Overview
Partitioning and archiving are data management strategies used to handle large volumes of data efficiently. They improve database performance, manageability, and storage optimization. By dividing data into partitions and archiving older or less frequently accessed data, organizations can ensure better data management, quicker query responses, and optimized storage use.Partitioning
Partitioning is the process of dividing a large database table into smaller, more manageable pieces, called partitions. Each partition can be managed and queried independently. The primary goal is to improve performance, enhance manageability, and simplify maintenance tasks such as backups and archiving. Partitions can be created per day, week or month. This means that a partition ID is computed at insert time for each row of process_instance and related tables. Afterwards, a retention period can be setup (eg: 3 partitions). A flowx engine-driven cron job (with configurable start interval) will check if there is any partition which needs to be archived and will perform the necessary actions.Benefits of partitioning
- Improved Query Performance: By scanning only relevant partitions instead of the entire table.
- Simplified Maintenance: Easier to perform maintenance tasks like backups and index maintenance.
- Data Management: Better data organization and management by dividing data based on specific criteria such as date, range, or list.
Database Compatibility: Oracle Database and PostgreSQL.
Archiving
Archiving involves moving old data from the primary tables to separate archive tables. This helps in reducing the load on the primary tables, thus improving performance and manageability.Benefits of archiving
- Storage Optimization: Archived data can be compressed, saving storage space.
- Performance Improvement: Reduces the volume of data in primary tables, leading to faster query responses.
- Historical Data Management: Maintains historical data in a separate, manageable form.
Partitioning and archiving in Oracle Database
Oracle Database partitioning
Concept
Oracle Database partitioned tables are utilized, allowing for efficient data management and query performance.
Implementation
Each partition can be managed and queried independently.Example: A
process_instance table can be partitioned by day, week, or month.Oracle Database archiving
Process
Detaching the partition from the main table.Converting the detached partition into a new table named
archived_${table_name}_${interval_name}_${reference} for example: archived_process_instance_monthly_2024_03 .The DATE is in the format
yyyy-MM-dd if the interval is DAY, or in the format yyyy-MM if the interval is MONTH, or in the format yyyy-weekOfYear if the interval is WEEK.Steps
Identify partitions eligible for archiving based on retention settings.Detach the partition from the main table.Create a new table with the data from the detached partition.Optionally compress the new table to save space.
Benefits
Manages historical data by moving it to separate tables, reducing the load on the main table.Compression options (OFF, BASIC, ADVANCED) further optimize storage.
Oracle offers several compression options—OFF, BASIC, and ADVANCED—that optimize storage. Each option provides varying levels of data compression, impacting storage savings and performance differently.
- OFF: No compression is applied.
- BASIC: Suitable for read-only or read-mostly environments, it compresses data without requiring additional licenses.
- ADVANCED: Offers the highest level of compression, supporting a wide range of data types and operations. It requires an Advanced Compression license and provides significant storage savings and performance improvements by keeping data compressed in memory.
PostgreSQL archiving
Process
Creating a new table for the partition being archived.Moving data from the main table to the new archive table (in batches).
Since here the DB has more work to do than just changing some labels (actual data insert and delete vs relabel a partition into a table, for Oracle Database) the data move is batched and the batch size is configurable.
Steps
Identify partitions eligible for archiving based on retention settings.Create a new table following this naming convention:
archived__${table_name}__${interval_name}_${reference}, example: archived__process_instance__weekly_2024_09 .Configure the batch size for data movement to control the load on the database.Differences from Oracle databases:Archiving involves actual data movement (insert and delete operations), unlike Oracle databases where it is mainly a relabeling of partitions.The batch size for data movement is configurable, allowing fine-tuning of the archiving process.
Daily operations
Once set up, the partitioning and archiving process involves the following operations:Partition ID Calculation
The
partition_id is automatically calculated based on the configured interval (DAY, WEEK, MONTH).
Example for daily partitioning: 2024-03-01 13:00:00 results in partition_id = 124061. See the Partition ID calculation section.Retention Management
Data older than the configured retention interval becomes eligible for archiving and compressing.
Archiving process
A cron job checks for eligible partitions.Eligible partitions are archived and optionally compressed.The process includes deactivating foreign keys, creating new archive tables, moving data references, reactivating foreign keys, and dropping the original partition.
Space management
Archived tables remain in the database but occupy less space if compression is enabled.Recommendation: to free up space, consider moving archived tables to a different database or tablespace. Additionally, you have the option to move only process instances or copy definitions depending on your needs.
Future schema updates or migrations will not affect archived tables. They retain the schema from the moment of archiving.
Configuring partitioning and archiving
The Partitioning and Archiving feature is optional and can be configured as needed.
| Environment Variable | Description | Default Value | Possible Values |
|---|---|---|---|
FLOWX_DATA_PARTITIONING_ENABLED | Activates data partitioning. | false | true, false |
FLOWX_DATA_PARTITIONING_INTERVAL | Interval for partitioning (the time interval contained in a partition). | MONTH | DAY, WEEK, MONTH |
FLOWX_DATA_PARTITIONING_RETENTION_INTERVALS | Number of intervals retained in the FlowX database (for partitioned tables). | 3 | Integer values (e.g., 1, 2, 3) |
FLOWX_DATA_PARTITIONING_DETACHED_PARTITION_COMPRESSION | Enables compression for archived (detached) partitions (Oracle only). | OFF | OFF, BASIC, ADVANCED |
FLOWX_DATA_PARTITIONING_MOVED_DATA_BATCH_SIZE | Batch size for moving data (PostgreSQL only). | 5000 | Integer values (e.g., 1000, 5000) |
SCHEDULER_DATAPARTITIONING_ENABLED | Activates the cron job for archiving partitions. | true | true, false |
SCHEDULER_DATAPARTITIONING_CRONEXPRESSION | Cron expression for the data partitioning scheduler. | 0 0 1 * * ? -> every day at 1:00AM | Cron expression (e.g., 0 0 1 * * ?) |
Compression for archived (detached) partitions is available only for Oracle DBs.
The batch size setting for archiving data is available only for PostgreSQL DBs.
Logging information
Partitioning and archiving actions are logged in two tables:DATA_PARTITIONING_LOG: For tracking archived partitions.
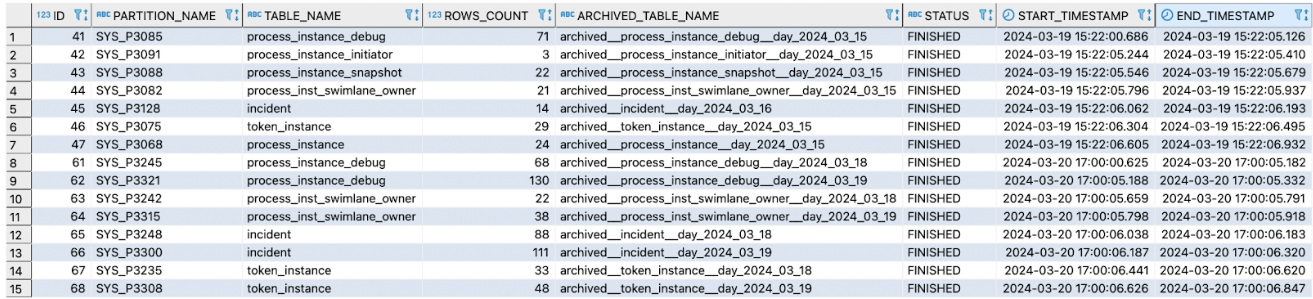
DATA_PARTITIONING_LOG_ENTRY: For logging SQL commands executed for archiving.

Enabling partitioning and Elasticsearch indexing strategy
When partitioning is enabled, the Elasticsearch indexing strategy must also be enabled and configured on FlowX Engine setup.Why?
- When archiving process instances, data from Elasticsearch must be deleted, not just the cache but also indexed keys (e.g., those indexed for data search on process instances).
Elasticsearch indexing configuration
Check the Elasticsearch indexing setup here:Elasticsearch indexing setup
Index partitioning
-
transforms.routeTS.topic.format: "process_instance-${timestamp}": This value must start with the index name defined in the process-engine config: flowx.indexing.processInstance.index-name. In this example, the index name is prefixed with “process_instance-” and appended with a timestamp for dynamic index creation. For backward compatibility, the prefix must be “process_instance-”. However, backward compatibility is not strictly required here. yaml -
transforms.routeTS.timestamp.format: "yyyyMMdd": This format ensures that timestamps are consistently represented and easily parsed when creating or searching for indices based on the process instance start date. You can adjust this value as needed (e.g., for monthly indexes, use “yyyyMM”). However, note that changing this format will cause existing indexed objects to remain unchanged, and update messages will be treated as new objects, indexed again in new indices. It is crucial to determine your index size and maintain consistency.
Kafka Elasticsearch Connector
Technical details
Partition ID calculation
- The
partition_idformat follows this structure:<LEVEL || YEAR || BIN_ID_OF_YEAR>. This ID is calculated based on the start date of theprocess_instance, the partition interval, and the partition level.LEVEL: This represents the “Partitioning level,” which increments with each change in the partitioning interval (for example, if it changes fromDAYtoMONTHor vice versa).YEAR: The year extracted from theprocess_instancedate.BIN_ID_OF_YEAR: This is the ID of a bucket associated with theYEAR. It is created for all instances within the selected partitioning interval. The maximum number of buckets is determined by the partitioning frequency:- Daily: Up to 366 buckets per year
- Weekly: Up to 53 buckets per year
- Monthly: Up to 12 buckets per year
Calculation example
For a timestamp of2024-03-01 13:00:00 with a daily partitioning interval, the partition_idwould be 124061:
1: Partitioning Level (LEVEL)24: Year - 2024 (YEAR)061: Bucket per configuration (61st day of the year)
Archived tables
- Naming format:
archived__${table_name}__${interval_name}_${reference}. Examples:- archived__process_instance__monthly_2024_03
- archived__process_instance__weekly_2024_09
- archived__process_instance__daily_2024_03_06