> ## Documentation Index
> Fetch the complete documentation index at: https://docs.flowx.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Managing stores
> Learn how to upload documents, manage stores, and work with chunks in FlowX Knowledge Bases.
## Overview
Stores are the building blocks of a Knowledge Base. Each store represents a collection of related information that has been ingested, processed, and indexed for semantic search.
## Store types
There are two types of stores:
Files uploaded directly through the Knowledge Base admin interface
JSON content ingestion through workflows (planned for future release)
## Viewing stores
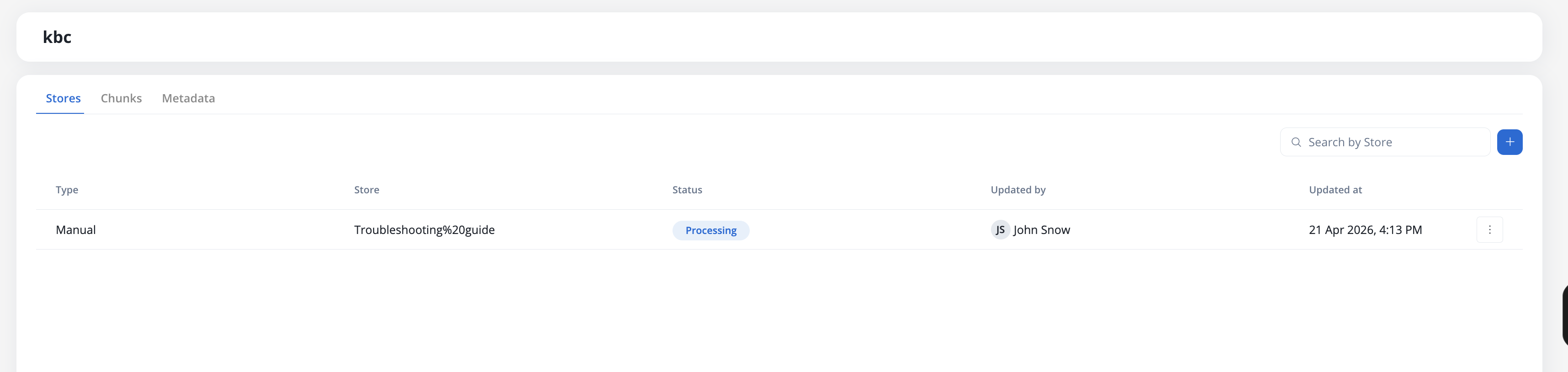
Navigate to your Knowledge Base to see all stores. The **Stores** tab displays:
### Store information
Each row shows:
* **Manual**: Files uploaded in the Knowledge Base page
* **Workflow**: Content ingestion through workflow variables (planned for future release)
The unique name of the store within the Knowledge Base
Current processing state:
* **New**: Store created, awaiting content upload
* **Processing**: Content is being uploaded, chunked, and indexed
* **Ready**: Content is fully processed and available for queries
* **Failed**: An error occurred during processing, or content is partially degraded
Status badges update in real-time — you don't need to refresh the page to see status changes.
* **Username**: For files uploaded in the Knowledge Base page
* **Workflow name**: For content ingested through workflows (planned for future release)
Timestamp of the last upload or workflow operation execution
## Uploading documents
Open your Knowledge Base in FlowX Designer and select the **Stores** tab.
Click the **+** button in the top-right of the Stores tab. A file picker opens.
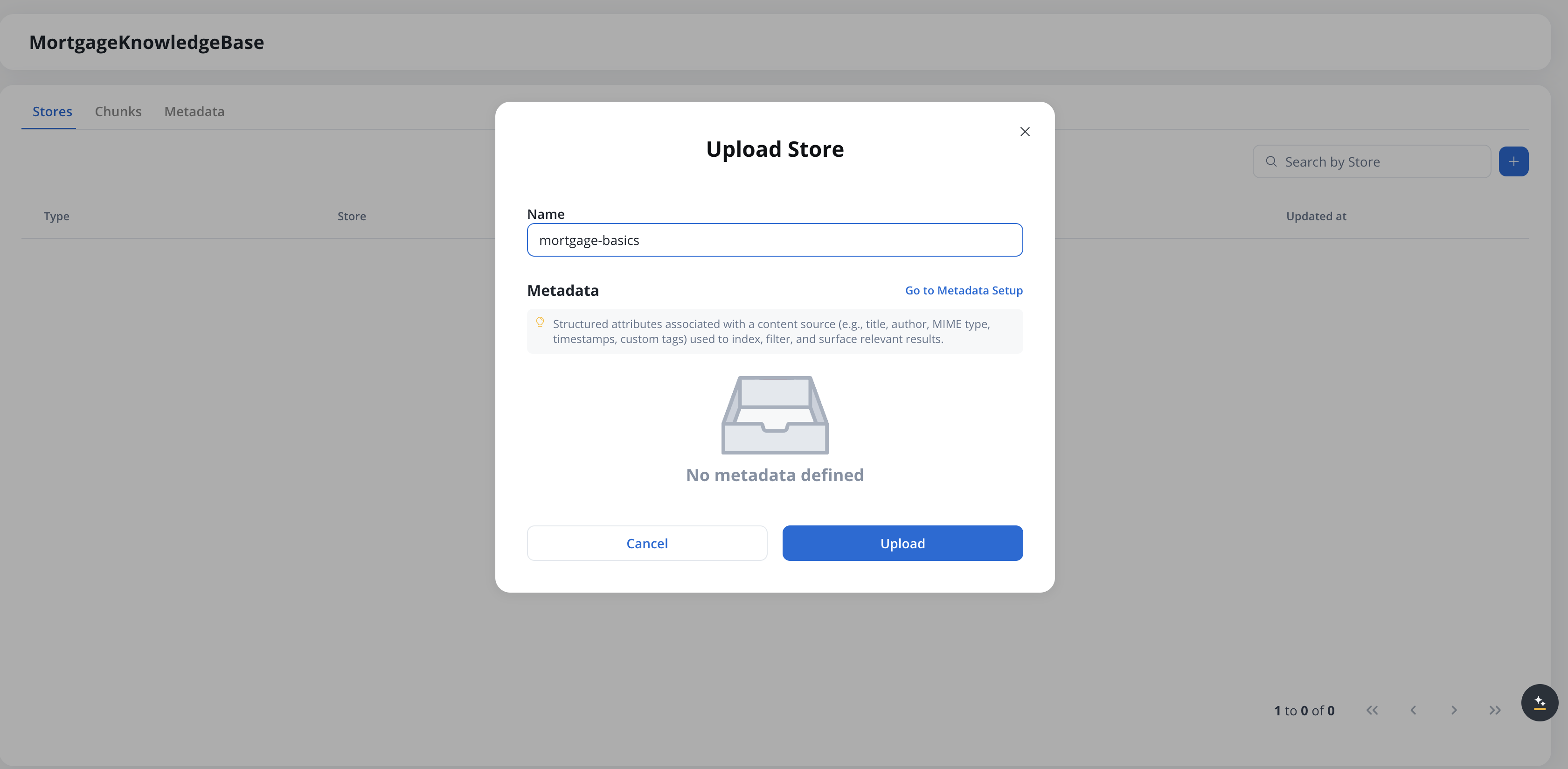
Choose a PDF file from your computer and click **Open**. The **Upload Store** modal appears.
The **Name** field is pre-filled with the file name (without extension). Edit it if needed — the name must be unique within the Knowledge Base.
The **Metadata** section shows the metadata schema defined for this Knowledge Base. If no metadata is defined, a "No metadata defined" placeholder appears — click **Go to Metadata Setup** to configure a schema on the **Metadata** tab before uploading. See [User-defined metadata](#user-defined-metadata) for details.
Click **Upload** to start the ingestion process. The store appears in the list with status **Processing**, and transitions to **Ready** once chunking and indexing complete.
### File requirements
**Supported formats (current release):**
* PDF files only
**File size:**
* Maximum file size: 20 MB (can be changed using environment variables)
**Future releases will support:**
* Images
* PowerPoint presentations
* Word documents
* Excel spreadsheets
### Store naming
When uploading a document, you must provide a unique store name:
**Store name rules:**
* Must be unique within the Knowledge Base
* Default name is the file name without extension
* Choose descriptive names for easy identification
* Consider using versioning in names (e.g., "Product Guide v2.1")
### Duplicate stores
If you select a file with the same name as an existing store, you'll see a warning:
```
A Store with this name already exists. We recommend updating the existing store instead.
```
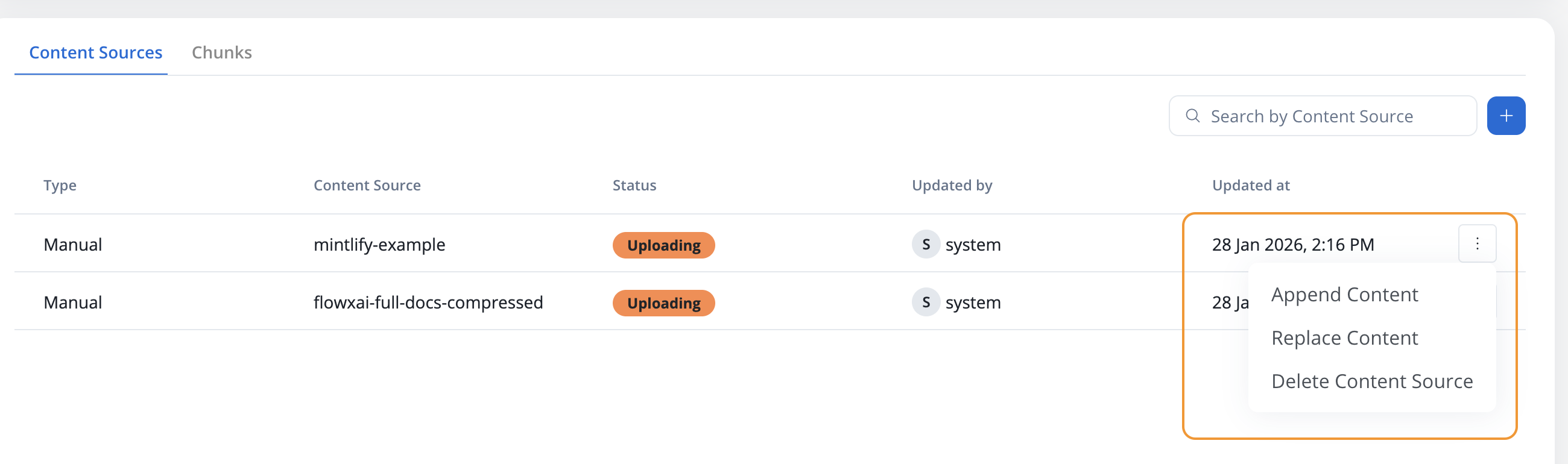
**Available options:**
* **Append Content**: Add the new document's content to the existing store
* **Replace Content**: Replace the existing content with the new document
* **Cancel**: Choose a different name or file
## Managing stores
Once content is uploaded and processed, you can perform the following operations:
### Append content
Add new content to an existing store without removing the existing chunks.
Click on the store you want to update
Select the **Append Content** operation
Select a new PDF file with additional content
The new content will be processed and added to the existing chunks
**Use case:** Adding a new chapter to existing documentation or supplementing information without losing the original content.
### Replace content
Replace all existing content in a store with new content.
Click on the store you want to replace
Select the **Replace Content** operation
Select a new PDF file that will replace the existing content
All existing chunks will be deleted and new chunks will be created from the new content
**Replace Content** will permanently delete all existing chunks from the store. This operation cannot be undone.
**Use case:** Updating documentation to a new version where the old content is no longer relevant.
### Delete store
Remove a store and all its associated chunks from the Knowledge Base.
Click on the store you want to delete
Select the **Delete Store** operation
Confirm that you want to permanently delete the store
Deleting a store will:
* Remove all chunks generated from that content
* Permanently delete the content from the Knowledge Base
* This operation cannot be undone
## Store states
Stores progress through different states during their lifecycle. Status badges update in real-time — you don't need to refresh the page to see transitions.
### New
The initial state after content is uploaded to the Knowledge Base.
**What's happening:**
* File has been transferred to the FlowX platform
* Content is being validated and queued for processing
**Duration:** Usually a few seconds, depending on file size
### Processing
Content is being chunked, embedded, and indexed in the vector database.
**What's happening:**
* Content is being extracted from the document
* Text is being split into semantically meaningful chunks
* Chunks are being embedded and indexed in the vector database
**Duration:** Can take from seconds to minutes depending on content size
### Ready
Store is fully processed and available for queries.
**What you can do:**
* Query the store in AI agents
* View individual chunks
* Append or replace content
* Delete the store
### Failed
An error occurred during processing, or the store is partially degraded.
**What to do:**
1. Check the error message in the Store History modal
2. Verify the file format and content
3. Retry the operation
## Error handling
When processing fails, the store will show a warning indicator.
### Error states and recovery
**Cause:** File upload was interrupted or the file format is invalid
**Solution:**
* Verify the file format (must be PDF)
* Check your network connection
* Try uploading again
**Cause:** Error occurred while processing the content
**Solution:**
* Check the Store History for specific error details
* Verify the file is not corrupted
* Contact support if the issue persists
When retrying a failed operation:
* Any chunks already created will be deleted
* The content will be processed entirely from the beginning
* No duplicate chunks will be created
### Warning indicators
When a store has a failed update:
* **Yellow warning icon** appears on the store row
* **Tooltip message**: "Last Store update failed. Check history."
* **Dismiss trigger**: The warning is automatically dismissed after a successful update
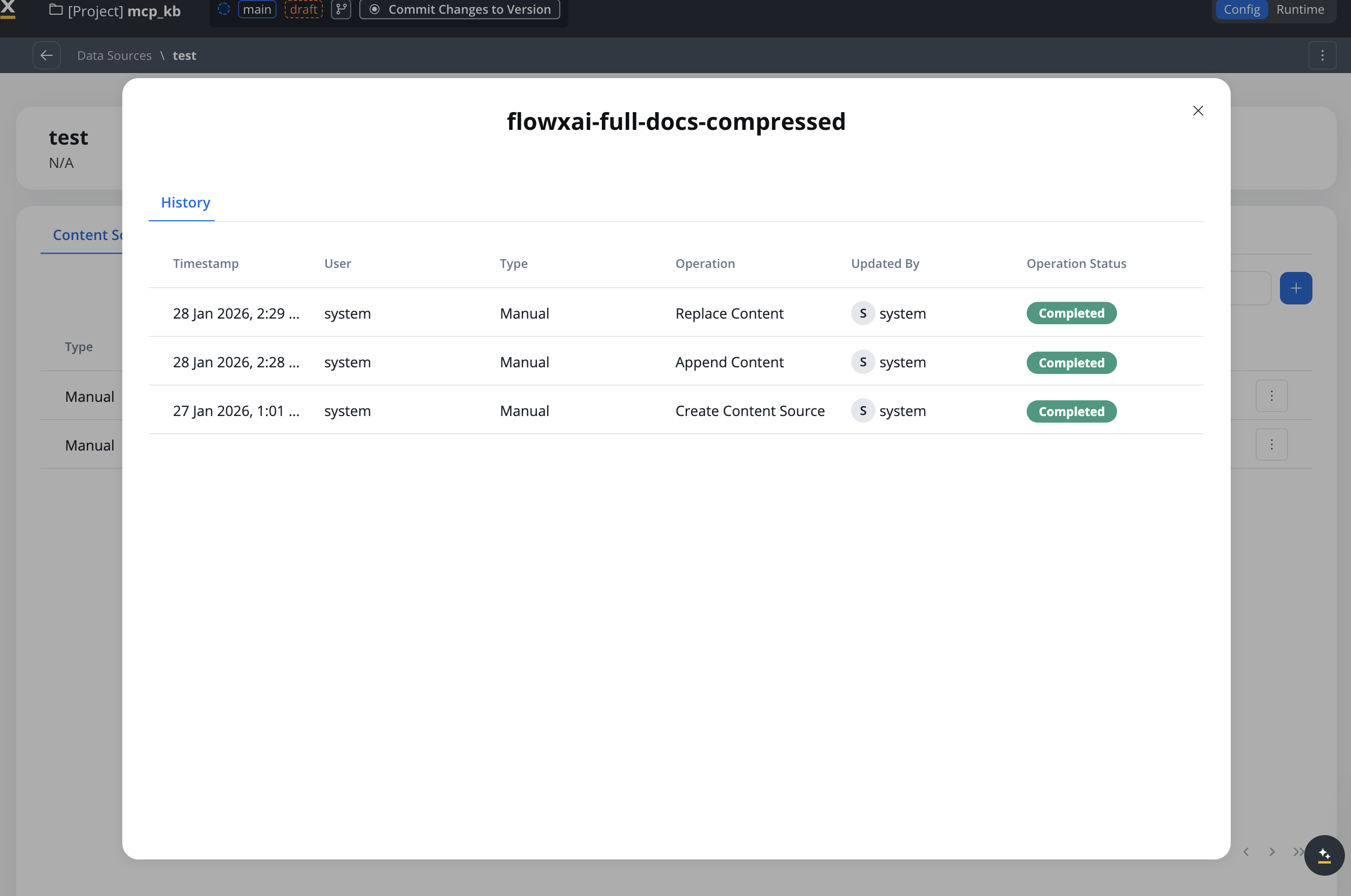
## Viewing store history
Store History is a low-priority feature that may be available in future releases.
Store History will show all operations performed on a store:
| Operation | Description |
| --------------- | ------------------------------------------------ |
| Upload Document | Creates store and inserts content |
| Append Content | Adds new content to existing chunks |
| Replace Content | Deletes existing content and inserts new content |
| Delete Store | Removes the store and all chunks |
Each history entry will include:
* Timestamp
* User or workflow name
* Operation type (Manual/Workflow/Test)
* Operation performed
* View option (for uploaded files or JSON payloads)
## Working with chunks
Chunks are the individual pieces of content that AI agents query. To view and test chunks:
Click the **Chunks** tab in your Knowledge Base
Enter a query to search for relevant chunks
Apply filters to refine the search results
Examine the returned chunks, their relevance scores, and metadata
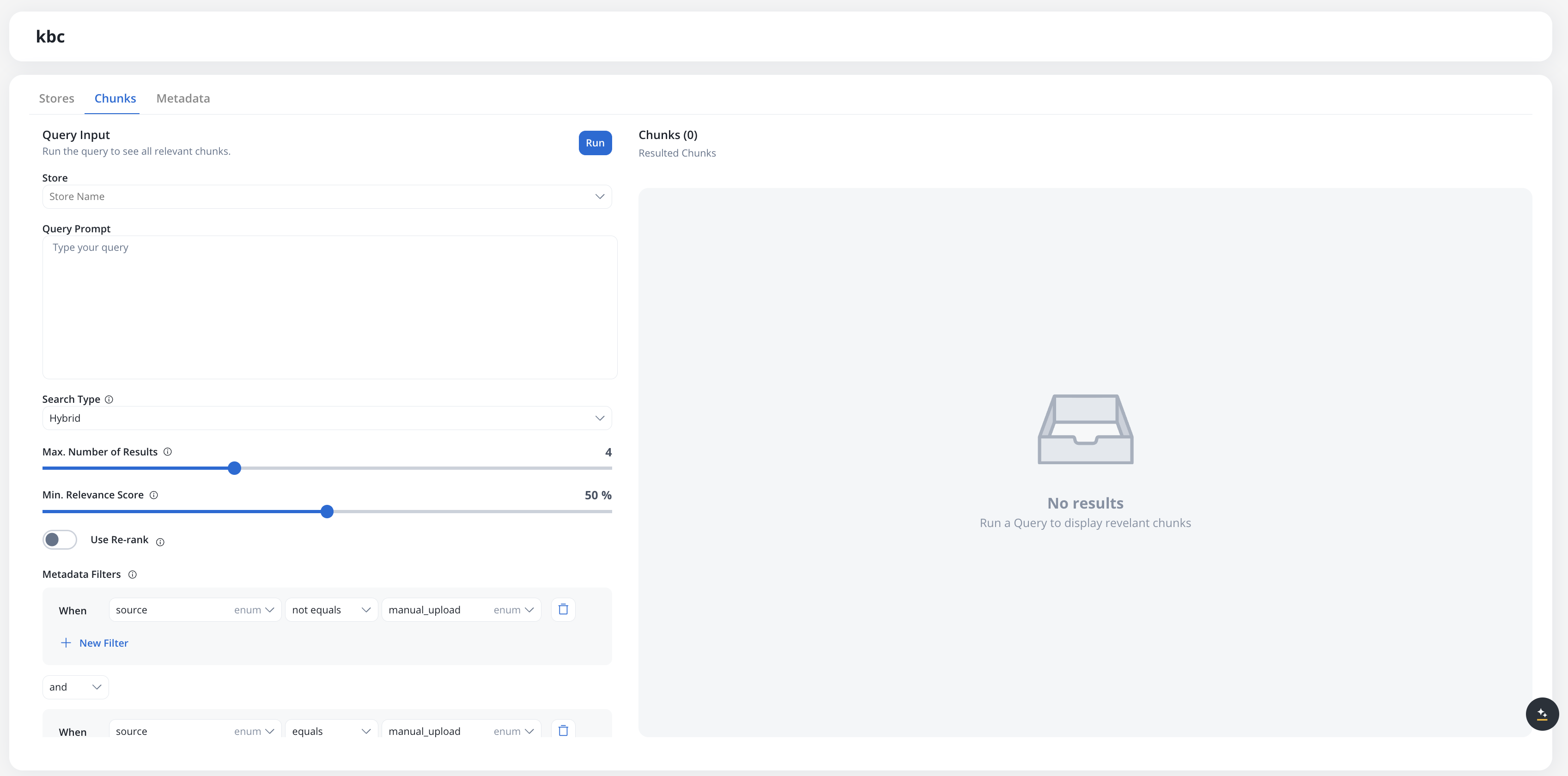
### Chunk information
Each chunk displays:
How relevant the chunk is to your query (0-100%)
The store that generated this chunk (clickable link)
Link to the original document or JSON payload that created this chunk
The actual text content of the chunk
System metadata associated with the chunk:
* `source`: manual\_upload or from\_workflow
* `path`: Document filepath or JSON payload
* `chunk_id`: UUID from the vector database
* `knowledge_base`: Knowledge Base ID
User-defined metadata keys (if configured) are also included.
### User-defined metadata
You can define custom metadata keys on a Knowledge Base and assign values to stores. User-defined metadata enables filtering and scoping when searching chunks — for example, filtering by department, document version, or region.
#### Defining metadata keys
Metadata keys are managed on the **Metadata** tab of the Knowledge Base data source.
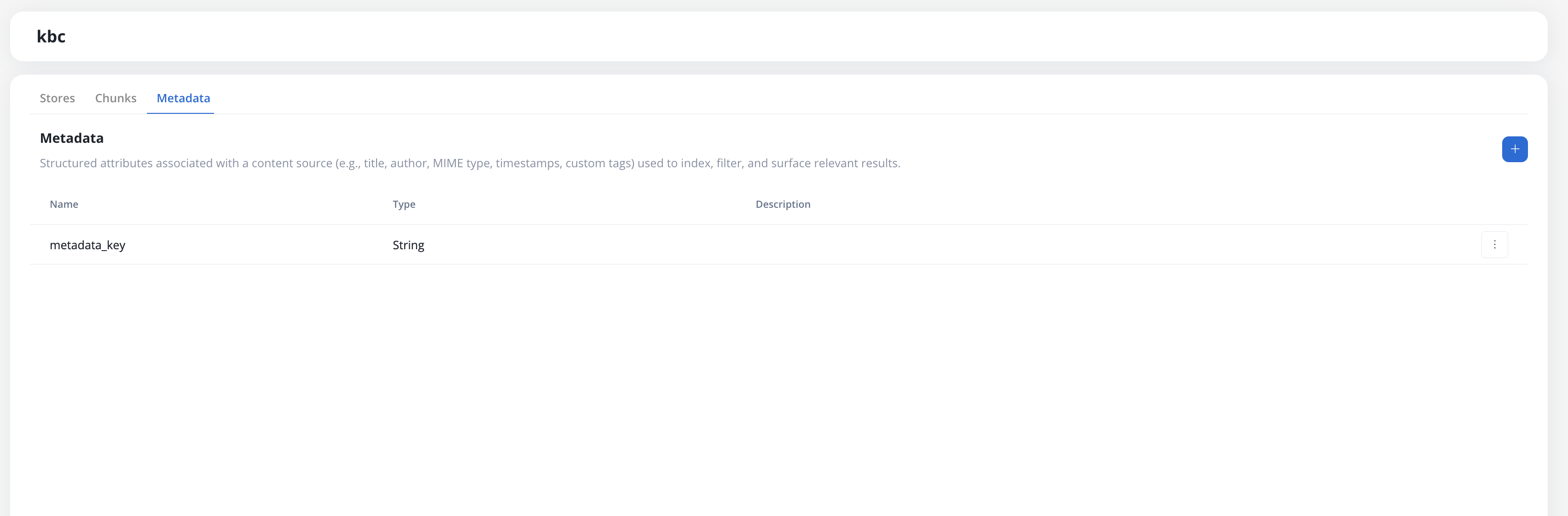
To add a key, click **Add Metadata Key** and fill in the following fields:
| Field | Description |
| --------------- | ---------------------------------------------------------------------------------------------------- |
| **Name** | Unique key name. Cannot be changed after creation. |
| **Type** | Data type: `String`, `Number`, `Boolean`, `Enum`, or `Date`. Cannot be changed after creation. |
| **Enum values** | Allowed values (only visible when **Type** is `Enum`). Values defined at creation cannot be removed. |
| **Description** | Optional free-text description of the key's purpose. |
Name and type are locked after a key is saved. Only description and enum values (additions only) can be updated later.
#### Assigning metadata values
When uploading or appending a store (manually or through the **Update Knowledge Base** workflow node), a **Metadata** section appears in the upload modal listing all defined keys for the Knowledge Base. Assign a value to each relevant key before uploading. The values are stored alongside the content and propagated to the vector database.
#### Filtering by metadata
When searching chunks (in the **Chunks** tab or through the Context Retrieval workflow node), you can add metadata filters using the query builder. System metadata keys are always available as filter options alongside any user-defined keys.
The metadata filter UI is a full query builder with typed operators, AND/OR logic, and grouping.
##### System metadata keys
System metadata keys are reserved names populated automatically by the platform. They are listed in the filter picker with human-readable labels and can be combined with user-defined keys.
| Key | Type | Scope | Description |
| ---------------- | ------ | ----- | ------------------------------------------------------------------------------------------------------ |
| `source` | Enum | Entry | How the entry was added: `manual_upload`, `from_workflow`, `test_operation` |
| `uploaded` | Date | Entry | TODO: description |
| `docName` | String | Entry | TODO: description |
| `docType` | Enum | Entry | TODO: description (starter values include `pdf`, `xlsx`, `docx`, `txt`) |
| `docPages` | Number | Entry | TODO: description |
| `storeOrigin` | String | Entry | TODO: description |
| `chunkCounter` | Number | Chunk | TODO: description |
| `chunkType` | Enum | Chunk | TODO: description (starter values include `table`, `header`, `section_header`, `picture`, `paragraph`) |
| `chunkSection` | String | Chunk | TODO: description |
| `chunkPageStart` | Number | Chunk | TODO: description |
| `chunkEntry` | String | Chunk | TODO: description |
If a user-defined metadata key collides with a reserved system name, it is automatically renamed to `_user` on upgrade. Wire-level identifiers stay plain; the filter picker shows human labels (for example, `Doc type` for `docType`).
Filters are expressed as conditions made of **field / operator / value**. Each condition uses operators appropriate to the metadata key's type:
| Type | Available operators |
| ----------- | ---------------------------------------------------------------------------------------------------------- |
| **String** | equals, not equals, contains, starts with, ends with, matches regex, in, not in, exists, is null |
| **Number** | equals, not equals, greater than, greater or equal, less than, less or equal, between, in, exists, is null |
| **Boolean** | is true, is false, exists |
| **Date** | equals, before, after, between, exists, is null |
| **Enum** | equals, not equals, in, not in, exists |
Conditions are organized in **groups**. Within a group, conditions can be combined with `and` or `or`. Groups themselves are also combined with `and` or `or`, which lets you express non-trivial logic such as `(region = "EU" AND tier IN ["gold", "platinum"]) OR priority >= 5`.
Use **New Filter** to add a condition and **New Group** to add a nested group.
### Searching chunks
Use the **Chunks** tab to test how chunks will be retrieved by AI agents:
Filter by a specific store. Default: all stores
Enter a natural language question or search query
Strategy used for retrieving context:
* **Hybrid** (default) — combines semantic and keyword search
* **Semantic** — vector similarity only
* **Keywords** — lexical match only (hides **Min. Relevance Score**)
Maximum number of chunks to return. Range: 1-10. Default: 4.
Only return chunks with relevance score above this threshold. Range: 0-100%. Hidden when **Search Type** is **Keywords**.
Reorders results to surface the best matches. Improves quality but takes slightly longer.
Refine results using the query builder (see [Filtering by metadata](#filtering-by-metadata))
Use chunk search to understand what information AI agents will receive for different queries. This helps you optimize your Knowledge Base content and structure.
## Best practices
### Content organization
**Organize by topic or version:**
* Create separate stores for different topics
* Use versioning in store names (e.g., "User Guide v1.0", "User Guide v2.0")
* Group related documents in the same store using Append Content
### Content updates
**Choose the right operation:**
* Use **Append Content** when adding supplementary information
* Use **Replace Content** when updating to a new version
* Test queries after updates to verify the changes work as expected
### Error prevention
**Avoid common errors:**
* Ensure PDF files are not corrupted before uploading
* Use unique, descriptive names for stores
* Monitor the status of stores during processing
* Check Store History when errors occur
## Next steps
Learn how to query Knowledge Bases from workflows
## Related resources
Understanding Knowledge Base capabilities