> ## Documentation Index
> Fetch the complete documentation index at: https://docs.flowx.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Context Retrieval
> Query Knowledge Bases and retrieve relevant chunks using RAG search without calling an LLM.
## Overview
The **Context Retrieval** node is a specialized [Integration Designer](/5.9/docs/platform-deep-dive/integrations/integration-designer) workflow node that performs RAG (Retrieval-Augmented Generation) searches against a Knowledge Base. Unlike the [Custom Agent](/5.9/docs/platform-deep-dive/integrations/custom-agent-node) node, Context Retrieval does **not** call an LLM — it retrieves and returns matching chunks directly, giving you full control over how the results are processed downstream.
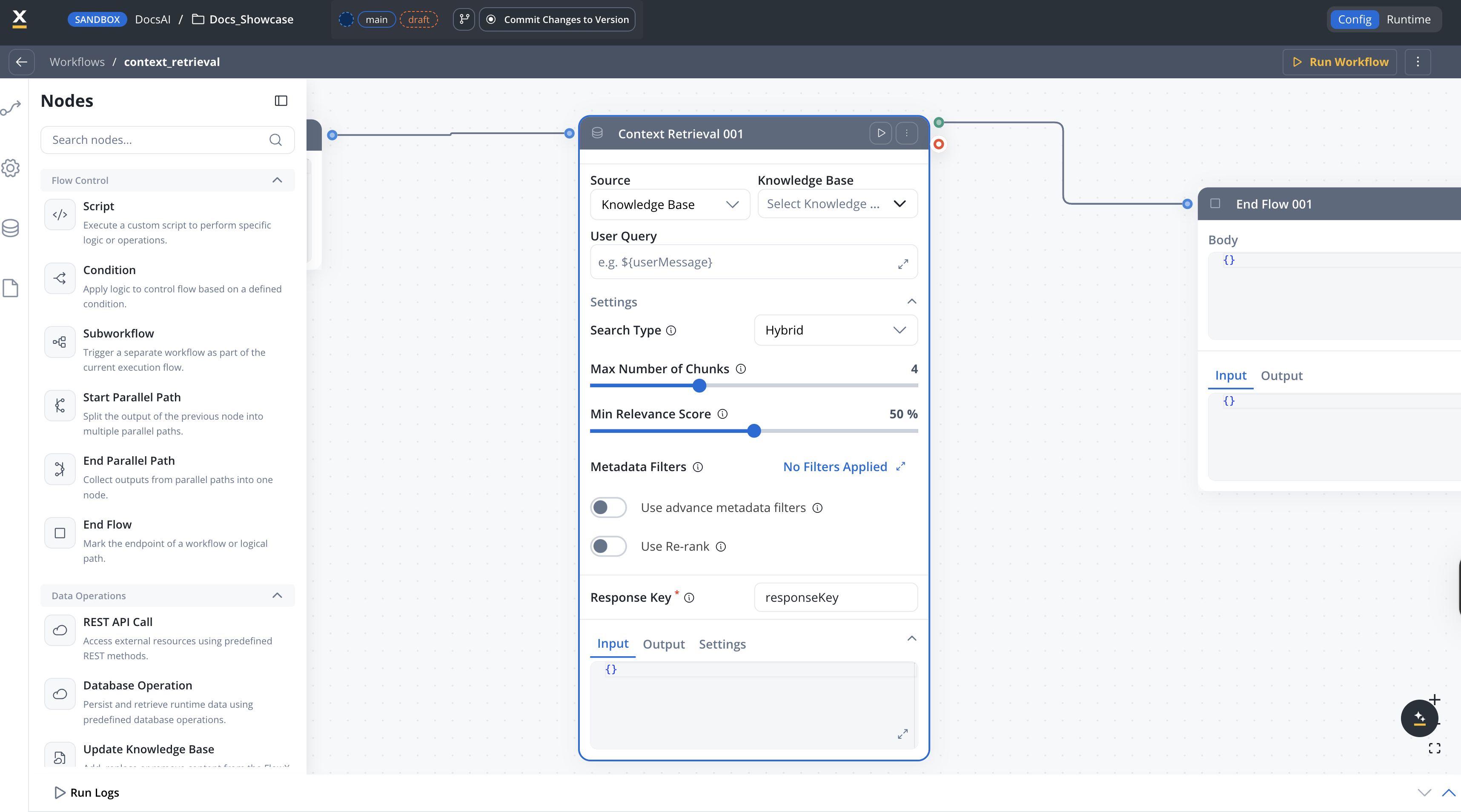
Use Context Retrieval when you want to separate the retrieval step from the generation step. This lets you inspect, filter, or transform retrieved chunks before passing them to an AI node for response generation.
***
## When to use Context Retrieval vs Custom Agent
| Scenario | Recommended node |
| ----------------------------------------------------------------------------- | ----------------------------------------------------- |
| You need the AI to reason about retrieved information and generate a response | **Custom Agent** with Knowledge Base enabled |
| You want raw chunks to process, filter, or route in your workflow | **Context Retrieval** |
| You need to combine chunks from multiple Knowledge Bases | **Context Retrieval** (one per KB) + downstream merge |
| You want a simple question-answer flow with RAG | **Custom Agent** with Knowledge Base enabled |
***
## Configuration
### Knowledge Base
Select one or more Knowledge Base resource references to query.
### Source
The source to query.
**Options:**
* **Knowledge Base** — Search the selected Knowledge Base (default)
* **Memory** — Search [conversation memory](/5.9/ai-platform/conversational-workflows#session-memory)
The **Memory** option is only available in [conversational workflows](/5.9/ai-platform/conversational-workflows).
**Default:** **Knowledge Base**
### Settings
The settings below are available inside the **Settings** expander on the node configuration panel.
#### Search type
The strategy used for retrieving context from the Knowledge Base.
**Options:**
* `Hybrid` — Combines semantic and keyword search for balanced results (default)
* `Semantic` — Uses vector similarity for meaning-based search
* `Keywords` — Uses traditional keyword matching
**Default:** `HYBRID`
When **Keywords** is selected, the **Min Relevance Score** slider is hidden because keyword search does not produce a relevance score.
#### Query parameters
Maximum number of relevant chunks to return. Configurable from 1 to 10.
**Default:** `4`
Minimum relevance score threshold, expressed as a percentage (0–100). Only chunks with a relevance score above this threshold are returned. Not available when search type is set to **Keywords**.
**Default:** `50`
#### Metadata filters
Opens a query builder modal where you compose conditions as **field / operator / value** triples. Operators depend on the metadata key type (equals, not equals, contains, in, not in, before, after, exists, etc.). Conditions can be grouped and combined with **AND** or **OR**.
To filter by store, add a condition on the system metadata key `source`.
Typed operators and AND/OR grouping are supported. See [Filtering by metadata](/5.9/docs/platform-deep-dive/integrations/knowledge-base-integration/managing-content#filtering-by-metadata) for the full operator list.
Toggle to turn on advanced metadata filter expressions for more complex filtering logic. When turned on, a JSON expression field becomes available for defining property-based filters.
**Default:** `false`
#### Re-ranking
When turned on, applies a re-ranking model to the retrieved chunks, reordering them by relevance to the query. This can improve result quality at the cost of slightly higher latency.
**Default:** `false`
***
## User Query
The query text sent to the Knowledge Base. Supports `${}` placeholder syntax for dynamic values from workflow input and configuration parameters.
**Example:**
```
${userMessage}
```
Both runtime input variables and configuration parameters are available for placeholder resolution.
***
## Response Key
Key under which the retrieved chunks are stored in the workflow data, so downstream nodes can reference them.
**Default:** `responseKey`
***
## Output format
The Context Retrieval node returns an array of chunk objects. Each chunk contains:
| Field | Type | Description |
| ------------------ | -------- | ------------------------------------------------------------------------------------------------------------------------------------------------ |
| **chunkContent** | `string` | The text content of the retrieved chunk |
| **chunkMetadata** | `object` | Metadata associated with the chunk (key-value pairs) |
| **relevanceScore** | `number` | Similarity score between the query and the chunk (0–1) |
| **searchType** | `string` | Search strategy that returned this chunk. One of `HYBRID`, `SEMANTIC`, or `KEYWORD`. Only emitted when the RAG service returns a non-null value. |
| **contentSource** | `string` | The name of the store the chunk belongs to (field name preserved for API compatibility) |
### Example output
```json theme={"system"}
[
{
"chunkContent": "The onboarding process requires identity verification...",
"chunkMetadata": {
"source": "onboarding-guide.pdf",
"page": "3"
},
"relevanceScore": 0.92,
"contentSource": "Product Documentation"
},
{
"chunkContent": "KYC checks must be completed within 48 hours...",
"chunkMetadata": {
"source": "compliance-policy.pdf",
"page": "12"
},
"relevanceScore": 0.85,
"contentSource": "Compliance Policies"
}
]
```
***
## Error handling
If the Context Retrieval node fails, the workflow produces a `WORKFLOW_NODE_CONTEXT_RETRIEVAL_ERROR` error. Common causes include:
The referenced Knowledge Base does not exist or is not accessible.
**Solution:** Verify the Knowledge Base exists in your project or dependencies and that you have the required permissions.
The operation prompt resolved to an empty or invalid query.
**Solution:** Check that the `${}` placeholders in your operation prompt reference valid input or config variables.
The RAG search exceeded the configured timeout.
**Solution:** The default timeout is 600 seconds (`flowx.ai-service.nodeRunnerTimeoutSeconds`). Consider simplifying your query or reducing the `topK` value.
***
## Best practices
**Optimizing Context Retrieval:**
* Start with **Hybrid** search type for the best balance of precision and recall
* Use **Semantic** when your queries are natural-language questions; use **Keywords** for exact-match lookups
* The default minimum relevance threshold (50%) is a good starting point — increase it to filter out lower-quality matches
* Turn on **Use Re-Rank** when result quality is more important than latency
* Use metadata filters to narrow results to specific stores (via the `source` key) or metadata values
* Keep **Max Number of Chunks** reasonable (3–10) to avoid overwhelming downstream nodes with too much context
**Building RAG pipelines:**
* Chain Context Retrieval → Script Node → Custom Agent to build custom RAG flows with intermediate processing
* Use the `relevanceScore` field to implement your own relevance filtering logic in a Script node
* Combine results from multiple Context Retrieval nodes (querying different KBs) using a Script node before passing to generation
***
## Related resources
Create and manage Knowledge Bases
Query Knowledge Bases with Custom Agent nodes
AI agents with MCP tools and Knowledge Base access
Build and manage integration workflows