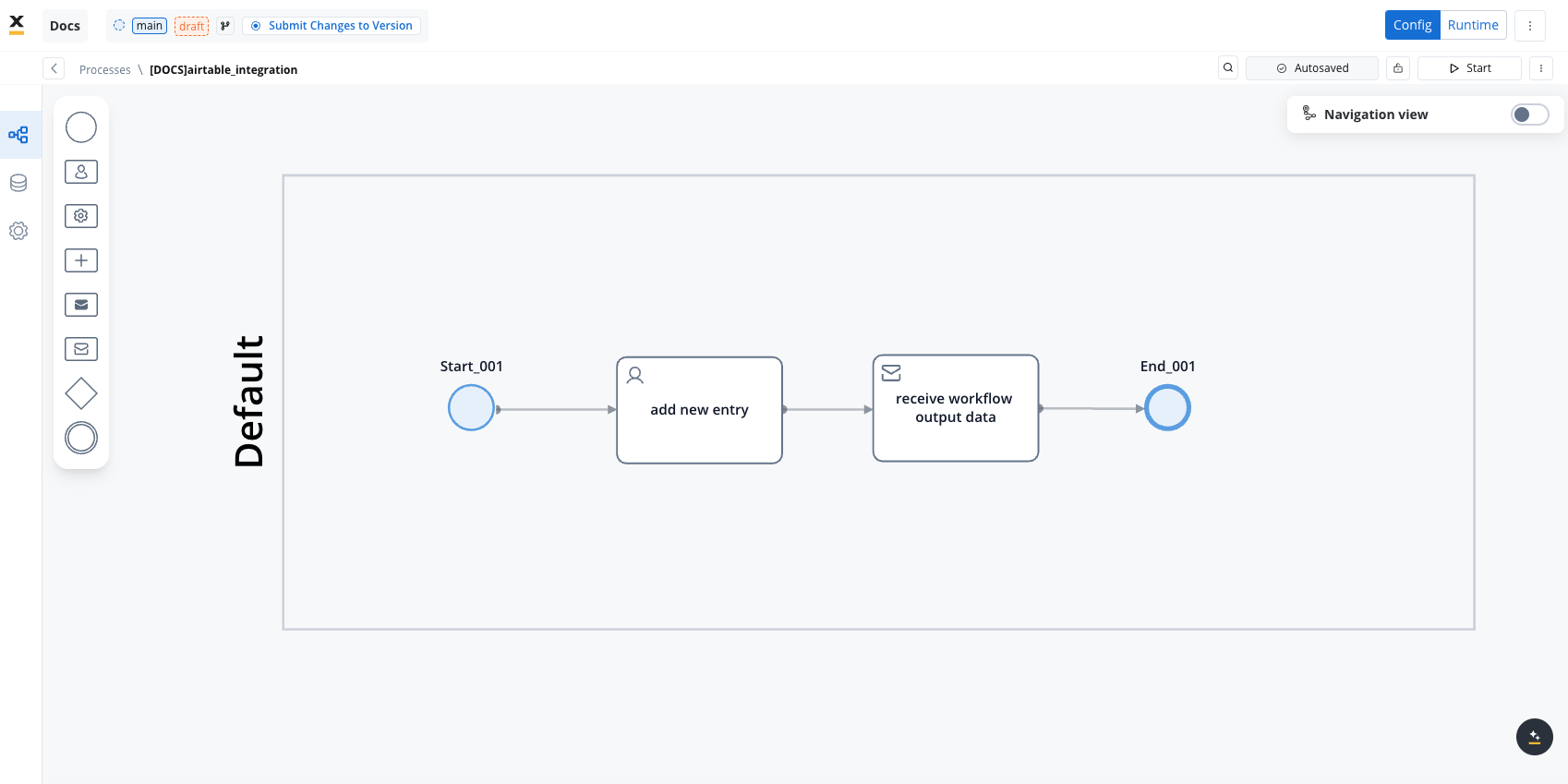
In this example, we’ll use a User Task because we need to capture user data and send it to our workflow.
- Map Data in the UI Designer:
- Create the data model
- Link data attributes from the data model to form fields, ensuring the user input aligns with the expected parameters.
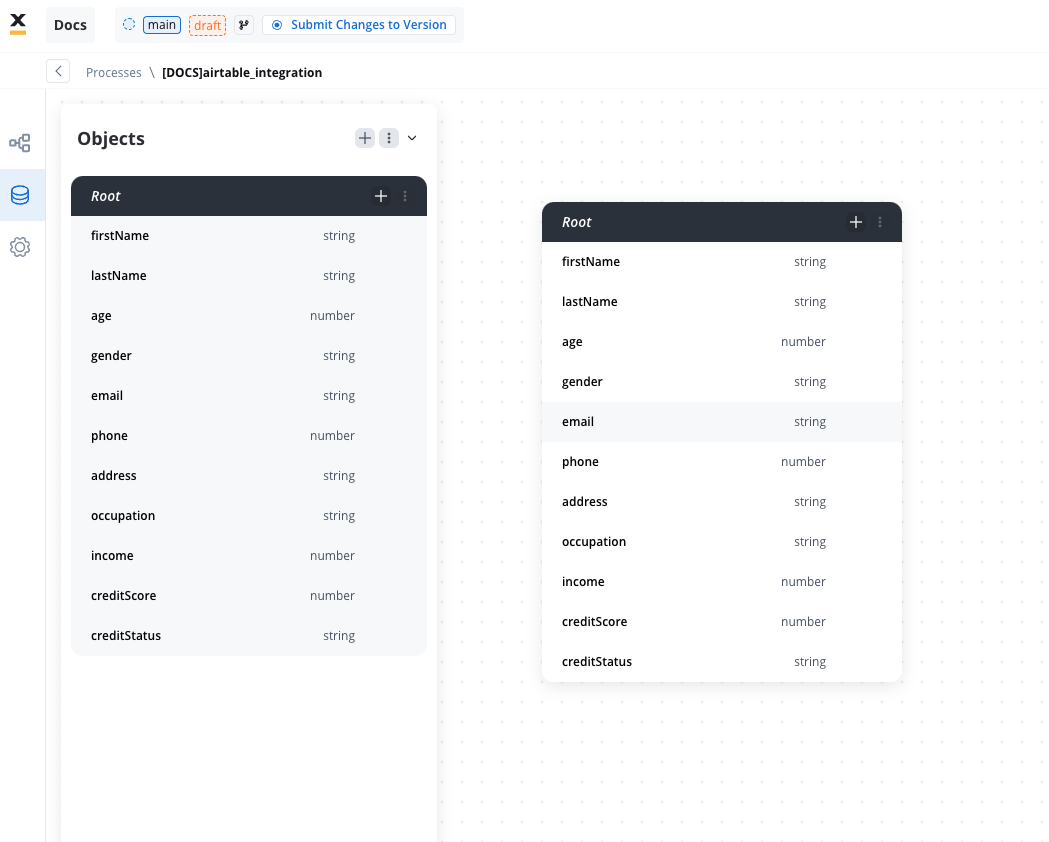
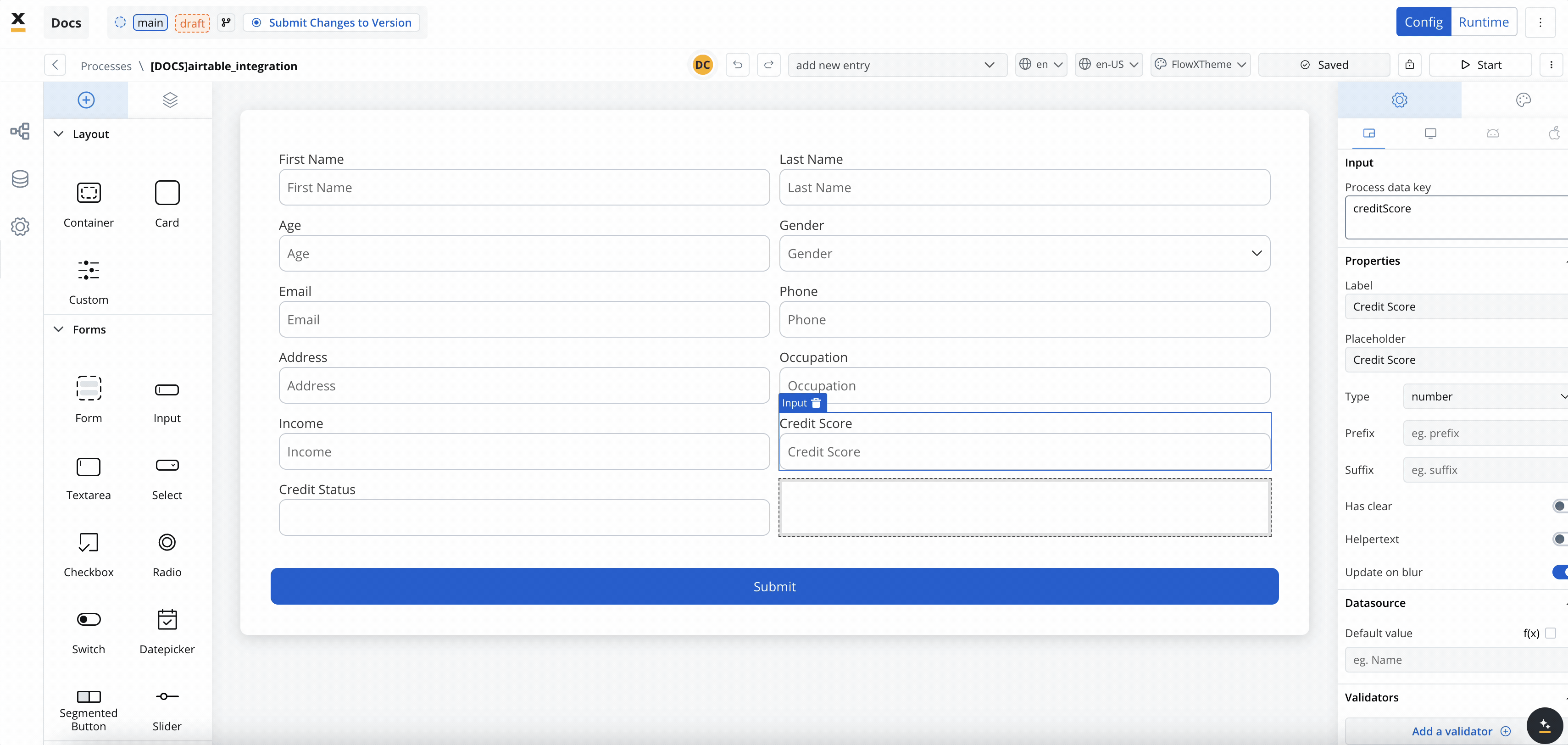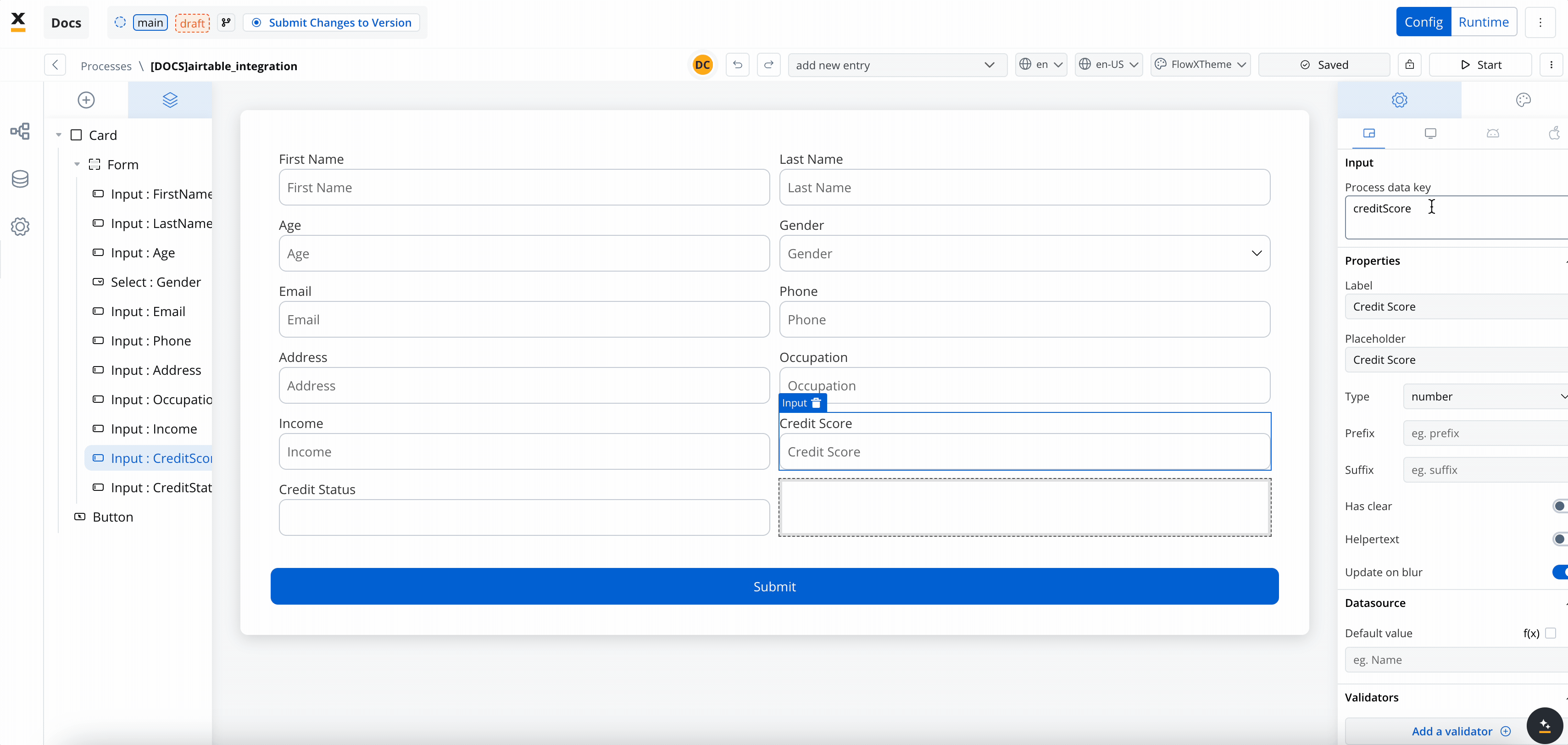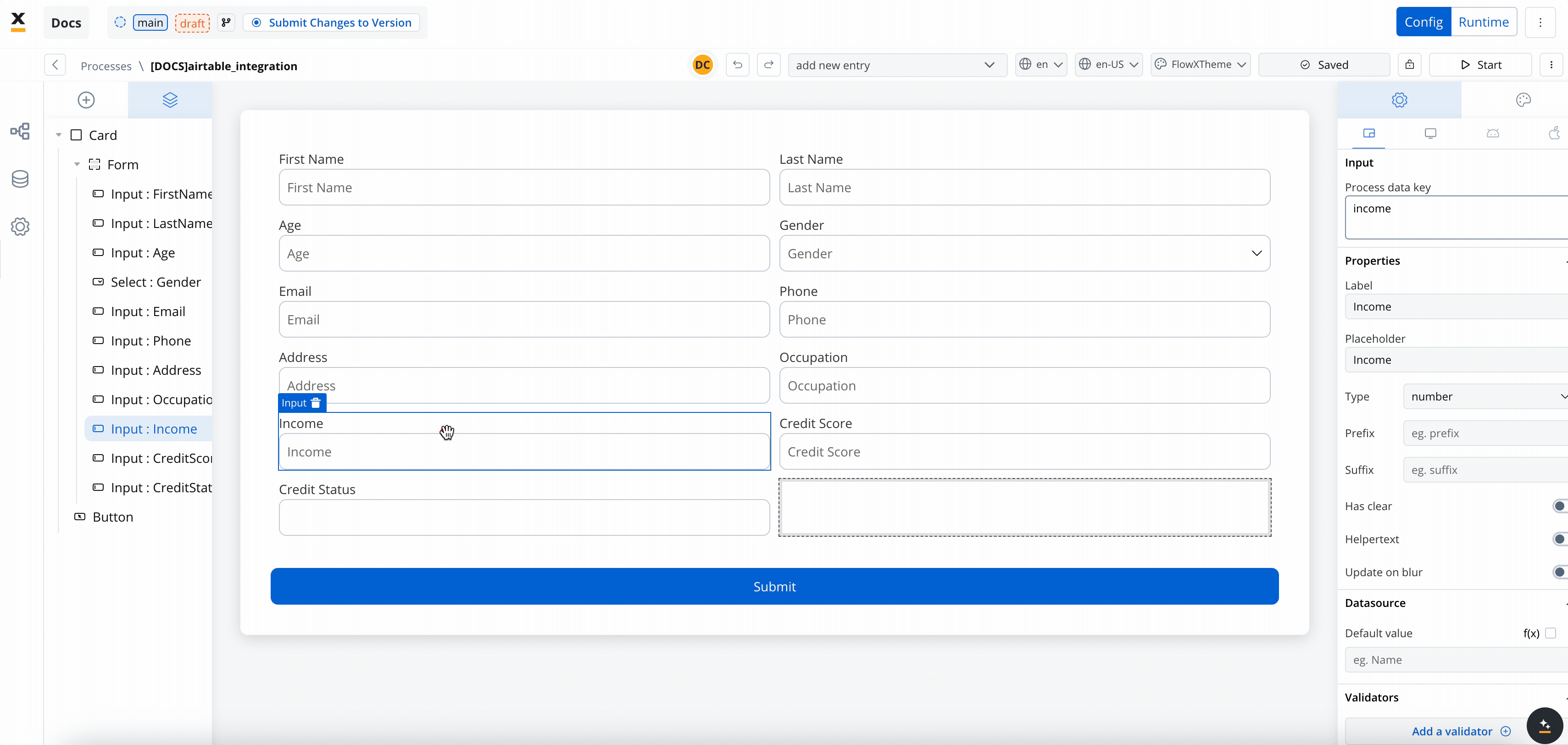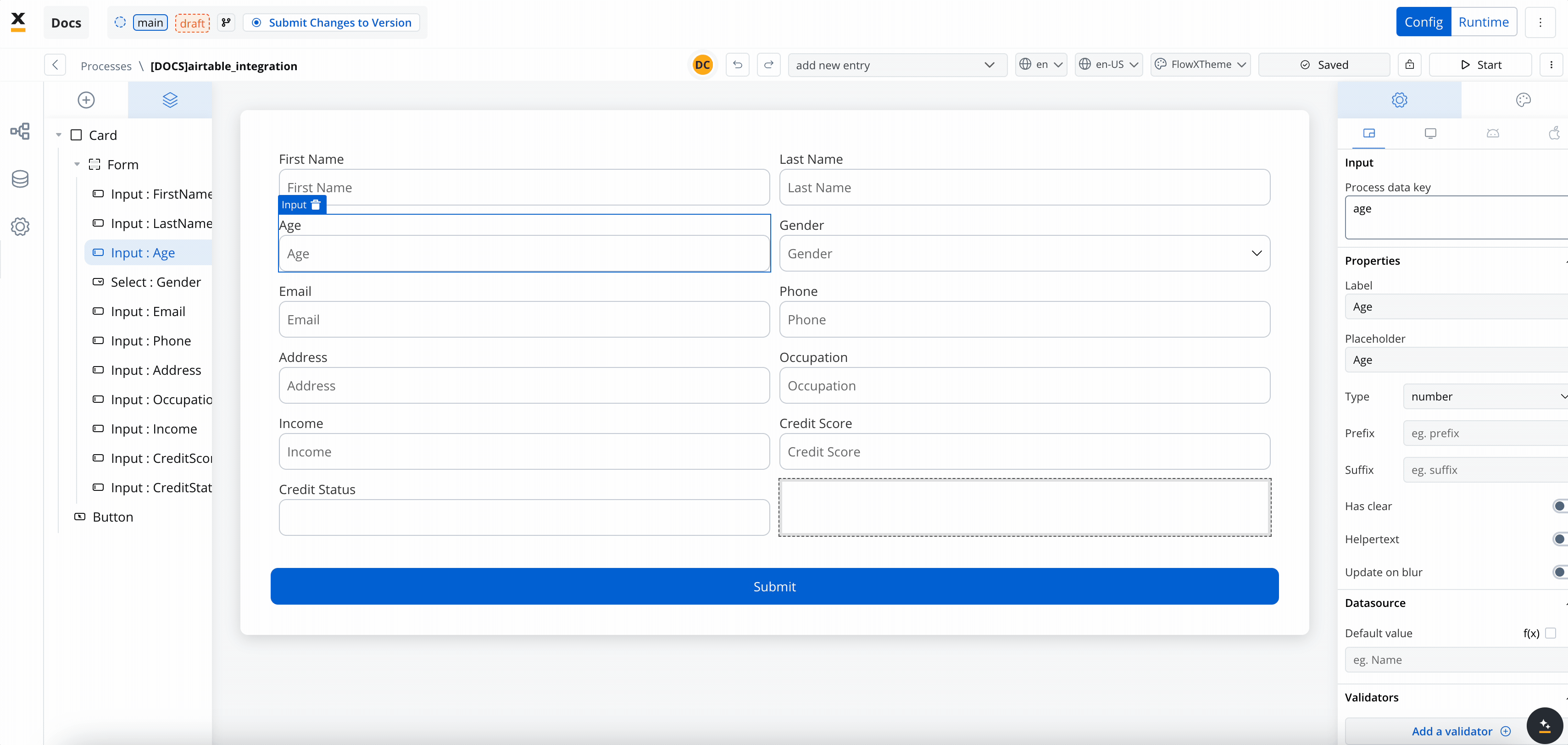
- Add a Start Integration Workflow node action:
- Make sure all the input will be captured.
5
Monitor Workflow and Capture Output
Receive Workflow Output: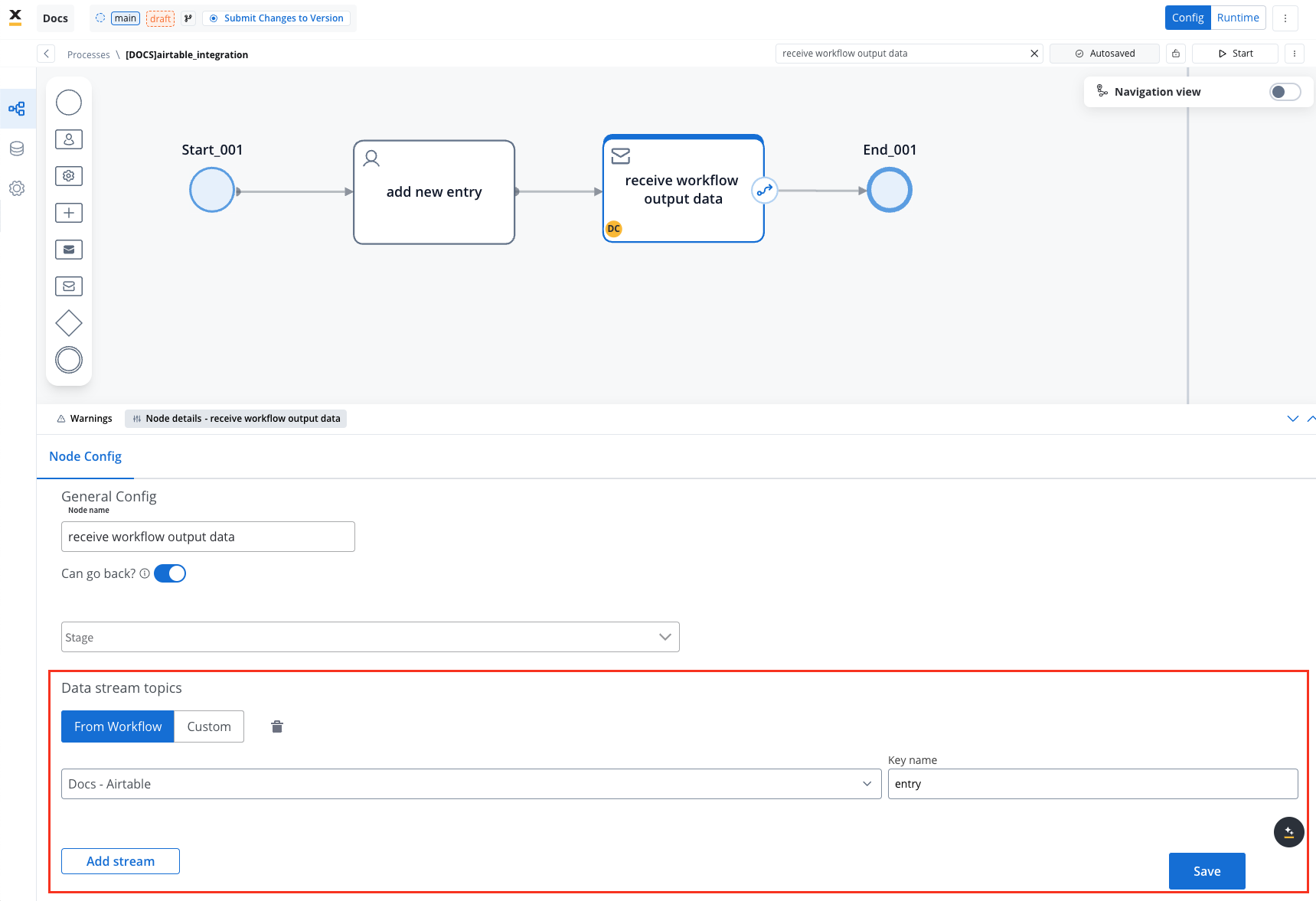
- Use the Receive Message Task to capture workflow outputs like status or returned data.
- Set up a Data stream topic to ensure workflow output is mapped to a predefined key.
6
Start the integration
- Start your process to initiate the workflow integration. It should add a new user with the details captured in the user task.
- Check if it worked by going to your base in Airtable. You can see, our user has been added.
This example demonstrates how to integrate Airtable with FlowX to automate data management. You configured a system, set up endpoints, designed a workflow, and linked it to a BPMN process.
FAQs
Can I use protocols other than REST?
Can I use protocols other than REST?
A: Currently, the Integration Designer only supports REST APIs, but future updates will include support for SOAP and JDBC.
How is security handled in integrations??
How is security handled in integrations??
A: The Integration Service handles all security aspects, including certificates and secret keys. Authorization methods like Service Token, Bearer Token, and OAuth 2.0 are supported.
How are errors handled?
How are errors handled?
A: Errors are logged within the workflow and can be reviewed in the monitoring dedicated console for troubleshooting and diagnostics
Can I import endpoint specifications in the Integration Designer?
Can I import endpoint specifications in the Integration Designer?
A: Currently, the Integration Designer only supports adding endpoint specifications manually. Import functionality (e.g., importing configurations from sources like Swagger) is planned for future releases.For now, you can manually define your endpoints by entering the necessary details directly in the system.